MiniMind Reproduction 2026-03-12 · 3 min read
MiniMind 总架构图
总览
本系列笔记记录了从零复刻一个小型语言模型(HollowStoneMind,基于 MiniMind 项目)的全过程。本篇作为系列的第 0 篇,提供整体架构的鸟瞰图和核心设计决策的动机分析。
后续各篇将逐一拆解每个组件的实现细节:
| 篇号 | 组件 | 核心问题 |
|---|---|---|
| 01 | RMSNorm | 为什么不用 LayerNorm?归一化如何稳定深层训练? |
| 02 | RoPE & YaRN | 如何让 attention 感知相对位置?长上下文如何扩展? |
| 03 | GQA | KV cache 为什么贵?如何在表达力和内存间折中? |
| 04 | FFN (SwiGLU) | 门控 FFN 比普通 MLP 好在哪里? |
| 05 | 完整 Model | 从 token id 到 hidden state 的端到端数据流 |
Dense Model 架构
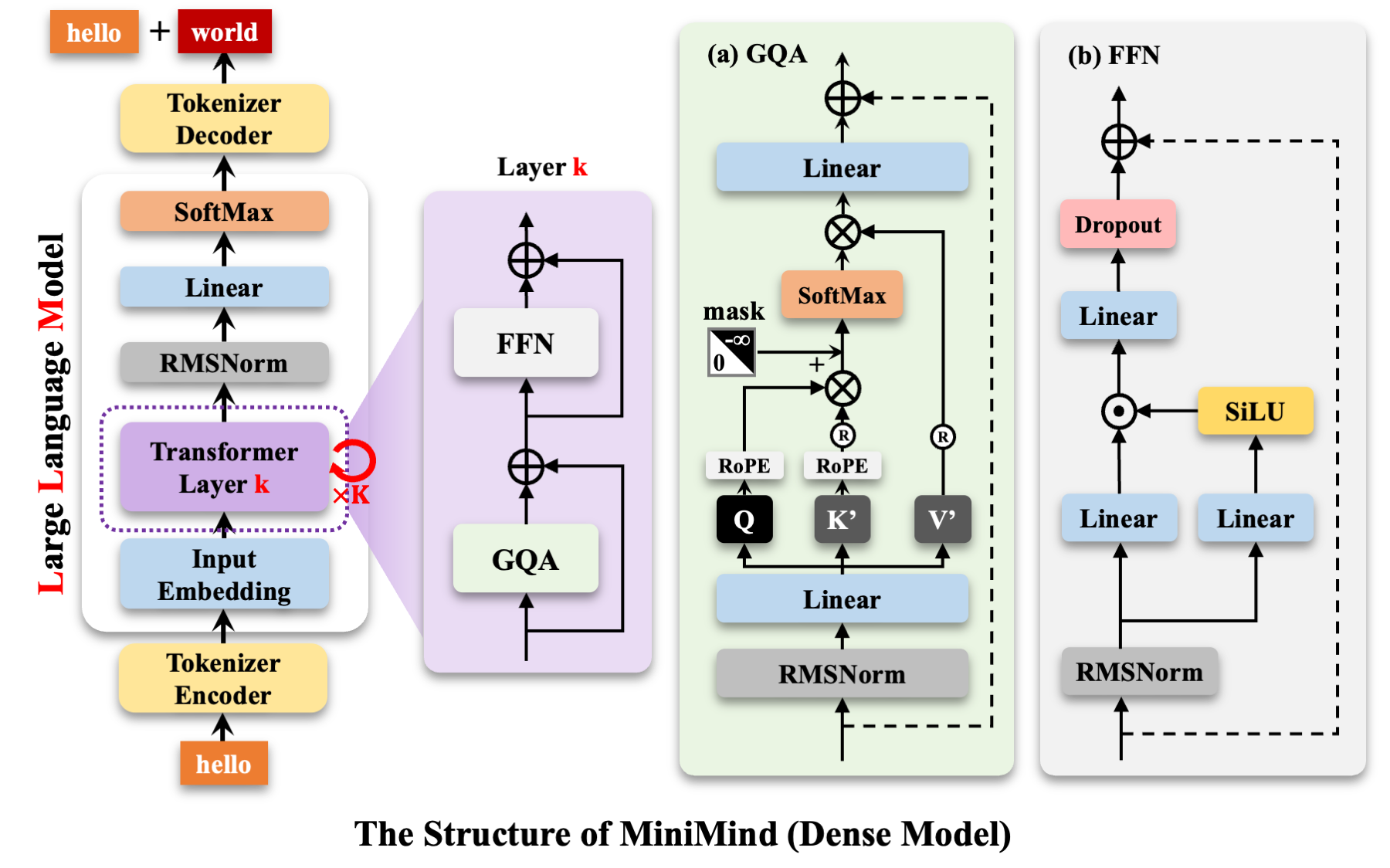
Dense 模型是标准的 decoder-only Transformer,每一层(MindBlock)由两个子模块组成:
这是 Pre-Norm 残差结构,与 GPT-2 的 Post-Norm 不同。Pre-Norm 的核心优势在于:归一化发生在子层之前,使得残差主干上的梯度流更加畅通,训练更加稳定。
默认配置参数:
| 参数 | 值 | 说明 |
|---|---|---|
hidden_size | 512 | 隐藏层维度 |
num_hidden_layers | 8 | Transformer 层数 |
num_attention_heads | 8 | Query 头数 |
num_key_value_heads | 2 | KV 头数(GQA) |
intermediate_size | ~1365 | FFN 中间层维度() |
vocab_size | 6400 | 词表大小 |
max_position_embeddings | 32768 | 最大位置长度(RoPE + YaRN) |
整个 Dense 模型的单次 forward 可以概括为:
token_ids [B, S]
→ Embedding [B, S, 512]
→ 8 × MindBlock [B, S, 512]
→ Final RMSNorm [B, S, 512]
→ (lm_head → logits [B, S, vocab])MoE Model 架构
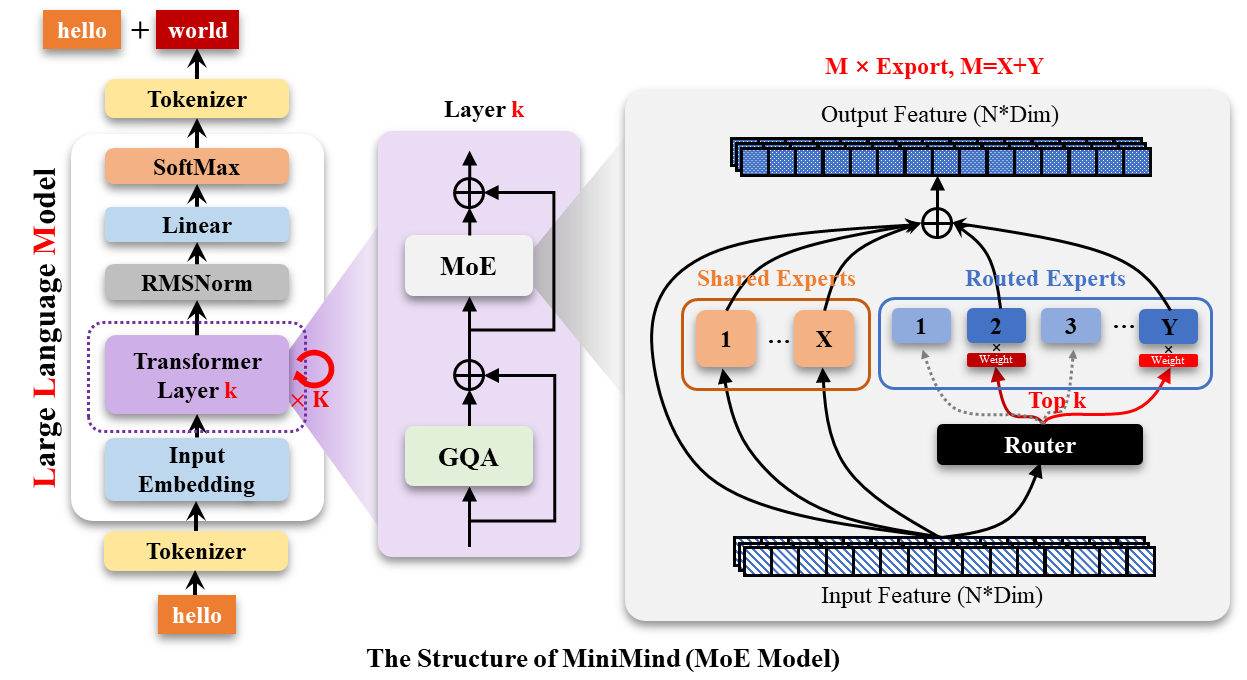
MoE(Mixture of Experts)变体将 Dense 模型中的单个 FFN 替换为多个并行专家 + 路由器结构。每个 token 不再经过同一个 FFN,而是由路由器根据输入动态选择若干个专家来处理。
其中 是路由器输出的门控权重(softmax 后取 Top-K)。
MoE 的核心权衡:
- 参数效率:总参数量增大(多个专家),但每个 token 只激活少数专家,因此实际 FLOPs 接近单专家
- 容量扩展:在不显著增加推理计算量的前提下,增大模型的知识容量
- 工程复杂度:路由器的负载均衡(load balancing)、专家并行(expert parallelism)等问题需要额外处理
设计决策总结
本项目的架构选择遵循”LLaMA 范式”——2023 年以来被 LLaMA、Mistral、Qwen、DeepSeek 等模型验证的事实标准组合:
| 决策 | 选择 | 动机 |
|---|---|---|
| 归一化 | RMSNorm | 比 LayerNorm 更轻量,不减均值,对残差流干预更小 |
| 归一化位置 | Pre-Norm | 梯度流更稳定,深层训练更可靠 |
| 位置编码 | RoPE | 内积自然依赖相对位置,比学习式编码更易外推 |
| 长上下文 | YaRN | 按频率分层缩放,保护短程分辨率 |
| 注意力 | GQA | 在表达力和 KV cache 成本之间取平衡 |
| FFN | SwiGLU 门控 | 比 ReLU MLP 更有选择性,表达更精细 |
| 偏置项 | 无 | 减少参数,实验上对性能影响极小 |
这些选择并非独立做出的——它们构成一个相互配合的系统。例如:Pre-Norm 使得 RMSNorm 的”轻约束”足够用(不需要 LayerNorm 的”强矫正”),RoPE 的旋转结构与无偏置设计天然兼容,GQA 的 cache 节省使得 YaRN 的长上下文扩展在实际部署中成为可能。
参考
- MiniMind 项目:github.com/jingyaogong/minimind
- Touvron, H. et al. “LLaMA: Open and Efficient Foundation Language Models.” arXiv:2302.13971, 2023.
- Jiang, A. Q. et al. “Mistral 7B.” arXiv:2310.06825, 2023.
- Fedus, W., Zoph, B., & Shazeer, N. “Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity.” JMLR, 2022. — MoE 架构的重要参考
END
Series: MiniMind Reproduction
- 1. MiniMind 总架构图
- 2. MiniMind 01: RMSNorm
- 3. MiniMind 02: RoPE & YaRN
- 4. MiniMind 03: GQA
- 5. MiniMind 04: FFN
- 6. MiniMind 05: 拼装 Model