CS61C note1 Number Representation/C Intro
0. 前言
各种各样的原因,大一上学期的进度并没有特别理想,由于是开学而才决定去学CS所以无论在视野还是规划上都稍微有些落后。CS61A和61B都只能说堪堪做了一些(课时看完了,但还差一两个project,主要也是因为精力分给课内的project了),数学上还算进度正常,学校开的数分不难,结合Peter Lax的那本和LADR,线代应该还算过关,寒假有时间把落下的习题写一下。临近期末,这里开个note也是勉励自己寒假的时候尽力学完CS61C和CS231n(EECS 498.008) 可以的话也希望多学一点物理?计划着也是读一些分析力学,张量分析之类的内容
1. 数字表示
1.1 核心模型:模 环
计算机硬件的寄存器和算术单元位宽固定为 bits。因此,所有整数运算本质上都是在一个模 的环上进行的。当最大值 加 1 时,会发生回绕 (Wrap-around) 归零。
1.2 补码的设计
设计目标:使用统一的加法器硬件同时处理加法和减法运算。
数学原理: 在模 系统中,一个数 的加法逆元(即 )是 。 可以将 分解为 。
- 在二进制下表现为 个
1。 - 用全
1序列减去二进制数 ,等价于对 的每一位进行按位取反 (~b)。 - 因此, 的二进制表示即为
~b + 1。
不对称性:
- 表示范围为 。
- 存在一个特殊的数
100...0,即 (TMin)。对该数执行“取反加一”操作,由于溢出会得到其自身 在 C 语言中,abs(INT_MIN)的结果仍然是INT_MIN,这是常见的安全漏洞来源。 。
1.3 二进制与十六进制转换
原理:基于 的幂次关系。
- 二转十六:从最低位(右侧)开始,每 4 位二进制划分为一组,高位不足补 0。将每组直接映射为对应的十六进制数字 (0-F)。
- 十六转二:将每一位十六进制数字直接展开为其对应的 4 位二进制表示。
2. C 语言编译与内存模型
2.1 编译工具链
一个 C 程序从源代码到可执行文件的过程分为四个阶段:
2.1.1 预处理
- 输入:C 源文件 (
.c) - 输出:翻译单元 (
.i) - 行为:纯文本替换。
#include:将头文件内容复制粘贴到当前位置。#define:宏替换,无类型检查。- 删除注释。
2.1.2 编译
- 输入:翻译单元 (
.i) - 输出:汇编代码 (
.s) - 行为:将 C 代码翻译为特定目标架构(如 RISC-V)的汇编指令。此阶段进行语法分析、生成抽象语法树 (AST) 并执行大量优化(如常量折叠、函数内联)。
2.1.3 汇编
- 输入:汇编代码 (
.s) - 输出:可重定位目标文件 (
.o) - 行为:将汇编指令翻译成二进制机器码。生成符号表,记录本文件定义和引用的函数/全局变量。此时外部符号的引用地址未知,会保留重定位条目 可以使用
objdump -d file.o查看目标文件的反汇编代码。 。
2.1.4 链接
- 输入:多个目标文件 (
.o) 和库文件 (.a,.so) - 输出:可执行文件 (
a.out) - 行为:合并所有输入文件的相同段(如
.text,.data)。根据符号表和重定位条目解析符号地址,填补所有未定义的引用。
2.2 结构体与数据对齐
动机:CPU 按字(Word,通常 4 或 8 字节)访问内存效率最高。未对齐访问会导致性能下降或硬件异常。
- 规则 1(成员对齐):结构体中每个成员的偏移量必须是其自身大小的整数倍。
- 规则 2(整体对齐):结构体的总大小必须是其最大成员对齐要求的整数倍。
- 填充:为满足上述规则,编译器会在成员间或末尾插入不使用的字节。
2.3 内存布局
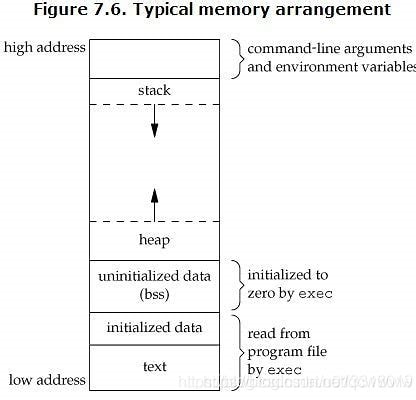
C 程序运行时的虚拟地址空间(从低到高)通常划分为:
- Text: 存放编译后的机器指令,只读。
- Static Data: 存放全局变量和
static变量,生命周期伴随程序全程。 - Heap: 动态分配内存(
malloc),向上增长。 - Stack: 函数调用的局部变量、参数和上下文,向下增长。
2.4 栈帧详解
2.4.1 寄存器
- 定义:CPU 核心内部极少量、高速的存储单元。
- 动机:速度比主存快几个数量级。中间值和常用变量优先存放在寄存器。
- 示例:
int x = 10;li t0, 10: 将立即数10加载到临时寄存器t0。sw t0, -12(s0): 将t0内容存储到栈上为x分配的内存。
2.4.2 栈帧结构
每次函数调用压入一个栈帧,内部从高地址到低地址包含:
- 参数:超过寄存器数量限制的函数参数。
- 返回地址 (RA):函数执行完毕后跳转回的指令地址。
- 保存的寄存器:如
s0-s11,保存调用者的状态以便恢复。 - 局部变量:函数内部定义的变量和数组。
2.4.3 优化案例:寄存器暂存
- 非优化:每次循环对内存进行 Load/Store 操作。
- 优化后:将变量加载到寄存器,循环内仅在寄存器运算,结束后一次性写回内存 这通常能减少 次内存访问,显著提升性能。 。
2.5 应用案例:缓冲区溢出攻击
通过覆盖返回地址 (RA) 劫持程序控制流。
-
漏洞代码:
void vulnerable_func() { char buffer; gets(buffer); // 不检查输入长度 } -
栈布局(前):
... [buffer] [Saved Registers] [RA] ... -
恶意输入:
[Shellcode]...[Padding]...[New RA]New RA指向内存中Shellcode的地址。
-
攻击过程:输入数据越界向上覆盖,将栈上的原始 RA 篡改为 New RA。
-
劫持:函数返回执行
ret指令时,弹出被篡改的地址,跳转执行 Shellcode。
2.6 指针算术与字节序
- 指针算术:
p + n的实际地址是address(p) + n * sizeof(*p)。 - 字节序:
- 小端序 (Little Endian):最低有效字节 (LSB) 存放在低地址。(x86, RISC-V)
- 大端序 (Big Endian):最高有效字节 (MSB) 存放在低地址。(常见于网络协议)
- 注意:解析二进制文件或网络数据包时必须处理字节序转换,否则会导致数据逻辑错误。