CS 285: Deep Reinforcement Learning — 第18讲 详细讲义

课程标题与概述
概念详解
本讲是 CS 285 课程的第18讲,主题为"离线强化学习算法"(Offline RL Algorithms)。在上一讲(第17讲)中,Sergey Levine 教授介绍了离线强化学习的基本概念——即从一个固定的、预先收集的数据集中学习最优策略,而不再与环境进行交互。上一讲重点讨论了为什么离线RL是困难的:核心问题在于分布偏移(distributional shift)——训练分布(数据集中的状态-动作对)与测试分布(学到的策略实际访问的状态-动作对)之间的不匹配,导致Q函数对分布外(Out-Of-Distribution, OOD)动作的过度估计,进而引发灾难性的策略退化。
本讲在此基础上,系统地展开离线RL的算法工具箱。Levine 教授将带领我们遍历五大类方法:(1) 策略约束方法(Policy Constraints)——显式或隐式地限制学到的策略不要偏离行为策略太远;(2) 隐式Q学习(Implicit Q-Learning, IQL)——通过巧妙的损失函数设计,完全避免在Q更新中评估OOD动作;(3) 保守Q学习(Conservative Q-Learning, CQL)——主动压低OOD动作的Q值,使学到的策略"悲观"地看待未知区域;(4) 离线到在线RL(Offline-to-Online RL)——如何将离线预训练的策略平滑过渡到在线微调;(5) 基于模型的离线RL(Model-Based Offline RL)——学习环境模型并在规划中纳入不确定性惩罚。这些方法虽然形式各异,但共享一个核心原则:以某种方式修复分布偏移问题。
深度剖析
本讲的定位非常关键:它处于离线RL理论(第17讲)与具体应用之间的桥梁位置。第17讲建立了"为什么需要离线RL"以及"分布偏移为何是根本挑战"的理论基础;本讲则回答"有哪些经过验证的算法解决方案"。值得注意的是,离线RL是一个相对年轻的领域——本讲涉及的多数论文发表于 2019-2021 年间(BRAC 2019, CQL 2020, IQL 2021, COMBO 2021),这意味着该领域在短短两三年内出现了爆发式的算法创新。Levine 教授的实验室(UC Berkeley RAIL)在这一波创新中扮演了核心角色——CQL、IQL、AWAC、MOPO、COMBO 等工作均出自其研究组。
从教学设计的角度看,本讲的五部分结构遵循了从"简单直接"到"复杂精细"的递进逻辑:策略约束是最直观的想法("不要让策略跑太远"),但实现起来有诸多工程细节;IQL 和 CQL 代表了两种更优雅的数学方案——前者通过期望回归(expectile regression)巧妙地绕开OOD问题,后者通过显式的保守正则化项压制OOD动作的Q值;离线到在线RL 则是将离线RL嵌入到更完整的工业级流程中——先离线预训练,再在线微调,这是实际部署中最常见的范式;最后,基于模型的方法打开了另一条路径——通过学习环境动力学模型来实现"反事实推理",但其挑战在于模型误差在OOD区域的放大效应。
实例与类比
可以将离线RL的各类算法类比为不同风格的"保守投资策略"。策略约束方法相当于"只投资你熟悉的行业"——显式地画一个圈,不越界;IQL 相当于"只从历史数据中推断最佳做法,不做外推"——完全在已知数据中寻找最优;CQL 相当于"对不熟悉的投资标的,系统性地低估其预期收益"——保持悲观以避免踩雷;离线到在线RL 相当于"先用历史数据做纸上交易训练,再小仓位实盘验证";基于模型的方法相当于"先建立一个市场模拟器,但在模拟结果上加上安全边际"。
关键要点
- 本讲系统性地覆盖了离线RL的五大算法家族,代表了 2019-2021 年间该领域的核心进展
- 所有方法的共同目标是修复分布偏移问题——但实现路径各不相同
- 多数工作出自 UC Berkeley RAIL 实验室,体现了该组在离线RL领域的主导地位
- 本讲的递进结构从直观(策略约束)到数学优雅(IQL/CQL)再到工业实践(离线到在线)
→ Levine 教授先以一张总览图开篇,提炼出贯穿所有离线RL算法的核心设计原则。

离线RL的核心设计原则
概念详解
这张幻灯片提炼了离线RL算法的三条核心设计原则,Levine 教授认为尽管文献中有许多看似不同的方法,但真正有效的算法都遵循这些相似的原则:
原则一:使用基于价值的方法(Use value-based methods)——具体来说,使用 Q-learning 或 Q-function actor-critic 架构。为什么基于价值的方法在离线场景中更受青睐?因为策略梯度方法(如 REINFORCE、PPO)需要在线采样来估计策略梯度 $\nabla_\theta J(\theta) = \mathbb{E}_{\tau \sim \pi_\theta}[\nabla_\theta \log \pi_\theta(\tau) \hat{R}(\tau)]$,而这个期望是在当前策略的轨迹分布下取的——在离线设定中,我们无法从当前策略采样。Q-learning 则不同:它的更新目标只需要从数据集中采样 $(s, a, r, s')$ 元组,然后通过 Bellman 备份来改进价值估计。这使得 Q-learning 天然更适合离线场景。
原则二:以某种方式修复分布偏移问题(Somehow fix the distributional shift problem)——这是离线RL最核心的挑战。具体手段包括:悲观主义(pessimism),如 CQL 通过压低 OOD 动作的 Q 值来实现悲观估计;策略约束(policy constraints),限制策略不偏离行为策略太远;以及避免在更新中使用 OOD 动作,如 IQL 的设计。
原则三:训练 Q 函数使其不过度估计(Train the Q-function so that it doesn't overestimate)——这是对原则二的精炼。在在线RL中,过度估计可以通过环境交互来纠正(错误的 Q 值会导致智能体去探索那些区域,从而收集纠正性数据);但在离线RL中,没有这种自我纠正机制,过度估计会不断自我放大。
深度剖析
这三条原则形成了一个完整的逻辑闭环:(1) 选择正确的算法框架(基于价值的方法);(2) 在这个框架中识别并解决核心问题(分布偏移);(3) 通过具体的训练目标设计来实现这一解决(压制过度估计)。我们可以从信息论的角度来理解这一逻辑:在线RL中,策略可以通过与环境交互不断获取新的互信息(mutual information)$I(s; a_{new})$——每次探索都在减少不确定性。而在离线RL中,这个信息通道被切断了——数据集 $\mathcal{D} = \{(s_i, a_i, r_i, s'_i)\}$ 包含的信息量是固定的。因此,算法必须在"已知已知"的区域内谨慎行事,任何对未知区域的乐观外推都可能导致灾难。
具体的技术手段映射到原则上:
- 悲观主义(Pessimism, e.g., CQL):在目标函数中显式添加惩罚项,压低那些在数据集中不常见的动作的 Q 值。形式上,标准 Q-learning 最小化 $\mathbb{E}_{(s,a)\sim\mathcal{D}}[(Q(s,a) - \mathcal{B}^*Q(s,a))^2]$;而 CQL 额外最小化 $\mathbb{E}_{s\sim\mathcal{D}, a\sim\pi}[Q(s,a)]$(压低策略动作的 Q 值),同时最大化 $\mathbb{E}_{(s,a)\sim\mathcal{D}}[Q(s,a)]$(保持数据内动作的 Q 值)。
- 策略约束(Policy constraints):限制策略分布 $\pi(a|s)$ 与行为策略分布 $\pi_\beta(a|s)$ 之间的距离。常用约束包括 KL 散度 $D_{KL}(\pi \| \pi_\beta)$(reverse KL,mode-seeking)或 $D_{KL}(\pi_\beta \| \pi)$(forward KL,mode-covering)。
- 避免 OOD 动作(Avoid OOD actions, e.g., IQL):根本不在 Q 更新中查询 OOD 动作的 Q 值,通过隐式的策略提升来实现——这正是 IQL 的精妙之处。
实例与类比
想象你是一家对冲基金的分析师,只能基于历史交易数据(离线数据集)来制定投资策略。原则一告诉你:应该使用基于"估值"的方法(类比 Q-learning),而不是基于"试错"的方法(类比策略梯度)——因为你不能在真实市场中随意试验。原则二提醒你:历史数据中的交易模式可能与未来的市场状况不同(分布偏移),你必须考虑这种不匹配。原则三给出了具体做法:对于历史数据中不常见的投资组合,应该系统性地低估其预期收益(悲观主义)——宁可错过一些好机会,也比错误地高估风险资产要安全。
关键要点
- 离线RL的三条核心原则:(1) 使用基于价值的方法;(2) 修复分布偏移;(3) 训练Q函数不过度估计
- 这些原则之间相互关联:基于价值的框架提供了基础,避免过度估计是修复分布偏移的具体手段
- 三种主要技术路线:悲观主义(压低OOD动作Q值)、策略约束(限制策略偏离)、避免OOD动作(不在更新中评估OOD动作)
- 在线RL中过度估计可以自我纠正,离线RL中没有这个安全网
→ 有了这些原则作为指南,我们首先进入第一部分:策略约束方法(Policy Constraints)的深入讨论。这是上一讲的延续,我们将看到具体的实现方案。
第1章:策略约束方法(续)— Policy Constraints Continued

第一部分引言
概念详解
从上一讲(第17讲)的结尾,我们已经引入了策略约束的基本概念——通过在策略优化目标中添加与行为策略的距离惩罚项,来限制学到的策略不会偏离数据支持的区域太远。上一讲讨论了"为什么需要策略约束"(分布偏移导致的 Q 值过度估计)以及两种 KL 散度的基本性质(Forward KL 的模式覆盖 vs Reverse KL 的模式寻求)。本讲的第一部分在此基础上,深入探讨策略约束的具体实现方式。
策略约束的核心问题是:如何在 Actor-Critic 框架中高效且正确地施加行为策略约束?这里有两个维度的设计选择:(1) 约束施加在哪里?——可以直接修改 Actor 的目标函数(在策略梯度中添加惩罚项),也可以修改奖励函数(在环境奖励上叠加行为偏离惩罚);(2) 约束是显式还是隐式?——显式约束需要估计行为策略 $\pi_\beta$ 并直接计算分布间距离(如 KL 散度),隐式约束则通过对优势加权的最大似然估计来隐式地保持策略接近数据分布。
深度剖析
这里的"显式"(explicit)与"隐式"(implicit)之分,在数学上有非常不同的含义。显式约束方法直接优化形如以下的目标:
$$\max_\pi \mathbb{E}_{s\sim\mathcal{D}, a\sim\pi(\cdot|s)}[Q(s,a)] - \alpha D(\pi(\cdot|s) \| \pi_\beta(\cdot|s))$$
其中 $D(\cdot\|\cdot)$ 是某种散度度量(通常为 KL 散度),$\pi_\beta$ 是需要额外估计的行为策略。这个公式非常直观,但也带来了额外的工程挑战:如何准确估计 $\pi_\beta$?散度 $D$ 如何高效计算?权重 $\alpha$ 如何选取?
隐式约束方法则走了一条更聪明的路。它们不显式计算分布间距离,而是通过加权最大似然的方式自然达成约束效果。其核心观察是:在最大熵RL框架下,最优策略可以表达为 $\pi^*(a|s) \propto \pi_\beta(a|s) \exp(Q(s,a)/\alpha)$。这个形式直接暗示了一个简单的算法——用 $Q$ 值的指数作为权重,对行为数据进行加权最大似然估计。这种方法不需要显式估计 $\pi_\beta$ 的分布参数,实现更加简洁。我们将分别在 Slides 5-8(显式方法)和 Slides 9-10(隐式方法)中展开讨论。
实例与类比
显式约束好比在训练时给策略画一道明确的"红线"——"你离行为策略的距离不能超过 $\epsilon$"。这需要你精确测量当前位置到红线的距离(估计 $\pi_\beta$ 并计算散度)。隐式约束则好比设定一个"引力场"——行为数据中的动作被赋予更高的采样权重,策略自然地被拉向数据密集的区域,不需要显式地画红线。两种方法各有优劣:显式约束更可控但工程更复杂,隐式约束更简洁但对 $Q$ 值的质量更敏感。
关键要点
- 策略约束有两个设计维度:施加位置(Actor目标 vs 奖励函数)和约束类型(显式 vs 隐式)
- 显式约束需要估计行为策略 $\pi_\beta$ 并计算散度 $D(\pi \| \pi_\beta)$
- 隐式约束通过优势加权最大似然实现,无需显式距离计算
- 最大熵RL框架下的最优策略形式为 $\pi^*(a|s) \propto \pi_\beta(a|s) \exp(Q(s,a)/\alpha)$,这是隐式方法的核心依据
→ 我们先回顾上一讲中关于策略约束的关键图示——Forward KL 与 Reverse KL 的不同行为。
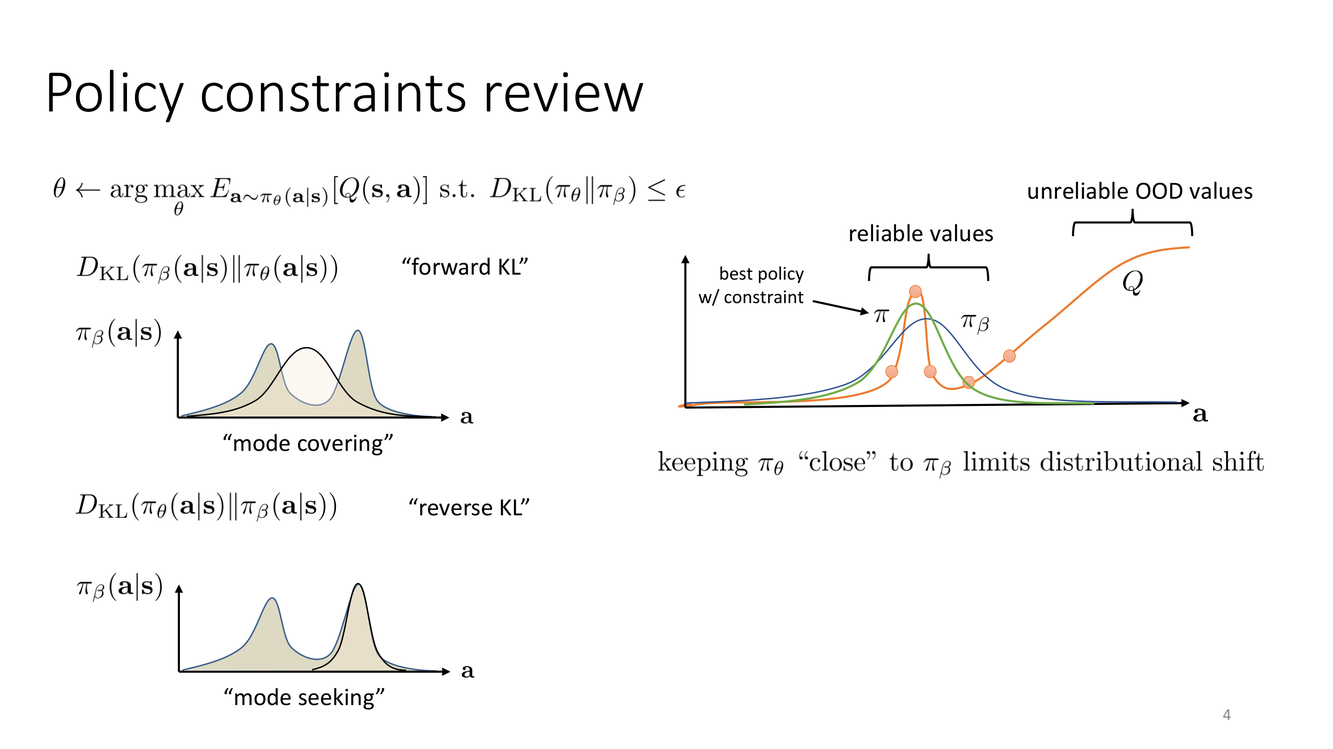
策略约束回顾:KL散度的两种方向
概念详解
这张幻灯片回顾了策略约束中的关键设计选择——KL 散度的方向。给定行为策略分布 $\pi_\beta(\cdot|s)$ 和当前学到的策略 $\pi_\theta(\cdot|s)$,我们可以定义两种 KL 散度:
Forward KL(前向KL散度):$D_{KL}(\pi_\beta \| \pi_\theta) = \mathbb{E}_{a\sim\pi_\beta}\left[\log \frac{\pi_\beta(a|s)}{\pi_\theta(a|s)}\right]$
也被称为"模式覆盖"(mode-covering)。Forward KL 在 $\pi_\beta$ 有概率质量而 $\pi_\theta$ 没有的地方惩罚极重(因为 $\log(1/\pi_\theta)$ 趋向无穷大),这意味着它迫使 $\pi_\theta$ 在所有 $\pi_\beta$ 有支持的地方都分配概率——即"覆盖"行为策略的所有模式。但这也会导致策略在数据稀少的区域也分配非零概率。
Reverse KL(反向KL散度):$D_{KL}(\pi_\theta \| \pi_\beta) = \mathbb{E}_{a\sim\pi_\theta}\left[\log \frac{\pi_\theta(a|s)}{\pi_\beta(a|s)}\right]$
也被称为"模式寻求"(mode-seeking)。Reverse KL 在 $\pi_\theta$ 有概率而 $\pi_\beta$ 没有的地方惩罚重,因此它迫使 $\pi_\theta$ 只在 $\pi_\beta$ 有足够密度的区域放置概率——即"寻求"行为策略的模式,同时在 $\pi_\beta$ 概率低的地方可以"舍弃"概率质量。
深度剖析
两种 KL 散度在离线RL中的适用场景有本质差异。Forward KL 的"模式覆盖"特性意味着策略被迫在所有数据覆盖的区域都保持一定概率——这在数学上保证了 $\pi_\theta$ 的支持集被包含在 $\pi_\beta$ 的支持集中,从而理论上完全排除了 OOD 动作。然而,这种覆盖是有代价的:Forward KL 迫使策略在所有行为模式上平均分配概率,导致策略不够"专注"——如果行为数据中包含了次优动作,Forward KL 约束的策略也会为这些次优动作保留概率。
Reverse KL 的"模式寻求"特性则允许策略选择性地聚焦于行为分布中的某些模式(通常是高 Q 值的模式)。在 Gaussian 策略的典型设定下,Reverse KL 有闭式解,使得梯度计算非常高效。但它的风险在于:如果在 Q 函数过度估计了某个区域的 Q 值,而这个区域恰好在数据分布中有一些(但不充分的)支持,Reverse KL 约束可能不足以阻止策略向这个区域过度集中。
从优化角度看,使用 Lagrange 乘子法,约束问题 $\max_\pi \mathbb{E}[Q] \text{ s.t. } D(\pi\|\pi_\beta) \leq \epsilon$ 等价于无约束目标 $\max_\pi \mathbb{E}[Q] - \lambda D(\pi\|\pi_\beta)$。不同的散度 $D$ 会产生不同几何性质的最优解。Reverse KL 倾向于产生"尖锐"的最优分布(集中在少数高Q值模式上),而 Forward KL 倾向于"平滑"的分布。
实例与类比
假设行为策略在某个状态下有3个动作簇:簇A(高奖励,占数据40%)、簇B(中等奖励,占数据35%)、簇C(低奖励,占数据25%)。Forward KL 约束下的策略会保留所有三个簇的概率——"不放过任何一个数据中出现的动作模式",最终策略的期望奖励是三个簇的加权平均。Reverse KL 约束下的策略则倾向于把概率集中到簇A——"选最好的那个模式并专注于此",但同时它可能完全忽略簇B和C。在离线RL中,通常Reverse KL更受欢迎,因为它允许策略在数据支持的范围内进行优化选择,而非简单模仿行为分布。
关键要点
- Forward KL ($D_{KL}(\pi_\beta\|\pi)$):模式覆盖,保证支持集包含,但策略不够专注
- Reverse KL ($D_{KL}(\pi\|\pi_\beta)$):模式寻求,允许选择性聚焦高Q值区域,离线RL中更常用
- 约束目标 $\max \mathbb{E}[Q] - \lambda D$ 中散度选择决定了最优解的几何性质
- Gaussian 策略下 Reverse KL 有闭式解,计算高效——这是其流行的工程原因之一
→ 有了 KL 散度的概念基础,我们可以考察两种显式的策略约束实现方案:修改 Actor 目标和修改奖励函数。

显式策略约束(一):修改Actor目标函数
概念详解
第一种实现策略约束的直接方式是修改 Actor(策略网络)的优化目标。标准 Actor-Critic 中,Actor 的目标是最大化期望 Q 值:$\max_\pi \mathbb{E}_{s\sim\mathcal{D}, a\sim\pi(\cdot|s)}[Q(s,a)]$。策略约束版本在此基础之上添加与行为策略的距离惩罚:
$$\max_\pi \mathbb{E}_{s\sim\mathcal{D}, a\sim\pi(\cdot|s)}[Q(s,a)] - \lambda D(\pi(\cdot|s) \| \pi_\beta(\cdot|s))$$
这个方案有两个子变体:
方案 1a(Lagrange 乘子法):将约束写为 $\max_\pi \mathbb{E}[Q] \text{ s.t. } D(\pi\|\pi_\beta) \leq \epsilon$,然后用 Lagrange 乘子 $\lambda$ 转化为无约束问题。$\lambda$ 通过 primal-dual 梯度上升自动调节:当散度超过阈值 $\epsilon$ 时增大 $\lambda$(收紧约束),当散度远小于阈值时减小 $\lambda$(放松约束)。
方案 1b(BC 类方法):在 Actor 的损失函数中直接添加行为克隆(Behavior Cloning, BC)项,即最大化 $\mathbb{E}_{(s,a)\sim\mathcal{D}}[\log \pi_\theta(a|s)]$。这类方法有时被称为 [method]+BC,例如 DDPG+BC、TD3+BC、SAC+BC。虽然通常不是解决离线RL问题的最优方案,但如果调参得当,这类简单方法出人意料地有效。
深度剖析
方案 1a(Lagrange 乘子法)的数学框架值得深入理解。Primal-dual 优化的交替过程如下:先在固定 $\lambda$ 下最大化 $\mathbb{E}[Q] - \lambda D(\pi\|\pi_\beta)$(primal 更新),然后在固定 $\pi$ 下沿 $\nabla_\lambda (D - \epsilon)$ 的方向更新 $\lambda$(dual 更新)。对于 Gaussian 策略和 Reverse KL 约束,primal 更新有解析梯度:
$$\nabla_\theta \mathbb{E}_{a\sim\pi_\theta}[Q(s,a)] \approx \mathbb{E}_{\xi\sim\mathcal{N}(0,I)}[\nabla_\theta \mu_\theta(s) + \nabla_\theta \sigma_\theta(s) \cdot \xi \cdot Q(s, \mu_\theta(s) + \sigma_\theta(s)\xi)]$$
加上 Reverse KL 惩罚 $\nabla_\theta D_{KL}(\pi_\theta \| \pi_\beta)$ 后,总的梯度是 Q 值提升方向与"拉回行为分布"方向之间的平衡。$\lambda$ 的动态调节机制是关键的工程细节——它避免了手动调参的繁琐,但也引入了额外的超参数(初始 $\lambda$、学习率、约束阈值 $\epsilon$)。
方案 1b(BC 类方法)看似粗糙,但在实践中常常意外地有效。其原理可以理解为:BC 项 $\mathbb{E}_{(s,a)\sim\mathcal{D}}[\log \pi(a|s)]$ 实际上是 Forward KL $D_{KL}(\pi_\beta \| \pi)$ 的负值(在忽略熵项的情况下)。因此 BC+RL 的组合相当于同时优化"模仿数据"(BC)和"提升Q值",本质上也是一种策略约束。Levine 教授特别强调"generally not the best way to fix the problem, but can work well if done right"——这句话揭示了离线RL中一个反复出现的主题:简单方法在精心调参后常常能匹敌复杂方法的性能。
实例与类比
方案 1a 可以类比为开车时设定了电子围栏(geofence)——你可以在围栏内自由驾驶(最大化 Q 值),但一旦接近边界,系统会自动施加更强的回拉力(增大 $\lambda$)。方案 1b 则像是教练坐在副驾驶座上,同时给你两个指令:"尽量开快"(Q 最大化)和"尽量跟着我的示范开"(BC)。最终你的驾驶风格是这两个指令的折中。在实践中,TD3+BC(Fujimoto & Gu, 2021)在 D4RL 基准上取得了非常竞争力的结果,证明了 BC 类方法的实用性。
关键要点
- 修改 Actor 目标是最直接的策略约束实现方式
- 方案 1a:Lagrange 乘子法,通过 $\max_\pi \mathbb{E}[Q] - \lambda D(\pi\|\pi_\beta)$ 实现自适应约束
- 方案 1b:添加 BC 项 $\mathbb{E}[\log \pi]$,等价于 Forward KL 约束,简单但有效
- Gaussian 策略下 Reverse KL 有闭式梯度,Lagrange 乘子需要额外的 dual 更新
- "[method]+BC" 在精心调参下可以有很强竞争力
→ 除了修改 Actor 目标,另一种施加策略约束的方式是修改奖励函数——将行为偏离惩罚直接纳入奖励信号。

显式策略约束(二):修改奖励函数
概念详解
第二种显式施加策略约束的方法是修改奖励函数。思路是在每一步的环境奖励上减去一个行为偏离惩罚项:
$$\tilde{r}(s,a) = r(s,a) - \alpha \log \frac{\pi_\theta(a|s)}{\pi_\beta(a|s)}$$
在这个修改后的奖励下进行标准 RL 训练(如 Q-learning 或 Actor-Critic),策略自然会倾向于选择行为分布中常见的动作。这种方法通常使用 Reverse KL 散度(即 $\log(\pi_\theta/\pi_\beta)$),并且与最大熵RL(MaxEnt RL)框架天然兼容——在 MaxEnt RL 中,最优策略满足 $\pi^*(a|s) \propto \exp(Q(s,a)/\alpha)$,而加入 Reverse KL 奖励修正后的最优策略变为 $\pi^*(a|s) \propto \pi_\beta(a|s)^{\lambda} \exp(Q(s,a)/\alpha)$,即"行为策略引导的 Boltzmann 分布"。
深度剖析
修改奖励函数 vs 修改 Actor 目标——这两种方案之间的差异不仅是工程上的,更有深层的数学含义。
修改 Actor 目标(方案1):只在策略更新时施加约束,Q 函数的 Bellman 备份 $Q(s,a) \leftarrow r + \gamma \mathbb{E}_{a'\sim\pi}[Q(s',a') - \lambda D(\pi\|\pi_\beta)]$ 中的目标值不受约束影响(除非使用 in-sample 备份)。这意味着 Q 函数可能在 OOD 区域仍然存在过度估计,但策略因为约束的存在不会"走向"那些区域。
修改奖励函数(方案2):将约束嵌入到奖励信号中,使得 Q 函数的 Bellman 目标本身就反映了行为偏离的代价。这意味着 Q 函数从根上就对偏离行为策略的动作赋予了更低的值,从而自然地引导策略选择保守动作。Levine 教授指出"also accounts for future divergence"——修改奖励的方法会通过 Bellman 备份的递归性质,将当前步骤的策略偏离对未来步骤的影响也纳入考虑。
然而,方案2的代价是需要估计行为策略 $\pi_\beta$。这通常通过监督学习(最大似然)在数据集 $\mathcal{D}$ 上训练一个行为策略模型来实现。行为策略估计的质量直接影响约束效果——如果 $\pi_\beta$ 的估计不准确,奖励修正也会不准确。在多模态行为数据上,简单的 Gaussian 模型可能无法充分拟合 $\pi_\beta$,导致约束效果打折扣。
实例与类比
修改 Actor 目标好比在考试时被告知"尽量考高分,但不要用超出课本范围的知识"——约束是通过告诉学生"该怎么做"来实现的。修改奖励函数则好比重新设计了评分标准——"正确答案得10分,使用课本知识额外加2分,使用超纲知识扣3分"——约束嵌入到了评分体系中。后者的优势在于,学生在备考时(训练Q函数时)就会自发地偏好使用课本知识,而不是到了考试时才想起来要"控制自己"。这就是"accounts for future divergence"的含义——奖励修正通过时间差分学习传播到所有未来步骤。
关键要点
- 修改奖励函数将约束嵌入 $\tilde{r} = r - \alpha \log(\pi_\theta/\pi_\beta)$,通常使用 Reverse KL
- 优势:通过 Bellman 递归自然地考虑了未来步骤的策略偏离
- 劣势:需要额外训练并维护行为策略模型 $\pi_\beta$
- 与最大熵RL框架天然兼容,最优策略形式为 $\pi^* \propto \pi_\beta^\lambda \exp(Q/\alpha)$
- 对比修改 Actor 目标:奖励修正更根本但实现更复杂
→ 现在我们来看一个具体的显式约束算法实例——BRAC(Behavior Regularized Actor Critic),它采用了修改奖励函数的方案。

BRAC:行为正则化的Actor-Critic
概念详解
BRAC(Behavior Regularized Actor Critic)是 Wu, Tucker, Nachum 于 2019 年提出的离线RL算法,其核心思想是将策略约束集成到标准的 Actor-Critic 框架中。BRAC 实际上是一个算法模板(template),可以通过选择不同的散度度量(KL、MMD、Wasserstein 等)和行为策略估计方式来实例化出多种具体算法。
BRAC 的训练循环与标准 Actor-Critic 类似,但在两个关键位置加入了行为正则化:(1) Critic 更新——在 Bellman 目标中使用修改后的奖励 $\tilde{r} = r - \alpha D(\pi_\theta(\cdot|s) \| \pi_\beta(\cdot|s))$,以及可能在下一状态的策略熵上也加修正;(2) Actor 更新——最大化期望 Q 值的同时加入行为偏离惩罚。BRAC 还提出了值惩罚(value penalty)的变体,即在 Q 值上直接减去惩罚而非在奖励上。
深度剖析
BRAC 最重要的贡献在于系统性地形式化了行为正则化离线RL的搜索空间。在 BRAC 之前,不同的策略约束方法(如 BCQ、BEAR 等)各自使用不同的散度和实现方式,缺乏统一的比较框架。BRAC 通过抽象出以下设计维度,使得不同方法之间可以进行公平的"消融"(ablation)比较:
(1) 散度度量 $D$:KL 散度、最大平均差异(MMD, Maximum Mean Discrepancy)、Wasserstein 距离等;(2) 施加方式:值惩罚 vs 奖励惩罚;(3) 行为策略估计:参数化分布(如 Gaussian)vs 非参数化(如 VAE 编码);(4) 正则化系数 $\alpha$ 的选择方式(固定 vs 自适应)。
从算法流程图可以看出 BRAC 的核心步骤:从数据集 $\mathcal{D}$ 中采样一批 $(s, a, r, s')$ 元组;用行为策略模型 $\pi_\beta$ 计算当前策略偏离程度 $D(\pi(\cdot|s) \| \pi_\beta(\cdot|s))$;修改奖励为 $\tilde{r} = r - \alpha D$(或修改 Q 目标);按标准的 Bellman 误差更新 Critic;按修改后的目标更新 Actor。这个框架的优雅之处在于:如果去掉行为正则化项($\alpha=0$),BRAC 就退化为标准的 Actor-Critic。
实例与类比
BRAC 就像一个标准 Actor-Critic 算法的"行为安全版"。如果把标准 Actor-Critic 比作一辆没有刹车辅助的赛车(只管最快圈速),BRAC 就好比装上了牵引力控制系统——它仍然追求高性能(高Q值),但在检测到策略即将"打滑"(偏离数据支持区域)时自动降低功率(施加惩罚)。BRAC 的具体变体(BRAC+KL, BRAC+MMD 等)相当于不同的牵引力控制策略——有些更激进(允许更多偏离),有些更保守。
关键要点
- BRAC 是一个统一的离线RL算法模板,通过选择散度和正则化方式实例化为不同算法
- 核心操作:修改奖励 $\tilde{r} = r - \alpha D(\pi\|\pi_\beta)$ 或在Q值上施加惩罚
- 系统性地形式化了离线RL算法的设计空间:散度类型 × 施加方式 × 行为策略估计
- 退化为标准Actor-Critic:当 $\alpha=0$ 时即无正则化的在线RL
- BRAC 论文的消融实验为后续研究提供了宝贵的工程指导
→ 除了 BRAC 这种"奖励修正"路线,更简单直接的方案是在 Actor 更新中添加 BC 项——即所谓的 AC+BC 类方法。
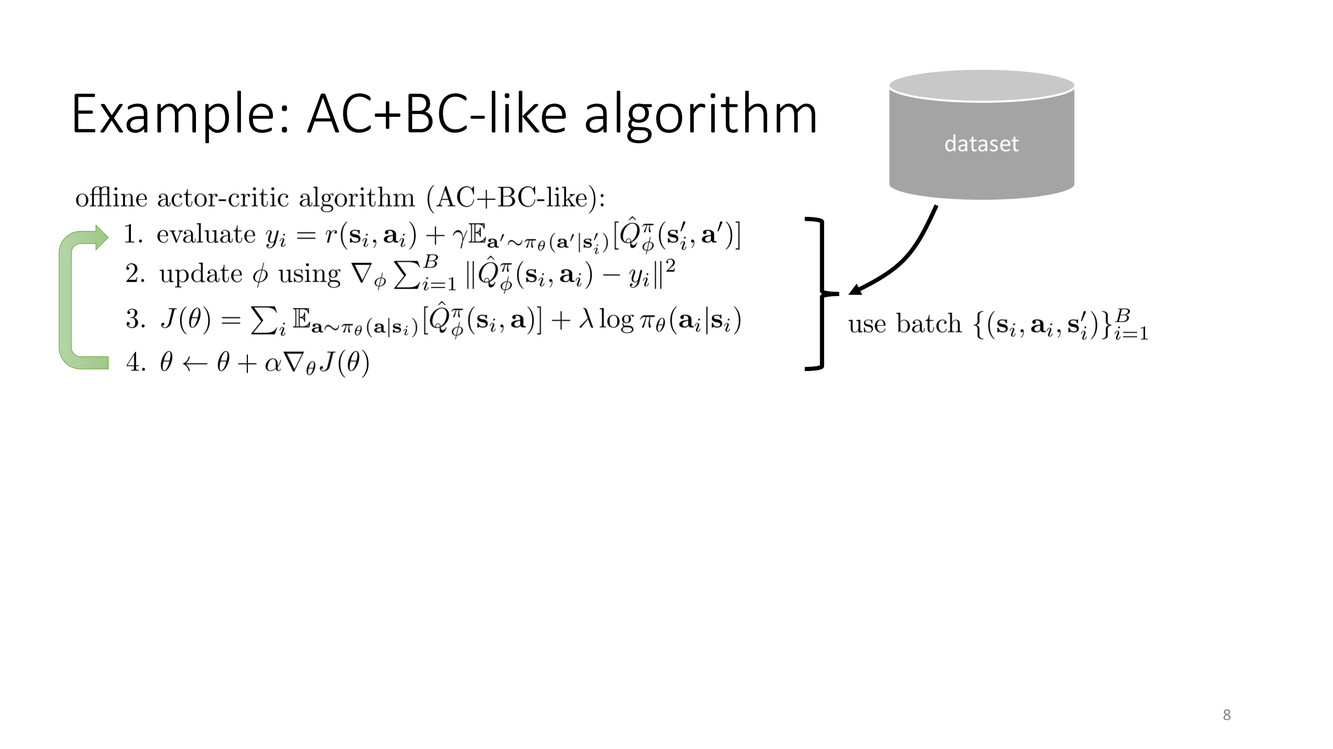
AC+BC:最简单的有效离线RL方法
概念详解
AC+BC 类方法代表了离线RL中实现最简单但出人意料有效的一类算法。其核心思想极其直接:在标准 Actor-Critic 的 Actor 损失函数中,添加一个行为克隆(BC)项:
$$\mathcal{L}_{\text{actor}}(\theta) = -\mathbb{E}_{s\sim\mathcal{D}, a\sim\pi_\theta}[Q(s,a)] - \beta \cdot \mathbb{E}_{(s,a)\sim\mathcal{D}}[\log \pi_\theta(a|s)]$$
其中第一项是标准的 Q 值最大化(负号因为是最小化损失),第二项是 BC 对数似然(取负号后即最大化 $\log\pi_\theta$)。超参数 $\beta$ 控制"性能提升"与"行为模仿"之间的权衡。
具体实现如 TD3+BC(Fujimoto & Gu, 2021):在 TD3 的 Actor 更新 $\max_\pi \mathbb{E}[Q(s,\pi(s))]$ 之上添加 $\lambda \cdot \mathbb{E}_{(s,a)\sim\mathcal{D}}[(\pi(s)-a)^2]$(MSE形式的BC)。或者更一般地,使用对数似然形式的 BC 梯度与 Q 值梯度加权求和来更新 Actor 参数。
深度剖析
AC+BC 的有效性初看令人费解——如果 BC 这么简单就能解决离线RL问题,为什么要研究复杂的 BRAC、CQL、IQL 等方法?关键在于理解 AC+BC 的能力边界。
AC+BC 在以下条件下表现良好:(1) 数据集中已经包含了较优行为的样本(数据质量不太差);(2) 行为分布相对简单(如单模态 Gaussian);(3) 任务对策略精度要求不高。在这些条件下,BC 项提供了一个温和的"引力",而 Q 值梯度在数据支持的区域内提供优化信号,两者的结合足以找到一个不错的策略。
AC+BC 的失效模式也很明确:(1) 当数据集中最优轨迹占比很低时,BC 的引力会过度拉向次优行为,Q 值提升的力不足以克服;(2) 当行为分布高度多模态时,简单的 BC(如 MSE 到均值)会趋向于"平均化"不同的模式,产生不在任何模式中的 OOD 动作;(3) 当 $\beta$ 较小时,Q 值过度估计可能将策略拉向 OOD 区域,而 BC 项的"回拉力"不够强。
Levine 教授的评价非常公允:"generally not the best way to fix the problem, but can work well if done right"——AC+BC 不应该是解决离线RL问题的唯一方案,但作为一个强基线(strong baseline),它的简单性使其成为实际应用中值得首先尝试的方法。
实例与类比
假设你在学习做菜,只有一本菜谱(离线数据集)可以参考。AC+BC 就像这样一种学习策略:每个步骤尽量模仿菜谱的示范(BC项),同时尝试让最终成品更美味(Q值最大化项)。如果菜谱本身已经相当不错,你在模仿的基础上微调就能做得很好。但如果菜谱中有很多平庸或错误的指导(低质量数据),过度模仿反而有害。相比之下,CQL 更像是"不仅要模仿菜谱,还要对所有菜谱里没出现过的做法持悲观态度"——这是一种更根本的安全机制。
关键要点
- AC+BC 是在 Actor 损失中直接添加 BC 项的最简方案:$\mathcal{L} = -\mathbb{E}[Q] - \beta \mathbb{E}[\log\pi]$
- TD3+BC(Fujimoto & Gu, 2021)是该类方法的代表,使用 MSE 形式的 BC
- 优势:实现极简、计算开销小、在调参得当时具备竞争力
- 劣势:本质上不是根本解决分布偏移问题,在数据质量差或多模态时可能失效
- 定位:离线RL的强基线,实际应用中值得首先尝试
→ 显式约束方法虽然直观,但需要估计 $\pi_\beta$ 并显式计算分布间距离。有没有更优雅的方式?接下来我们讨论隐式策略约束——优势加权回归(AWR)框架。

隐式策略约束:优势加权回归(AWR)
概念详解
优势加权回归(Advantage-Weighted Regression, AWR)是 Peng, Kumar, Levine 于 2019 年提出的离线RL方法,它提供了一种巧妙的方式来隐式地实现策略约束——无需显式地计算分布间距离,也无需维护行为策略模型。AWR 的核心数学推导基于最大熵RL框架中的对偶性(duality):
在 MaxEnt RL 中,给定 Q 函数,最优策略的解析形式为:
$$\pi^*(a|s) = \frac{1}{Z(s)} \pi_\beta(a|s) \exp\left(\frac{Q(s,a)}{\alpha}\right)$$
其中 $Z(s)$ 是归一化常数(配分函数)。取对数并重新排列,得到:
$$\log \pi^*(a|s) = \log \pi_\beta(a|s) + \frac{Q(s,a)}{\alpha} - \log Z(s)$$
这个等式暗示:要找到最优策略 $\pi^*$,我们可以最小化 $\pi_\theta$ 与 $\pi^*$ 之间的 KL 散度:
$$\min_\theta D_{KL}(\pi^* \| \pi_\theta) = \min_\theta \mathbb{E}_{a\sim\pi^*}[\log \pi^*(a|s) - \log \pi_\theta(a|s)]$$
代入 $\pi^*$ 的表达式并展开(使用重要性采样),AWR 的最终目标简化为:
$$\max_\theta \mathbb{E}_{(s,a)\sim\mathcal{D}}\left[\exp\left(\frac{A(s,a)}{\alpha}\right) \cdot \log \pi_\theta(a|s)\right]$$
其中 $A(s,a) = Q(s,a) - V(s)$ 是优势函数。这是一个加权最大似然估计——权重为 $\exp(A/\alpha)$,由 Critic 提供!
深度剖析
AWR 的美妙之处在于它完全绕开了显式的分布距离计算。让我们逐步追踪其数学逻辑:
第一步(MaxEnt RL 的最优策略形式):在标准 MaxEnt RL 中,最优策略为 $\pi^*(a|s) \propto \exp(Q(s,a)/\alpha)$。但在离线设定中,我们需要策略被约束在数据分布附近。通过对目标函数 $\mathbb{E}[Q] - \alpha D_{KL}(\pi \| \pi_\beta)$ 进行变分推导,可以得到约束后的最优策略 $\pi^*(a|s) \propto \pi_\beta(a|s) \exp(Q(s,a)/\alpha)$。
第二步(投影到参数化策略族):我们需要找到参数 $\theta$ 使得 $\pi_\theta$ 尽可能接近 $\pi^*$。最小化 $D_{KL}(\pi^* \| \pi_\theta)$(Forward KL 投影)等价于最大化:
$$\mathbb{E}_{a\sim\pi^*(\cdot|s)}[\log \pi_\theta(a|s)] = \int \pi_\beta(a|s) \frac{\exp(Q/\alpha)}{Z(s)} \log \pi_\theta(a|s) da$$
第三步(重要性采样转换为数据集期望):由于无法从 $\pi^*$ 采样,我们使用行为策略 $\pi_\beta$ 作为采样分布进行重要性加权:
$$\mathbb{E}_{a\sim\pi_\beta}\left[\frac{\exp(Q/\alpha)}{Z(s)} \log \pi_\theta(a|s)\right] \approx \mathbb{E}_{(s,a)\sim\mathcal{D}}\left[\exp(A/\alpha) \cdot \log \pi_\theta(a|s)\right]$$
这里 $Z(s)$ 被吸收进了优势函数中(因为 $A = Q - V$,而 $V$ 包含了 $\log Z$ 的信息),从而得到了优雅简洁的最终形式。
AWR 的一个关键优势是 Critic 可以给我们权重(通过 $Q$ 或 $A$),而 Actor 只需要做加权最大似然——这是一个非常稳定的训练过程。AWR 的相关工作可以追溯到 Peters et al. 的 REPS(Relative Entropy Policy Search)和 Rawlik et al. 的 $\Psi$-learning。
实例与类比
AWR 就像是在做一个"加权投票"式的模仿学习。假设你有一个数据集,里面是不同司机在各种路况下的驾驶操作(行为数据)。你同时有一个 Critic 来评判"给定当前路况,每个操作有多好"(优势函数 $A$)。AWR 的做法是:对数据集中好的操作($A > 0$)给予更高的训练权重($\exp(A/\alpha) > 1$),让策略多学习这些成功案例;对差的操作($A < 0$)给予较低的权重($\exp(A/\alpha) < 1$),不太关注它们。这比直接让策略 "踩油门到 Q 值最高的方向" 安全得多——策略始终在数据中出现的动作附近,只是选择了"加权偏好"的方向。
关键要点
- AWR 通过最大熵RL的对偶性,将策略约束转化为加权最大似然问题
- 目标函数:$\max_\theta \mathbb{E}_{(s,a)\sim\mathcal{D}}[\exp(A(s,a)/\alpha) \cdot \log \pi_\theta(a|s)]$
- 优点:无需显式计算分布距离、无需行为策略模型、训练稳定
- Critic 提供权重($A = Q - V$),Actor 只做加权最大似然
- 相关方法:REPS (Peters et al.)、$\Psi$-learning (Rawlik et al.)
→ AWR 框架在概念上非常优美,但其实践中的适应性如何?接下来我们看 AWAC——在离线与在线场景之间架起桥梁的扩展方法。
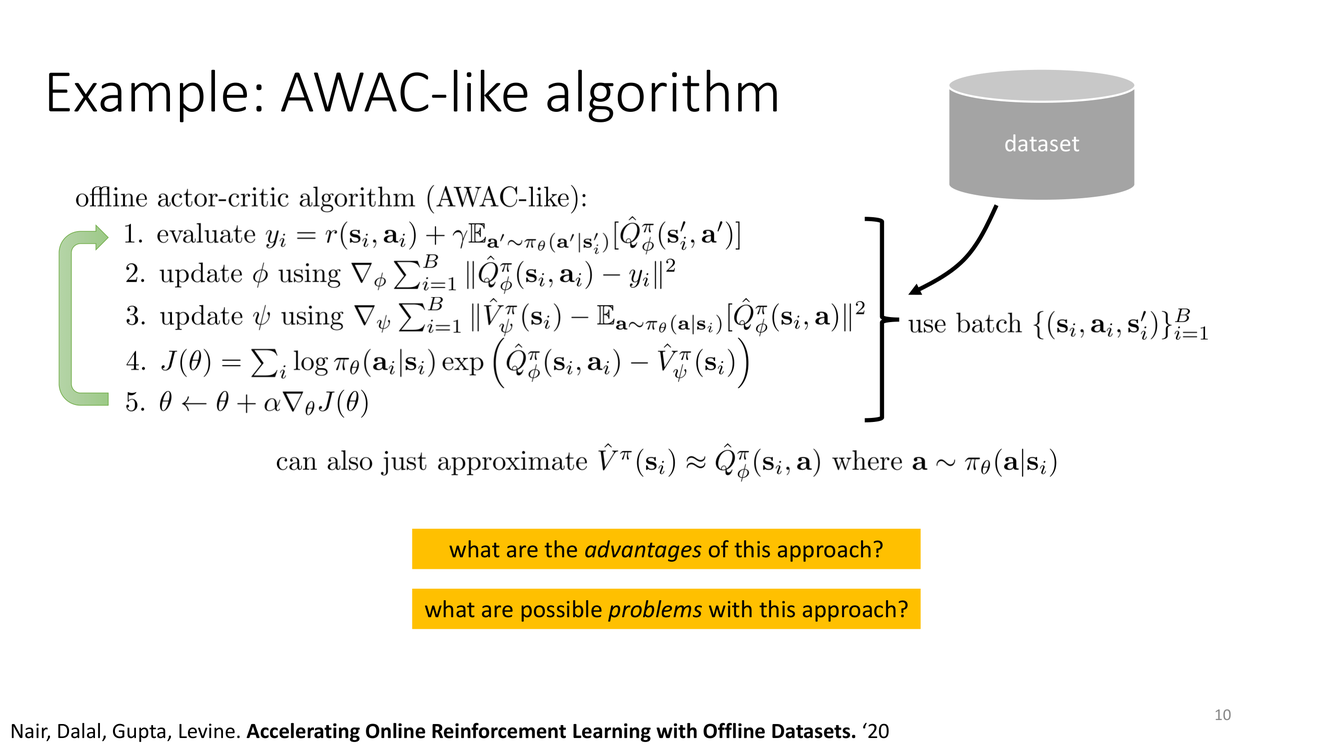
AWAC:加速在线RL的离线预训练方法
概念详解
AWAC(Advantage Weighted Actor Critic)由 Nair, Dalal, Gupta, Levine 于 2020 年提出,全称 "Accelerating Online Reinforcement Learning with Offline Datasets"。如其名所示,AWAC 的设计目标不仅仅是做好离线RL,更是利用离线数据加速在线RL。
AWAC 的核心思想继承了 AWR 的加权最大似然框架,但做了两个关键简化:(1) 使用裁剪的优势权重——权重为 $\exp(A/\alpha)$ 但 $\alpha$ 的选择更加激进(较小),从而在离线阶段给予高优势动作更强的偏好;(2) 简化 Critic 更新——使用标准的 TD 学习来估计 Q 函数,无需像 IQL 那样使用特殊的损失函数。
AWAC 算法流程从数据集 $\mathcal{D}$ 出发:采样 $(s, a, r, s')$ 元组;用标准 Bellman 备份更新 Q 函数(Critic);对 Actor 做加权最大似然更新,权重由优势 $A(s,a) = Q(s,a) - \mathbb{E}_{a'\sim\pi}[Q(s,a')]$ 通过 $\exp(\cdot/\alpha)$ 变换得到。这个看似简单的方案在离线预训练阶段保持了策略安全性(不偏离数据),同时在在线微调阶段能够快速利用新数据。
深度剖析
AWAC 的设计中有一个深刻的"跨阶段一致性"(cross-phase consistency)概念。许多离线RL方法在切换到在线微调时面临"水土不服"——离线阶段学到的保守偏置(如 CQL 的 Q 值压低)在在线阶段可能阻碍探索和策略提升。AWAC 则通过统一的加权最大似然框架,在两个阶段使用完全相同的 Actor 更新规则:
$$\max_\theta \mathbb{E}_{(s,a)\sim\text{buffer}}\left[w(A(s,a)) \cdot \log \pi_\theta(a|s)\right]$$
其中权重函数 $w(A) = \exp(A/\alpha)$。在离线阶段,buffer 就是固定的数据集 $\mathcal{D}$;在在线阶段,buffer 是混合了离线数据和在线交互数据的回放缓冲。这个统一的形式意味着:当在线数据中的高优势动作出现时,AWAC 自然就会偏好它们,无需"切换模式"。
Levine 教授的幻灯片提出了两个引导性问题:"what are possible problems with this approach?" 和 "what are the advantages of this approach?"。可能的问题在于:(1) 优势估计 $A$ 的质量高度依赖于 Q 函数估计的准确性——在离线阶段,Q 函数可能由于数据覆盖不完整而有偏;(2) 指数权重 $\exp(A/\alpha)$ 对 Q 值误差非常敏感——如果 Q 函数在某个数据点上有噪声性的高估,该点将获得不成比例的高权重;(3) $\alpha$ 的选择需要手动调节,且在离线与在线阶段的最佳值可能不同。而优势在于:训练极其稳定(Actor 只做加权 MLE,不存在"策略优化导致动作漂移出数据分布"的风险)、离线与在线阶段的无缝衔接、以及在实践中优异的样本效率。
实例与类比
AWAC 的工作方式可以类比为"案例教学法"。在离线阶段,你有一大堆历史案例(数据集),每个案例标注了"这样做是好是坏"(优势 $A$)。AWAC 的做法是:重点学习那些"好案例"中的操作模式,而不是凭空想出新做法。进入在线阶段(真实环境)后,当你遇到新的案例(自行收集的数据),你自然地将它们加入案例库,AWAC 自动对"好案例"赋予更高权重。这种一致性是 AWAC 最大的工程优势——没有"切换模式"带来的震荡。
关键要点
- AWAC 继承了 AWR 的加权最大似然框架,针对离线到在线场景做了优化
- 核心优势:离线预训练与在线微调使用完全相同的更新规则,实现无缝衔接
- Actor 更新:$\max_\theta \mathbb{E}_{(s,a)\sim\text{buffer}}[\exp(A/\alpha) \cdot \log \pi_\theta(a|s)]$
- Critic 使用标准 TD 学习,无需特殊设计
- 潜在问题:权重对 Q 值误差敏感,$\alpha$ 需手动调节
- 论文标题 "Accelerating Online RL with Offline Datasets" 精准反映了设计目标
→ 策略约束方法——无论是显式还是隐式——都需要在Actor更新中处理OOD问题。但有没有可能从根本上避免在Q更新中评估OOD动作?这就是第二部分:隐式Q学习(IQL)的核心创新。
第2章:隐式Q学习 — Implicit Q-Learning (IQL)

第二部分引言:隐式Q学习
概念详解
第二部分引出了离线RL中一个极具原创性的方法:隐式Q学习(Implicit Q-Learning, IQL)。IQL 由 Ilya Kostrikov、Ashvin Nair 和 Sergey Levine 于 2021 年提出,其核心动机来自于对前面所有方法的一个根本性质疑:能不能完全避免在 Q 函数更新中评估任何不在数据集中的动作?
回顾前面讨论的各类方法:策略约束方法(BRAC、AC+BC、AWR/AWAC)仍然需要在 Actor 更新中查询 $Q(s, \pi(s))$,其中 $\pi(s)$ 可能产生 OOD 动作;即使 Actor 被约束,Q 函数在训练过程中仍然会在这些区域被评估。IQL 则采取了更激进的策略:将整个 Actor-Critic 流程重新设计,使得 Q 函数的训练完全不需要评估数据集之外的动作——这就是"隐式"(implicit)的含义:策略提升是通过对数据分布下的价值函数进行特殊处理来实现的,而非通过显式的策略梯度步骤。
深度剖析
IQL 的"隐式"哲学在离线RL领域是一个重要的概念突破。传统 Actor-Critic 的逻辑是:Critic 评估动作好坏 → Actor 据此选择更好(Q值更高)的动作 → Critic 再评估新动作 → 循环往复。这个循环在离线RL中是有问题的——"Actor 选择更好动作"的步骤可能选出 OOD 动作,而 Critic 对这些动作的评估可能不准确,导致错误的反馈循环。
IQL 将这个循环"折叠"进了一个更简单的结构。其关键洞察是:我们其实不需要显式地学习一个策略来输出"更好的动作"。相反,我们可以直接学习数据支持集下的最优状态值函数 $V^*(s)$——即"在你的数据集中,从状态 $s$ 出发可能达到的最好结果"。然后,通过简单的优势加权回归(类似 AWR)来提取策略。这样,整个训练过程中没有一步需要查询 OOD 动作的 Q 值。
IQL 的核心技术组件是期望回归(expectile regression),它提供了一种在不显式取最大值的情况下逼近"上分位数"(upper quantile)Q 值的方法。我们将在接下来的 slides 中详细展开。
实例与类比
传统 Actor-Critic 好比一个学生通过不断提出新问题(Actor生成动作)来学习,但有些问题老师(Critic)也回答不上来(OOD动作)。策略约束方法好比限制学生只能问"课本范围内"的问题。IQL 则完全改变了教学方式:老师不需要被提问——老师直接告诉你"在你已掌握的知识范围内,这个问题的最佳可能答案是什么"。学生(策略)随后通过模仿老师的高分回答来进步。这种"不需要学生提问"的学习方式,就是 IQL "避免 OOD 动作"的精髓。
关键要点
- IQL 的核心动机:完全避免在 Q 函数更新中评估任何 OOD 动作
- "隐式"的含义:策略提升通过价值函数的特殊处理实现,而非显式的策略梯度
- 关键技术:期望回归(expectile regression),用于逼近数据支持集下的最优Q值
- 设计哲学:将 Actor-Critic 的循环"折叠"为两个独立步骤,消除OOD动作评估的需求
- 论文:Kostrikov, Nair, Levine. "Offline Reinforcement Learning with Implicit Q-Learning." 2021
→ 让我们直接面对 IQL 的核心问题:如何在不评估任何OOD动作的情况下,学到"数据中最优动作"的 Q 值?
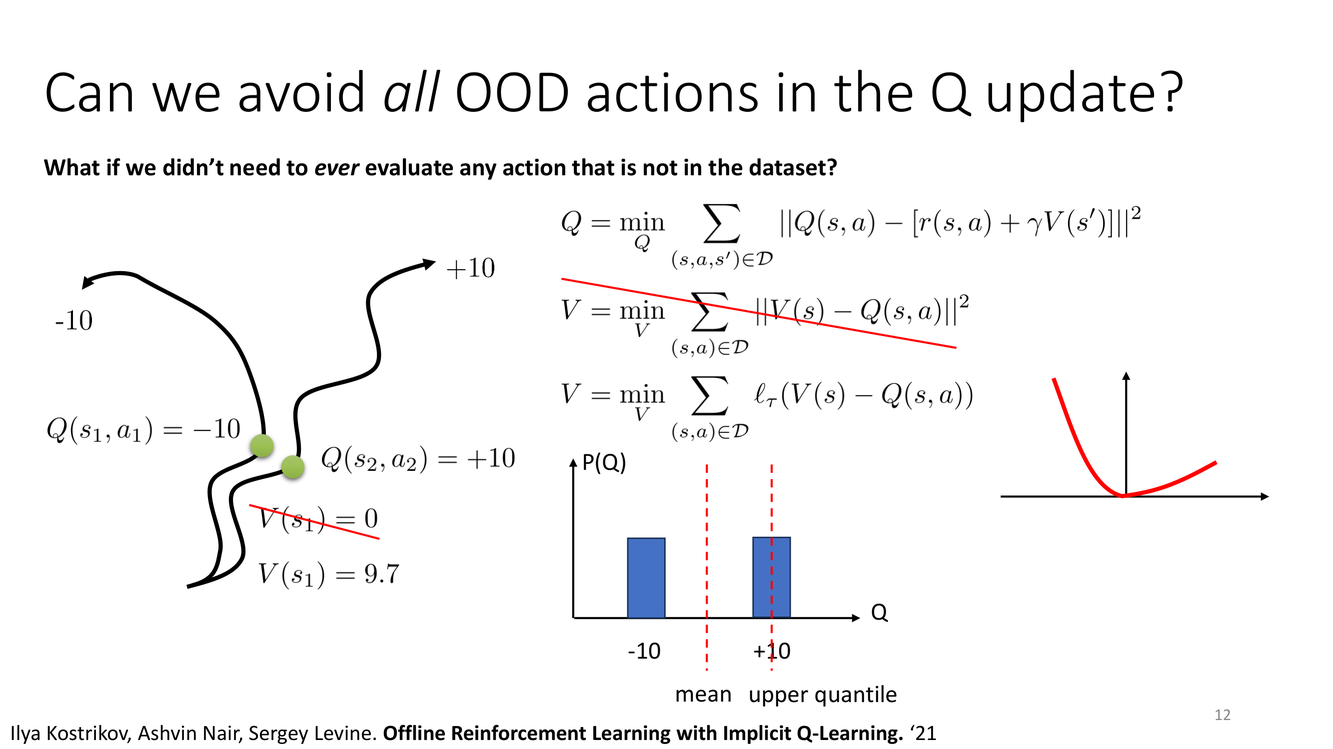
核心问题:能否完全避免Q更新中的OOD动作?
概念详解
这张幻灯片直接对准了 IQL 的核心思想。传统 Q-learning 的 Bellman 最优算子需要计算 $\max_{a'} Q(s', a')$——这个最大化操作隐式地评估了所有可能的动作,包括那些在数据集中不存在的 OOD 动作。在在线RL中,这没问题,因为我们可以实际执行 $a'$ 并获取反馈。但在离线RL中,我们只能依赖不完整的 Q 函数近似,过度估计几乎不可避免。
IQL 的新视角是:不需要对所有可能的 $a'$ 取 max。取而代之的是,我们可以只考虑数据集中实际出现的动作,并问一个不同的问题:"在数据集中出现的动作中,表现较好的那些的 Q 值是多少?" 这正是条件期望和分位数回归的视角。
Slide 12 的图示展示了这个想法:给定状态,Q 值的分布 $P(Q)$ 由数据集中出现的动作诱导。在分布曲线下方标注了 "mean"(均值)和 "upper quantile"(上分位数)。IQL 的关键想法是:使用上分位数作为对"最佳数据内动作"的 Q 值估计——而不是对所有可能动作取 max。这样可以保证估计的值始终在数据支持的范围内。
深度剖析
从数学上看,传统的 Bellman 最优算子 $\mathcal{B}^*$ 定义为:
$$(\mathcal{B}^* Q)(s, a) = r(s, a) + \gamma \mathbb{E}_{s'\sim P(\cdot|s,a)}\left[\max_{a'} Q(s', a')\right]$$
这里的 $\max_{a'}$ 是问题所在——它评估了动作空间中的所有 $a'$,包括远离数据支持的 OOD 动作。在表格型RL中,这不会造成问题(因为所有动作都会被均匀探索);但在函数近似 + 离线数据场景中,Q 网络在 OOD 区域的值完全不受数据约束,可以是任意值。
IQL 用以下替代方案来逼近"数据支持集内的最优Q值":
$$(\mathcal{T} Q)(s, a) = r(s, a) + \gamma \mathbb{E}_{s'}\left[\mathbb{E}_{a'\sim\pi_\beta(\cdot|s')}[\max(Q(s', a'), \tau\text{-expectile}(Q, s'))]\right]$$
或者更精确地说,IQL 学习一个价值函数 $V_\psi(s)$ 来逼近 $\tau$-expectile of $Q(s, a)$ with respect to $a \sim \pi_\beta(\cdot|s)$,其中 $\tau > 0.5$(靠近1时为上分位数)。Expectile 是对均值的一种非对称推广:当 $\tau=0.5$ 时为条件均值,当 $\tau \to 1$ 时趋向于最大值。因此,通过选择 $\tau \approx 0.9$,$V_\psi(s)$ 自然地逼近"行为策略下 Q 值分布的上分位数"——即"数据中较好动作"的 Q 值,而无需显式最大化。
实例与类比
假设你在一个只有三个按钮的旧遥控器上测试电池电量。你只能按这三个按钮(数据集中的动作),不能尝试按其他按钮(OOD动作)。传统的 max 方法假设你可以按任何按钮,并试图猜测"最佳按钮"的效果——但如果遥控器上有你从未按过的按钮,你的估计可能是完全离谱的。IQL 则更务实:它只看你按过的三个按钮中,"表现较好的那一个"(上分位数)的响应,并将此作为对"最佳可能的按钮响应"的一个保守但可靠的估计。$\tau \approx 0.9$ 意味着你在看"前10%好的按钮"而非"绝对最好的那个"。
关键要点
- 传统 Q-learning 的 $\max_{a'} Q(s', a')$ 需要在所有动作上评估——包括 OOD 动作
- IQL 的替代方案:用数据分布下 Q 值的上分位数(upper quantile/expectile)替代 max
- 上分位数提供了对"数据内最佳动作"的保守估计,无需查询 OOD 动作
- $\tau$-expectile 是条件期望的非对称推广:$\tau=0.5$ 为均值,$\tau\to 1$ 趋于 max
- 核心图示:Q 值分布曲线下,mean 和 upper quantile 的位置差异
→ 期望回归(expectile regression)是 IQL 的技术核心。让我们详细展开——IQL 如何用两个神经网络来学习价值函数和 Q 函数,而不需要离开数据分布。
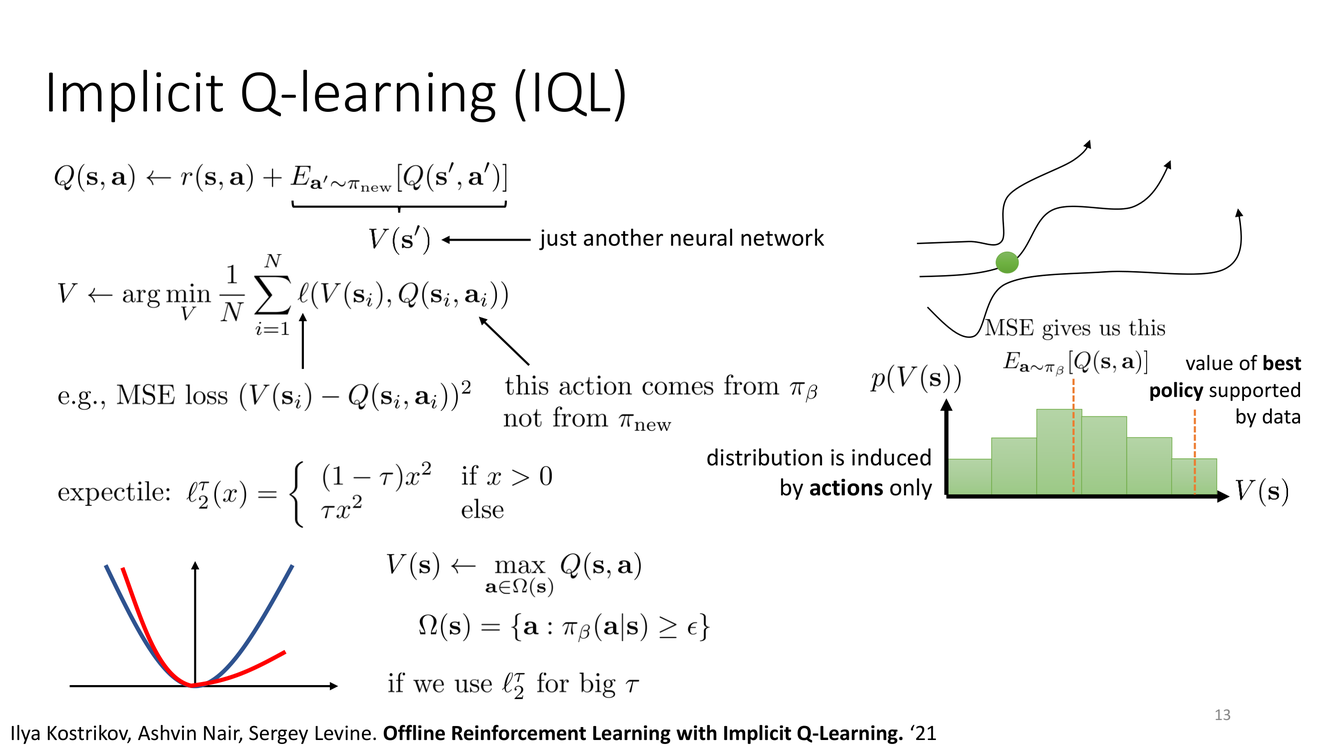
IQL 核心机制:期望回归与价值函数学习
概念详解
IQL 的训练架构由三个神经网络组成:Q 函数 $Q_\phi(s,a)$、价值函数 $V_\psi(s)$("just another neural network"),以及最终通过优势加权回归提取的策略 $\pi_\theta(a|s)$。其核心创新在于 $V_\psi$ 的学习方式——期望回归(expectile regression)。
期望回归是分位数回归(quantile regression)的平滑替代方案。给定一个目标值 $y$ 和预测值 $\hat{y}$,$\tau$-期望回归的损失函数是:
$$L_\tau(y, \hat{y}) = |\tau - \mathbb{1}_{y < \hat{y}}| \cdot (y - \hat{y})^2$$
这就是一个非对称的平方损失:当 $\tau > 0.5$ 时,低估($\hat{y} < y$)受到的惩罚比高估更重——损失被乘上了 $\tau$(低估时)或 $1-\tau$(高估时)。对于 $\tau=0.9$,低估的惩罚是高估的9倍,因此最优预测会被"拉"向分布的上分位数(top 10%)。
IQL 使用期望回归来学习价值函数 $V_\psi$,目标为:
$$\mathcal{L}_V(\psi) = \mathbb{E}_{(s,a)\sim\mathcal{D}}\left[L_\tau(Q_{\bar{\phi}}(s,a) - V_\psi(s))\right]$$
其中 $Q_{\bar{\phi}}$ 是目标网络(target network)的 Q 值。因为 $a \sim \pi_\beta(\cdot|s)$(动作来自数据集),$V_\psi(s)$ 被训练为逼近数据分布下 Q 值的 $\tau$-上期望——即"数据中最优动作 Q 值"的近似。
深度剖析
期望回归的数学性质值得深入分析。对于 $\tau \in (0,1)$,令 $f_\tau(x) = |\tau - \mathbb{1}_{x<0}| \cdot x^2$。这个函数在 $x=0$ 处连续(因为 $\lim_{x\to 0^-} \tau x^2 = \lim_{x\to 0^+} (1-\tau) x^2 = 0$),但梯度在 $x=0$ 处不连续。然而在实际优化中,这个轻微的不光滑性不会造成问题——实际上,由于我们使用随机梯度下降,它反而在分位数附近产生了鲁棒性。
对于 $\tau \to 1$,$\tau$-期望趋近于"上确界"(supremum)。具体来说,如果随机变量 $X$ 有上界 $M$,则 $\lim_{\tau\to 1} \tau\text{-expectile}(X) = M$。对于无界分布(如 Gaussian),$\tau$-期望随 $\tau \to 1$ 发散。因此在实践中,$\tau$ 的选择是一个关键超参数:$\tau$ 太接近 1 会使得 $V_\psi$ 过度追求极值(容易被噪声数据点误导);$\tau$ 太小(接近0.5)则 $V_\psi$ 接近条件均值,无法区分好动作和坏动作。IQL 论文中通常使用 $\tau \in [0.7, 0.95]$,典型值为 $\tau=0.9$。
另一个重要的实现细节是:"distribution is induced by actions only"——Q 值的分布完全由动作的随机性(给定状态 $s$,数据集中动作的分布 $\pi_\beta(\cdot|s)$)诱导。这意味着 $V_\psi(s)$ 刻画的是"在当前数据的动作分布下,Q 值的 $\tau$-分位数"——不涉及任何对 OOD 动作的推断。
实例与类比
假设一个状态下有100个数据点(100次历史决策),每个对应不同的动作和不同的 Q 值。传统方法会尝试寻找"能让 Q 值最大的动作"——即使这个动作数据中没有出现过。IQL 的期望回归则更像是一个"加权投票":它对 Q 值较高的数据点给予更多关注(9倍权重),对 Q 值较低的数据点关注较少(1倍权重),最终输出 $V_\psi(s)$ 是所有这些数据点 Q 值的加权平均——但这个加权是非对称的,所以结果偏向数据集中较好动作的 Q 值。可以说,$V_\psi(s)$ 回答的问题是:"在已有的数据中,比较好的那些决策,平均能有多好?" 而非 "理论上可能的最优决策能有多好?"
关键要点
- IQL 使用三个网络:$Q_\phi$(Q函数)、$V_\psi$(价值函数)、$\pi_\theta$(策略)
- $V_\psi$ 通过 $\tau$-期望回归学习:$\mathcal{L}_V = \mathbb{E}[L_\tau(Q_{\bar{\phi}}(s,a) - V_\psi(s))]$
- $L_\tau(y,\hat{y}) = |\tau - \mathbb{1}_{y<\hat{y}}| (y-\hat{y})^2$ 是非对称平方损失
- $\tau=0.9$ 意味着低估的惩罚是高估的9倍,$V_\psi$ 被"拉"向上分位数
- Q 值分布仅由数据动作诱导——全程无 OOD 动作参与
→ 有了 $V_\psi$ 作为"数据支持集最优值"的估计,IQL 如何用它来更新 Q 函数并提取策略?

IQL:带隐式策略提升的Q-learning
概念详解
有了通过期望回归学到的 $V_\psi(s)$(逼近数据支持集下的上分位数 Q 值),IQL 的 Q 函数更新变得异常简单:
$$\mathcal{L}_Q(\phi) = \mathbb{E}_{(s,a,r,s')\sim\mathcal{D}}\left[\left(r + \gamma V_\psi(s') - Q_\phi(s,a)\right)^2\right]$$
这就是标准 SARSA 风格的 TD 学习——使用 $V_\psi(s')$ 作为下一状态的 bootstrap 目标,而非 $\max_{a'} Q(s', a')$。关键洞察是:因为 $V_\psi$ 已经通过期望回归逼近了"数据中动作的 $\tau$-上分位数 Q 值",$V_\psi(s')$ 实际上充当了隐式的策略提升步骤的结果——它回答了"在状态 $s'$,按照数据中的好动作来做,能拿到多少价值"。
Levine 教授强调:"Now we can do value function updates without ever risking out-of-distribution actions!"——这就是 IQL 最根本的优势。整个 Q 函数的训练过程中,没有任何一个步骤需要查询动作 $\pi(s')$(如 Actor-Critic)或对所有动作取 max(如 Q-learning)。所有操作都在 $(s, a, r, s')$ 元组的信息范围内进行。
深度剖析
让我们仔细对比传统 Q-learning 与 IQL 的 Q 更新:
标准 Q-learning:
$$\mathcal{L}_Q = \mathbb{E}[(r + \gamma \max_{a'} Q_{\bar{\phi}}(s', a') - Q_\phi(s,a))^2]$$
这里 $\max_{a'}$ 在连续动作空间中需要通过梯度上升来近似,并且不可避免地涉及 OOD 动作。
IQL 的 Q 更新:
$$\mathcal{L}_Q = \mathbb{E}[(r + \gamma V_\psi(s') - Q_\phi(s,a))^2]$$
$V_\psi$ 完全在数据分布的支持集内被定义和训练。这是通过在 Q 更新与 V 更新之间建立不对称的依赖关系来实现的:V 的更新依赖 Q(作为目标),但 Q 的更新依赖 V(作为 bootstrap)。这个循环在数学上是自洽的——当 $\tau \to 1$ 时,$V_\psi$ 趋向于 $\max_{a: \pi_\beta(a|s)>0} Q(s,a)$(数据支持集上的最大值),从而 IQL 的 Q 更新趋向于支持集约束下的 Bellman 最优更新。
这个架构还有一个重要的工程优势:Q 函数和 V 函数的更新是相互解耦的,可以各自使用不同的优化器和学习率,训练过程非常稳定。相比之下,Actor-Critic 中的 Actor 和 Critic 交替更新可能导致训练震荡。
实例与类比
想象你是一个只能通过历史档案研究某个棋手的棋局来分析其水平的分析师。传统方法(标准Q-learning)会这样做:看当前局面,尝试想象最佳的下一步(max操作),但这个"最佳下一步"可能历史上从未出现过——你的想象可能完全离谱。IQL 则更严谨:你只看该棋手实际下过的那些对局中的后续走法,然后从中挑出"较好的"($\tau=0.9$ 上分位数),用这些实际发生的走法来评估当前局面的好坏。你的评估不会超出历史记录的范围,因此不会出现"想象偏误"。
关键要点
- IQL 的 Q 更新:$\mathcal{L}_Q = \mathbb{E}[(r + \gamma V_\psi(s') - Q_\phi(s,a))^2]$,无 $\max$ 操作
- $V_\psi(s')$ 作为隐式策略提升的结果,替代了 $\max_{a'} Q(s', a')$
- 不对称依赖关系:$V_\psi$ 依赖 $Q$ 作为目标,$Q$ 依赖 $V_\psi$ 作为 bootstrap
- 工程优势:$Q$ 和 $V$ 的更新相互解耦,训练稳定
- 根本保证:全程无 OOD 动作参与 Q 或 V 的训练
→ 完整的 IQL 算法还需要最后一步——从学到的 Q 和 V 中提取出可执行的策略。
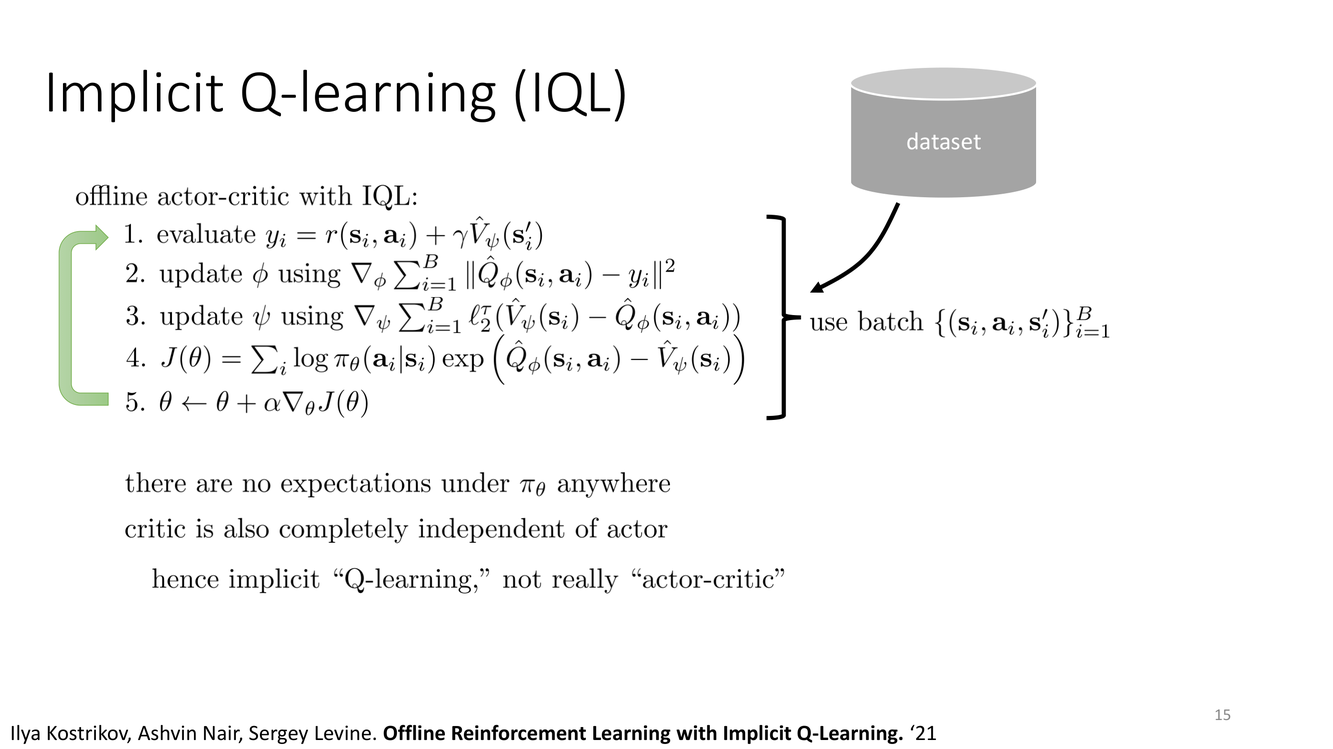
IQL 完整算法总结
概念详解
IQL 的完整训练流程可以分解为三个交替进行的步骤,所有步骤都只使用来自数据集 $\mathcal{D}$ 的样本:
步骤一:更新价值函数 $V_\psi$(期望回归)
$$\mathcal{L}_V(\psi) = \mathbb{E}_{(s,a)\sim\mathcal{D}}[L_\tau(Q_{\bar{\phi}}(s,a) - V_\psi(s))]$$
其中 $L_\tau$ 是非对称平方损失,$Q_{\bar{\phi}}$ 是目标网络(target network)。$V_\psi$ 学习逼近数据分布下 Q 值的 $\tau$-上期望。
步骤二:更新 Q 函数 $Q_\phi$(SARSA 风格 TD 学习)
$$\mathcal{L}_Q(\phi) = \mathbb{E}_{(s,a,r,s')\sim\mathcal{D}}[(r + \gamma V_\psi(s') - Q_\phi(s,a))^2]$$
$V_\psi$ 提供了下一状态价值的 bootstrap 目标。注意这里用的是 $V_\psi$(当前价值网络),实际操作中 $V_\psi$ 在 Q 更新时被视为固定目标(stop gradient)。
步骤三:提取策略 $\pi_\theta$(优势加权回归)
$$\mathcal{L}_\pi(\theta) = \mathbb{E}_{(s,a)\sim\mathcal{D}}\left[\exp\left(\frac{Q_\phi(s,a) - V_\psi(s)}{\alpha}\right) \cdot \log \pi_\theta(a|s)\right]$$
这与 AWR 的加权最大似然相同——优势 $A(s,a) = Q_\phi(s,a) - V_\psi(s)$ 被指数化后作为权重。参数 $\alpha$ 控制温度:较小的 $\alpha$ 使权重更集中到高优势动作上。
深度剖析
IQL 的设计哲学——将策略优化拆分为"隐式提升+显式提取"——具有深远的方法论意义。在标准的 Actor-Critic 框架中,Critic 和 Actor 的优化是紧耦合的:Actor 的更新方向来自 Critic 的梯度,Critic 的评估对象又来自 Actor 的采样。这种紧耦合在在线RL中是优势(高效利用采样),但在离线RL中成为问题——Actor 生成的动作可能是 OOD 的,Critic 对这些动作的评估引导 Actor 走偏,形成恶性循环。
IQL 的"解耦"通过两个关键的分离实现:(1) 提升(improvement)与评估(evaluation)的分离——提升被隐式地嵌入到 $V_\psi$ 的期望回归中,评估只需做标准的 TD 更新;(2) 提升与策略参数化的分离——价值提升不依赖策略网络的梯度,策略只需在最后通过加权模仿学习来"读取"价值函数的结果。
这种解耦使得 IQL 在实践中具有出色的稳定性:Q 和 V 的更新只涉及平方损失(凸优化问题),策略更新只涉及加权最大似然(也是凸的,条件于权重)。没有对抗性训练(如 GAN 风格的 min-max),没有需要精细调节的 Lagrange 乘子,没有需要估计的行为策略分布。IQL 在 D4RL 基准上的表现证明了这种极致简洁的有效性——它在多个任务上匹敌甚至超越了设计更复杂的 CQL。
实例与类比
IQL 就像一个三阶段的组装线:第一阶段(V 更新),一位分析师审视所有历史决策记录,标记出"哪些决策属于 top 10% 好的"(期望回归);第二阶段(Q 更新),另一位分析师基于第一阶段的标记,重新评估每个决策的长期价值(TD 学习);第三阶段(策略提取),一位执行者观察前两个阶段的成果,重点模仿那些被标记为"好"的决策(加权最大似然)。三个阶段各司其职、相互独立,都不需要"想象"数据中没有的决策。这正是 IQL "避免 OOD 动作"的工程实现。
关键要点
- IQL 三步骤:期望回归学 $V_\psi$ → SARSA 风格学 $Q_\phi$ → 优势加权回归提取 $\pi_\theta$
- $\tau$ 控制 $V_\psi$ 的乐观程度:$\tau=0.9$ 意味着 $V_\psi$ 关注数据中 top 10% 好的动作
- $\alpha$ 控制策略提取的温度:较小的 $\alpha$ 使策略更"贪婪"地聚焦最高优势动作
- 三个步骤都是凸优化(在固定权重下),训练极为稳定
- 在 D4RL 基准上,IQL 以其简洁性匹敌甚至超越更复杂的 CQL
- 核心哲学:解耦提升与评估、解耦提升与策略参数化
→ 从 IQL "避免 OOD 动作"的哲学走出,让我们看一个采用了截然不同策略的方法:CQL——它不回避 OOD 动作,而是主动"打压"它们。

中场休息与课程过渡
概念详解
第16张幻灯片标记了课程的中场休息(Intermission)。在前半部分(Slides 1-15),我们系统性地讨论了离线RL的两个核心方法论:(1) 策略约束——通过显式(修改Actor目标或奖励函数)或隐式(AWR/AWAC 的加权最大似然)方式限制策略偏离行为分布;(2) 隐式Q学习(IQL)——通过期望回归完全避免在Q更新中评估OOD动作,实现隐式的策略提升。这两种方法论代表了应对离线RL核心挑战(分布偏移+过度估计)的两种不同哲学:一种是"施加约束,让策略在安全区域内行动",另一种是"改变评估方式,让Q函数不需要冒险评估未知区域"。
深度剖析
这个中场休息是理解离线RL算法空间结构的重要节点。我们可以在一个二维平面上组织已讨论的方法:横轴是"对OOD动作的态度"(从"积极避免"到"主动压制"),纵轴是"实现复杂度"(从"几行BC代码"到"多网络交替训练")。
在这个平面上,AC+BC 位于"最简实现 + 温和约束"的角落;BRAC 位于"中等复杂度 + 显式约束"的区域;AWR/AWAC 位于"中等复杂度 + 隐式约束";IQL 位于"较高复杂度 + 完全避免OOD"的位置。而在中场休息之后,我们将遇到 CQL,它占据了"主动压制OOD动作"这一端——通过显式的保守正则化项,系统性地压低所有可能OOD动作的Q值。CQL 的哲学是:"既然无法完全避免评估OOD动作,那就确保对这些动作的评估是悲观的。"
实例与类比
如果把离线RL算法比作不同的投资风险管理策略:前半部分的方法相当于"只投资你了解的领域"(策略约束)和"不评估你不了解的投资"(IQL)。接下来要讲的 CQL 则相当于"对你了解的领域正常投资,对不了解的领域系统性地低估其回报"——这是一种更主动的风险管理策略。
关键要点
- 前半部分覆盖了两大方法论:策略约束(显式+隐式)和隐式Q学习(IQL)
- 不同方法对 OOD 动作的态度构成一个光谱:温和约束 → 隐式避免 → 主动压制
- CQL(后半部分第一主题)采用"主动压制"策略,通过保守正则化压低 OOD 动作的 Q 值
- 离线到在线RL(Part 4)和基于模型的离线RL(Part 5)是后半部分的另外两大主题
→ 中场休息结束。让我们进入第三部分:保守Q学习(CQL)——一套直接"打压"OOD动作Q值的算法框架。
第3章:保守Q学习 — Conservative Q-Learning (CQL)

第三部分引言:保守Q学习
概念详解
第三部分介绍离线RL中可能最具影响力的算法之一:保守Q学习(Conservative Q-Learning, CQL)。CQL 由 Kumar, Zhou, Tucker, Levine 于 2020 年提出,它是目前离线RL中被最广泛使用和引用的算法。与 IQL 的"避免 OOD 动作"策略不同,CQL 选择了一条更主动的路径:故意压低所有潜在 OOD 动作的 Q 值,同时保持数据集中出现过的动作的 Q 值准确。
CQL 的核心思想可以用一句话概括:"对不了解的事情保持悲观"(be pessimistic about what you don't know)。在数学上,这意味着在学习 Q 函数时添加一个正则化项,该正则化项最小化策略(可能是任意策略)采样动作的 Q 值期望,同时最大化数据集中真实动作的 Q 值期望。这种"压低一头、抬高另一头"的组合确保了:Q 函数在数据支持区域的值是准确的,但在数据不支持的区域(OOD),Q 值被系统性地压低——从而策略不会倾向于选择 OOD 动作。
深度剖析
CQL 的哲学与 IQL 形成了有趣的对比。IQL 试图完全避免评估 OOD 动作——通过期望回归,它只关心数据中实际出现动作的 Q 值分布。CQL 则承认:在函数近似下,神经网络不可避免地会对 OOD 动作产生某种 Q 值预测(网络必须对输入空间中的所有点都有输出),问题不在于"是否评估 OOD 动作",而在于"对这些评估赋予什么样的偏置"。CQL 的选择是赋予向下的偏置(downward bias)——让 OOD 动作的 Q 值被压低。
这种"向下偏置"有一个重要的理论保证。在表格型(tabular)设定下,CQL 被证明给出了真实 Q 函数的下界(lower bound):即学到的 $\hat{Q}^\pi(s,a) \leq Q^\pi(s,a)$ 对所有 $(s,a)$ 以高概率成立。这个下界性质是 CQL 安全性的理论基础——因为 Q 函数不会高估任何动作,策略选择的高 Q 值动作至少不会比估计的更差。在函数近似设定下,这个理论保证虽然不再严格成立,但实验表明 CQL 在实践中确实能有效地压制 Q 值的过度估计。
实例与类比
CQL 像一个极度保守的房产评估师。面对一套从没交易过的郊区房产(OOD动作),标准评估师可能会参考附近类似房产给出一个估计(可能高估),而 IQL 式的评估师会直接说"我不评估这套,无法给出意见"。CQL 式的评估师则会说"我给它一个估价,但我会故意压低20%"——这样,买家如果基于这个评估做决策,至少不会因为评估过高而付出过高代价。当然,这种保守的代价是可能错过一些真正好的机会——CQL 的"悲观偏置"也可能压低了好但数据中少见的动作的 Q 值。
关键要点
- CQL 的核心策略:主动压低 OOD 动作的 Q 值,而非(像 IQL 那样)避免评估它们
- "悲观"的选择:宁可低估也不要高估——因为高估在离线设定中无法纠正
- 理论保证(表格设定):CQL 学到的 Q 函数是真实 Q 函数的下界
- 论文:Kumar, Zhou, Tucker, Levine. "Conservative Q-Learning for Offline Reinforcement Learning." 2020
→ 让我们通过 Slide 18 的直观图示来理解 CQL 是如何"压低"Q值的——以及为什么这种压低是有益的。
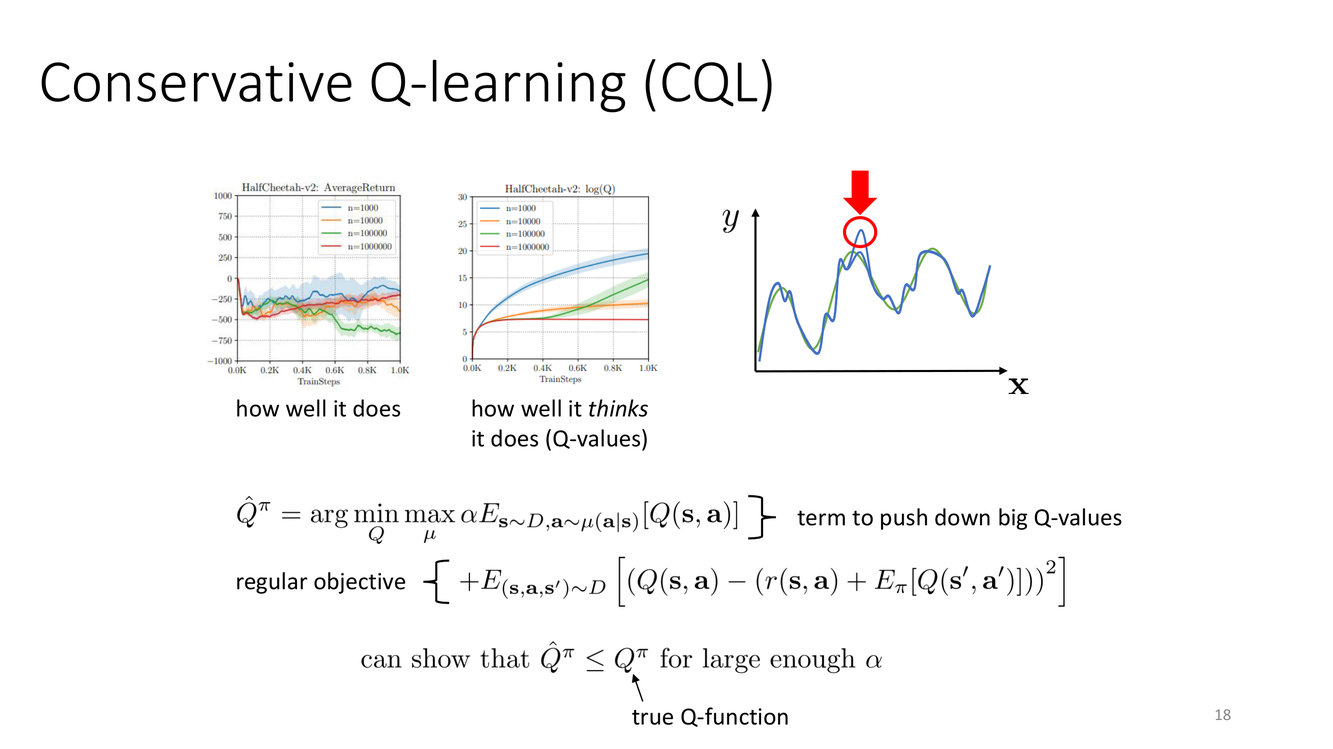
CQL核心思想:压低虚高的Q值
概念详解
Slide 18 用一张对比图直观地展示了 CQL 的动机和工作原理。图的左侧(或上方)展示了标准的 Q-learning 在离线场景中的问题:学到的 Q 函数(学到的 Q 值对应的曲面/曲线)在 OOD 区域显著高于真实 Q 函数(true Q-function)。同时标注了两个关键概念:"how well it thinks it does (Q-values)"(它自认为表现有多好,即学到的 Q 值)和 "how well it does"(它实际表现有多好)。标准 Q-learning 的"自以为"远高于实际表现——这就是过度估计(overestimation)。
CQL 的解决方案是在标准 Bellman 误差损失之上添加一个保守正则化项(regular objective + term to push down big Q-values)。这个正则化项的作用是:选择性地压低那些"虚高"的 Q 值——即对数据集中不常见或未出现的动作的 Q 值进行惩罚,使其回归到更保守的水平。效果是学到的 Q 函数曲线被"压平"下来,更贴近真实 Q 函数。
深度剖析
让我们更深入地分析"Q 值虚高"现象的数学机制。在标准 Q-learning 中,Bellman 最优算子 $\mathcal{B}^*$ 的定义包含了 max 操作:
$$\mathcal{B}^* Q(s,a) = r(s,a) + \gamma \mathbb{E}_{s'}\left[\max_{a'} Q(s', a')\right]$$
重要性质:$\mathcal{B}^*$ 是一个收缩映射(contraction mapping)在 $\infty$-范数下。但当使用函数近似(神经网络)时,我们实际上是在做近似 Bellman 更新——最小化 $\mathbb{E}[(Q(s,a) - \mathcal{B}^* \hat{Q}(s,a))^2]$,其中 $\hat{Q}$ 是目标网络。这种近似引入了一个偏差:$\max$ 操作与函数近似中的误差相互作用,产生系统性的向上偏置(因为 $\mathbb{E}[\max(X_1, ..., X_n)] \geq \max(\mathbb{E}[X_1], ..., \mathbb{E}[X_n])$,Jensen 不等式)。
在在线RL中,这个偏置被环境交互"纠正"——如果策略因為高 Q 值而選擇了某個動作,實際執行的結果會提供糾正信號。但在離線RL中,沒有這種糾正機制,使得高估誤差可以通過 Bellman 備份中的 $\max$ 操作不斷累積和放大。CQL 的保守正則化項直接對抗這個偏置:
$$\mathcal{L}_{\text{CQL}} = \mathcal{L}_{\text{standard TD}} + \alpha \underbrace{\left(\mathbb{E}_{s\sim\mathcal{D}, a\sim\pi}[Q(s,a)] - \mathbb{E}_{(s,a)\sim\mathcal{D}}[Q(s,a)]\right)}_{\text{压低策略动作Q值,抬高数据动作Q值}}$$
這個正則化項具有直觀的幾何意義:它將 Q 函數的"曲面"在數據支持區域"固定"住(通過最大化數據動作的 Q 值),同時在 OOD 區域向下"拉"(通過最小化策略動作的 Q 值)。最終形成一個在數據區域準確、在 OOD 區域保守的 Q 函數。
实例与类比
想象你是一个 AI 简历筛选系统,只基于历史招聘数据(离线数据集)来评估候选人。标准 Q-learning 可能会这样:看到一个候选人的某个特征组合(如"会12种编程语言"),即使历史上从未有人有这个组合,Q 网络也可能给出极高的评分——因为网络的泛化能力将各个特征的正面信号"叠加"了。CQL 则像一个谨慎的 HR:"如果这个特征组合没有出现在历史数据中的优秀员工身上,我会系统性地压低对它的评分"。这样,真正的优秀候选人(他们的特征组合在数据中出现过)不会被那些"看起来很美但未经检验"的组合所淹没。
关键要点
- 标准 Q-learning 在离线场景中产生 Q 值高估——"自以为"远高于"实际"
- 高估的数学根源:$\max$ 操作 + 函数近似误差 → 向上的 Jensen 偏置
- CQL 的解决方案:添加保守正则化项,在数据区域"固定"Q值,在OOD区域"压低"Q值
- 效果:学到的 Q 函数更贴近真实 Q 函数,消除了系统性的高估偏置
- 直觉:"对不了解的事情保持悲观"
→ Slide 19 进一步展开 CQL 正则化项的具体结构:"一边压低,一边抬高"——以及为什么这种不对称设计是必要的。

CQL的双向操作:压低 OOD + 抬高数据内
概念详解
Slide 19 解构了 CQL 保守正则化项的两个组成部分,它们的协同作用是 CQL 有效性的关键:
第一部分:"always pushes Q-values down"(压低策略动作的 Q 值)
$$\mathcal{L}_{\text{push-down}} = \mathbb{E}_{s\sim\mathcal{D}, a\sim\pi(\cdot|s)}[Q(s,a)]$$
这一项对当前策略 $\pi$ 可能选择的动作的 Q 值施加向下的压力。策略 $\pi$ 倾向于选择 Q 值高的动作,因此这一项越低,策略就越被"推开"OOD 区域。需要注意的是,这一项的分布是 $s\sim\mathcal{D}$(状态来自数据)但 $a\sim\pi(\cdot|s)$(动作来自当前策略)——这正是可能产生 OOD 动作的组合。
第二部分:"push up on $(s,a)$ samples in data"(抬高数据内动作的 Q 值)
$$\mathcal{L}_{\text{push-up}} = -\mathbb{E}_{(s,a)\sim\mathcal{D}}[Q(s,a)]$$
这一项对数据集中真实出现过的动作的 Q 值施加向上的压力。如果没有这一项,整个 Q 函数会被压低到任意小的值(因为第一项无差别地压低所有 Q 值),导致 Q 函数失去对数据内动作的区分能力。
两项的组合产生了非平凡的效果:Q 函数在数据支持的区域保持准确(甚至略高),在数据不支持的区域被压低。二者的差——$\mathbb{E}_{a\sim\pi}[Q] - \mathbb{E}_{(s,a)\sim\mathcal{D}}[Q]$——衡量了策略偏离数据分布的程度。
深度剖析
CQL 正则化项的两部分设计体现了一个深刻的权衡:在"压低一切"与"仅压低 OOD"之间找到平衡。如果只有第一部分(压低策略动作 Q 值),而没有第二部分(抬高数据动作 Q 值),Q 函数会退化到对所有动作都给出负无穷大的 Q 值——这在数学上是这个无约束优化问题的唯一解(因为你可以无限压低所有 Q 值来最小化 $\mathbb{E}[Q]$)。第二部分提供了关键的"锚点"——数据中的动作被强制保持一定的 Q 值,策略只能在数据支持的区域内寻找高于锚点的动作。
从优化动力学的角度,两部分的工作方式如下:在训练的早期,Q 函数还未充分学习,策略 $\pi$ 近似随机,因此 $\mathbb{E}_{a\sim\pi}[Q] \approx \mathbb{E}_{(s,a)\sim\mathcal{D}}[Q]$,CQL 正则化项几乎为零。随着 Q 函数逐渐学会区分好动作和坏动作,策略开始偏向高 Q 值动作——这些动作中有些是数据中的(OK),有些可能是 OOD 的(危险)。CQL 正则化项此时激活:压低策略动作的 Q 值(general push down),但保持数据动作的 Q 值(specific push up)。净效应是:OOD 动作的 Q 值下降,数据内动作的 Q 值保持相对稳定。
CQL 论文中给出了这个正则化项的一个等价解释:它等价于在学习 Q 函数之后,在策略评估步骤中最小化一个受约束的目标;或者等价于在标准 Q-learning 的基础上添加了一个分布鲁棒性(distributionally robust)的正则化。
实例与类比
可以把 CQL 的两部分比作一个"评分系统的校准机制"。假设你在用一个 AI 给电影打分。第一部分(压低策略动作)相当于说:"对新导演、新题材的电影,系统性地压低预测评分,因为你没有数据支持"。第二部分(抬高数据动作)相当于说:"但对那些历史上口碑好、数据充足的电影,保持正常的(甚至略高的)评分"。两者的净效应是:AI 不会因为某一部"看起来很有潜力但完全无先例"的独立电影而给出比经典名作更高的评分——这避免了"新东西被过度乐观评价"的偏误。
关键要点
- CQL 正则化有两个互补的组成部分:压低策略动作 Q 值 + 抬高数据动作 Q 值
- 仅有压低项会导致 Q 函数退化到负无穷——抬高项提供了必要的"锚点"
- 组合效果:OOD 动作 Q 值被压低,数据内动作 Q 值保持准确
- 优化动力学:早期训练中正则化几乎为零,随着策略偏好形成逐步激活
- CQL 等价于分布鲁棒优化下的一个特定正则化形式
→ Slide 20 给出了 CQL 的完整算法框图和具体的更新规则——让我们深入其技术细节。

CQL算法详细实现
概念详解
Slide 20 展示了 CQL 的完整算法框图。CQL 可以构建在任何标准的 Actor-Critic 框架之上(如 SAC),通过修改 Critic(Q 函数)的损失函数来实现保守性。完整的 CQL Critic 损失函数为:
$$\mathcal{L}_{\text{CQL}}(\phi) = \mathcal{L}_{\text{TD}}(\phi) + \alpha \left(\mathbb{E}_{s\sim\mathcal{D}}\left[\log\sum_{a}\exp(Q_\phi(s,a))\right] - \mathbb{E}_{(s,a)\sim\mathcal{D}}[Q_\phi(s,a)]\right)$$
其中 $\mathcal{L}_{\text{TD}}$ 是标准的 Bellman 误差,$\alpha$ 是保守系数。注意第一项使用了 log-sum-exp($\log\sum\exp$)来近似 $\max_a Q(s,a)$——这是一种平滑的最大值近似。使用 log-sum-exp 而非直接对策略采样取期望有几个优势:(1) 它覆盖了整个动作空间,而不只是当前策略支持的区域;(2) 它是凸函数,优化更稳定;(3) 它对最大的几个 Q 值特别敏感(正是最容易高估的区域)。
Actor 的更新保持标准形式:最大化 $\mathbb{E}_{s\sim\mathcal{D}, a\sim\pi}[Q(s,a)]$,加上 SAC 的熵正则化项。由于 Critic 已经通过保守正则化对 OOD 动作 Q 值进行了压低,Actor 在最大化 Q 值时自然会避开这些区域——无需在 Actor 端添加额外的约束。
深度剖析
CQL 使用 log-sum-exp 是一个关键的工程选择。log-sum-exp 函数 $\text{LSE}(s) = \log\sum_a \exp(Q(s,a))$ 是 $\max_a Q(s,a)$ 的平滑近似——当 $\max$ 与次大值之间的差距很大时,LSE 几乎等于最大 Q 值;当多个动作的 Q 值接近时,LSE 略高于 $\max$(这是其凸性导致的)。
在连续动作空间中,$\sum_a$ 需要被替换为积分或采样近似。CQL 在实践中通过对当前策略 $\pi$ 和均匀分布 $U(\mathcal{A})$ 的混合采样来近似:
$$\mathbb{E}_{s\sim\mathcal{D}}\left[\log \mathbb{E}_{a\sim\text{mix}(\pi, U)}[\exp(Q_\phi(s,a))]\right]$$
这提供了对"所有可能动作中最大 Q 值"的一个数值上稳定的近似。另一个实践中使用的变体直接用以下形式:
$$\mathcal{L}_{\text{CQL}} = \mathcal{L}_{\text{TD}} + \alpha \left(\mathbb{E}_{s\sim\mathcal{D}, a\sim\pi}[Q(s,a)] - \mathbb{E}_{(s,a)\sim\mathcal{D}}[Q(s,a)]\right)$$
这与 log-sum-exp 形式在效果上类似但实现更简单。CQL 论文通过理论分析证明了这种形式在表格设定下提供了 Q 值的下界保证。
关于超参数 $\alpha$:$\alpha=0$ 恢复标准 Q-learning;$\alpha$ 越大,Q 函数越保守。在实践中,$\alpha$ 通常通过一个 Lagrange 乘子来自动调节——设定一个期望的 Q 值压低程度 $C$,然后通过梯度上升/下降来调节 $\alpha$ 以满足这个约束。这种自适应机制避免了手动调节 $\alpha$ 的繁琐,但也增加了额外的超参数 $C$。
实例与类比
CQL 的 log-sum-exp 方法好比是这样一种评分策略:不是只看"最高分的那个选项"(max),而是看"所有选项的得分分布"。如果只有少数几个选项得分很高,LSE 近似于 max;如果有大量选项得分都中等偏高,LSE 会给出比 max 更高的值——因为它察觉到了"很多选项都还不错,总有一个可能特别好"的风险。这个特性恰好对 OOD 区域最危险的情况特别敏感——当 Q 函数在 OOD 区域系统性地给很多动作中等偏高的分数时,LSE 提供更强的压低压力。
关键要点
- CQL 的 Critic 损失 = TD 误差 + $\alpha(\text{LSE}(Q) - \mathbb{E}_{\mathcal{D}}[Q])$
- log-sum-exp(LSE)是 $\max$ 的平滑凸近似,对多个高 Q 值特别敏感
- 连续动作空间中通过策略 $\pi$ 与均匀分布 $U$ 的混合采样来近似 LSE
- Actor 保持标准更新——保守性完全在 Critic 端实现
- $\alpha$ 控制保守程度,实践中常通过 Lagrange 乘子自适应调节
- $\alpha=0$ 恢复标准 Q-learning
→ CQL 还有一个与最大熵RL框架紧密结合的变体,将保守正则化与熵正则化统一处理。

CQL 与最大熵正则化的结合
概念详解
Slide 21 展示了 CQL 与最大熵RL(MaxEnt RL, 即 SAC 框架)的自然结合。在 MaxEnt RL 中,标准的目标是最大化 $\mathbb{E}[\sum_t \gamma^t (r_t + \mathcal{H}(\pi(\cdot|s_t)))]$,其中 $\mathcal{H}$ 是策略的熵。CQL 在这个框架上叠加了保守正则化,其完整损失函数融合了三个组件:
组件一:标准 SAC 的 Bellman 误差
$$\mathcal{L}_{\text{SAC}} = \mathbb{E}_{(s,a,r,s')\sim\mathcal{D}}[(Q(s,a) - (r + \gamma \mathbb{E}_{a'\sim\pi}[Q(s',a') - \log\pi(a'|s')]))^2]$$
这里的 Bellman 目标包含了熵项 $-\log\pi(a'|s')$。
组件二:CQL 保守正则化
$$\mathcal{L}_{\text{CQL-reg}} = \alpha \left(\mathbb{E}_{s\sim\mathcal{D}}[\log\sum_a \exp(Q(s,a))] - \mathbb{E}_{(s,a)\sim\mathcal{D}}[Q(s,a)]\right)$$
组件三:最大熵正则化(来自 SAC)
$$\mathcal{L}_{\text{ent}} = -\mathbb{E}_{s\sim\mathcal{D}, a\sim\pi}[\log\pi(a|s)]$$
(这通常包含在 Actor 的损失中而非 Critic 的损失中,但在 MaxEnt 框架下,它与 Critic 的 Bellman 目标中的熵项相互配合。)
这三者的结合产生了双重正则化的效果:熵正则化鼓励探索(保持动作多样性),保守正则化压制 OOD 动作的 Q 值。两者在数学上互补——熵正则化防止策略过早塌缩到次优解,保守正则化防止策略被虚高的 Q 值误导。
深度剖析
CQL + SAC 的组合是实践中离线RL最常用的配置之一。熵正则化在这里扮演了一个微妙但关键的角色。在纯 CQL(无熵正则化)中,保守的正则化可能导致策略变得过度确定(overly deterministic)——因为压低 OOD 动作 Q 值的副作用是策略更倾向于选择"最安全"(数据中最常见)而非"最优"的动作。熵正则化通过鼓励策略保持一定程度的随机性,在"安全"和"探索"之间引入了张力:
策略优化的目标:
$$\max_\pi \mathbb{E}_{s\sim\mathcal{D}, a\sim\pi}[Q_{\text{conservative}}(s,a) + \beta \mathcal{H}(\pi(\cdot|s))]$$
其中 $Q_{\text{conservative}}$ 是经过 CQL 保守正则化后的 Q 函数,$\beta$ 是熵系数(在 SAC 中可通过自动温度调节来学习)。
这种组合在实践中展现了令人瞩目的鲁棒性。在 D4RL 基准测试中,CQL(+SAC) 在大多数任务上排名前二(与 IQL 竞争),特别是在数据质量较低的"medium"和"medium-replay"数据集上表现出色——这正是保守偏置价值最大的场景。对于"expert"数据集(数据质量高),CQL 的保守偏置可能稍微过于保守,略微限制了策略的表现天花板。
实例与类比
如果把 CQL 的保守正则化比作汽车的刹车系统(防止超速),那么 SAC 的熵正则化就是差速器(允许左右轮在不同速度下运转)。刹车确保你不会冲向未知道路(OOD区域),差速器确保你在已知道路上能灵活转弯(允许策略在好动作之间保持多样性)。两者结合,既安全又不笨拙。没有刹车你可能冲出赛道,没有差速器你可能在弯道上卡住——两者缺一不可。
关键要点
- CQL + SAC = 标准SAC Bellman误差 + CQL保守正则化 + 熵正则化
- 双重正则化:保守正则化保证安全性,熵正则化保证策略灵活性
- 在 D4RL 基准上,CQL(+SAC) 是表现最强的离线RL算法之一
- 在低质量数据(medium, medium-replay)上优势尤为明显
- 在高质量数据(expert)上可能过于保守,略微限制表现上限
→ 我们现在转向一个更实际的议题:在实际应用中,离线RL通常不是终点——我们需要将离线预训练的策略迁移到在线环境进行微调。这就是第四部分:离线到在线RL。
第4章:离线到在线强化学习 — Offline-to-Online RL

第四部分引言:离线到在线RL
概念详解
第四部分将视角从纯粹的离线RL扩展到离线到在线RL(Offline-to-Online RL)。在真实的工业应用中,纯粹的离线RL(训练完成后直接部署,不再与环境交互)实际上是很少见的。更常见的工作流程是:先利用大量的历史数据(离线数据集)对策略进行预训练,然后将策略部署到真实环境中进行在线微调(fine-tuning),以进一步提升性能并适应部署环境的特异性。
这种两阶段流程带来了独特的挑战:离线阶段学到的保守偏置——那些使离线RL有效的东西——可能在在线微调阶段成为阻碍。例如,CQL 的低估偏置在离线阶段保护策略不被虚高 Q 值误导,但在在线阶段,这种低估可能导致策略对新环境反馈"过于谨慎",需要大量在线数据来"纠正"Q 函数的低估。如何在离线安全性与在线适应性之间取得平衡,是这一部分要探讨的核心问题。
深度剖析
离线到在线RL暴露了离线RL算法的一个根本张力:离线RL方法的有效性往往与其在线微调的效率成反比。越保守的方法(如 CQL 的高 $\alpha$ 值)在纯离线场景中越安全,但在切换到在线微调时,需要越多的在线数据来"解除"保守偏置。反之,越不保守的方法(如 AWAC)在离线场景中风险更高(如果 Q 函数不够准确),但切换到在线微调时适应更快。
这个张力产生了一个有趣的问题:是否存在一个"统一的"算法,既能在离线阶段保持保守,又能在在线阶段快速适应?Levine 教授在这一部分将呈现的观点是:(1) 在理论上,这样的统一算法可能不存在或极难设计;(2) 在实践中,一个极其简单的方法——混合离线数据和在线数据的回放缓冲——出人意料地有效;(3) 扩散模型(diffusion models)作为策略表示在离线到在线RL中展现了意外的优势。
实例与类比
离线到在线RL好比这样的场景:一个医生先在医学院通过课本和病例研究(离线数据)学习诊断技能,然后进入临床实习(在线微调)。在医学院形成的保守诊断习惯("先排除常见病")在课本学习中保护学生不犯大错,但进入临床后,需要快速调整以适应真实病人的复杂性。有些学习方法(如死记硬背——类比极端保守的 CQL)在课本学习中表现很好,但临床适应慢;另一些(如基于第一性原理的推理——类比 AWAC)可能在课本学习中不够安全,但临床适应快。
关键要点
- 离线到在线RL是工业实际中最常见的工作流程:离线预训练 → 在线微调
- 核心张力:离线保守性 vs 在线适应性——两者往往此消彼长
- 本部分的三个议题:(1) 过渡问题本质;(2) 极其简单但有效的方法;(3) 扩散模型的意外优势
- 统一离线与在线阶段的算法设计是一个开放性难题
→ 先来俯瞰离线到在线RL的宏观图景——这个两阶段流程的理想形态是什么?
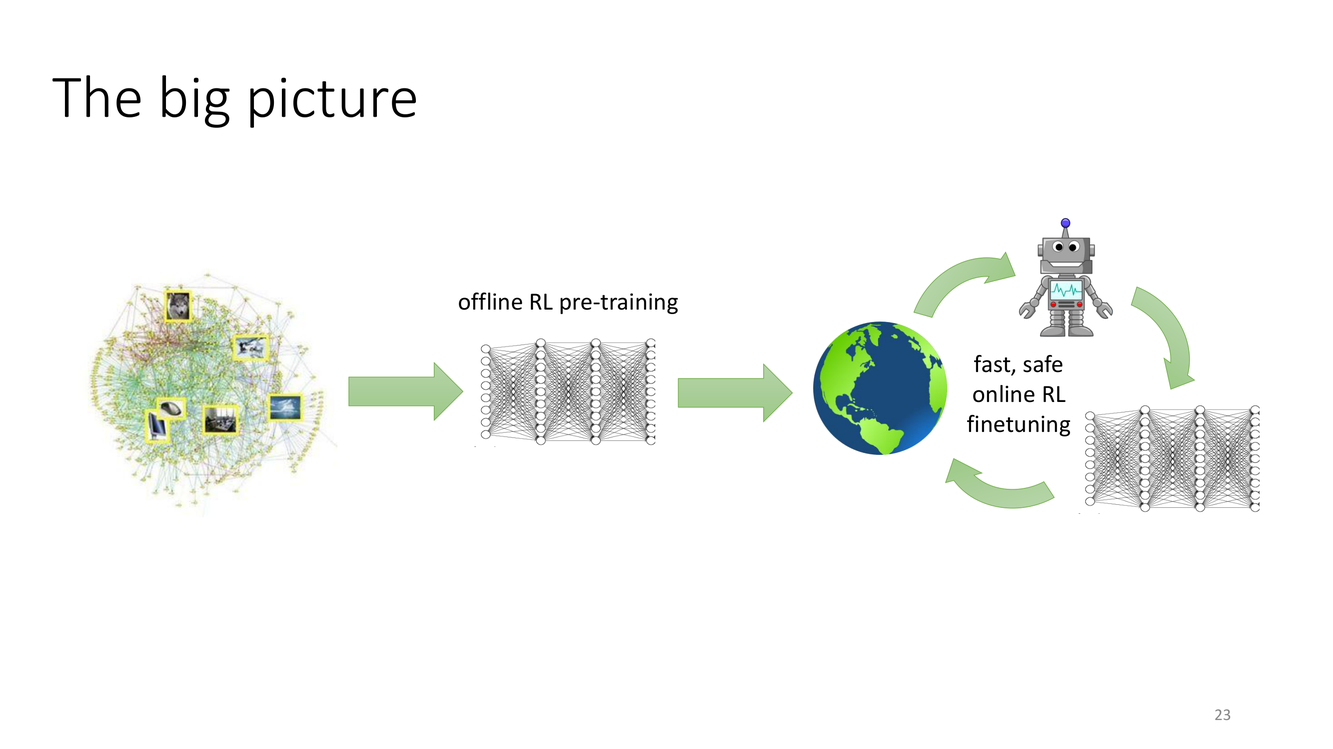
宏观图景:离线预训练 + 在线微调
概念详解
Slide 23 描绘了离线到在线RL的理想化流程。图示分为两个阶段:左侧是离线RL预训练(offline RL pre-training)——利用静态数据集训练策略和价值函数,以安全的方式(保守估计、策略约束等)学到一个不错的初始策略;右侧是在线RL微调(fast, safe online RL finetuning)——将预训练的策略部署到真实环境中,通过在线交互快速提升性能,同时保持安全性。
这个流程的"理想"在于:(1) 离线预训练提供了一個不差的起點,大幅減少在線訓練所需的環境交互次數(這在機器人、醫療等高成本領域至關重要);(2) 在線微調應該是"快速"的(樣本效率高)和"安全"的(不會因為探索導致災難性失敗);(3) 從離線到在線的過渡應該是平滑的——沒有性能斷崖。然而,這些理想的屬性在实践中的实现面臨著實質性的困難。
深度剖析
從信息論的角度看,離線到在線RL的過渡涉及一個信息源切換。在離線階段,算法依賴於一個固定的數據集——這是一個靜態信息源,其信息量和覆蓋範圍是有限且不可增長的。在在線階段,算法可以主動選擇去收集哪些信息——這是一個動態信息源,信息量可以通過探索策略來控制。關鍵挑戰在於:離線階段學到的模型(Q函數、策略、可能的環境模型)是基於靜態信息源訓練的,它們在被切換到動態信息源時可能產生分佈外泛化誤差。
具體來說,離線階段學到的 Q 函數可能在數據集覆蓋良好的區域非常準確,但在數據集未覆蓋的區域(這些區域恰恰是在線階段策略可能探索到的)存在很大的不確定性。如果策略在在線階段早期就大膽地探索這些不確定區域,Q 函數的誤差可能導致策略走入歧途,需要大量額外的在線數據來修正。這就是 Slide 24 將要展示的"性能低谷"問題。
实例与类比
這個兩階段流程可以類比為飛行員培訓的兩個階段:地面模擬器訓練(離線預訓練)和實際飛行訓練(在線微調)。地面模擬器提供了大量安全的練習機會,飛行員可以在這裡學到基本操作(離線策略)。但模擬器無法完美複製真實飛行的所有方面——氣流、突發狀況、感官反饋。因此,需要在真實飛行中進行微調。理想情況下,地面訓練應該讓飛行員在第一次真實飛行時就表現得不錯(沒有性能斷崖),並且能在少量真實飛行後達到熟練水平(樣本效率高)。
关键要点
- 離線到在線RL的理想:離線預訓練提供好起點 → 在線微調快速安全地提升
- 信息論視角:離線階段是靜態信息源,在線階段是動態信息源
- 核心挑戰:離線學到的模型在切換到動態信息源時的分佈外泛化誤差
- 理想屬性:平滑過渡(無性能斷崖)、高樣本效率、探索安全
→ 理想很豐滿,現實很骨感。Slide 24 用具體的實驗數據展示了離線到在線過渡中實際發生的"性能低谷"。
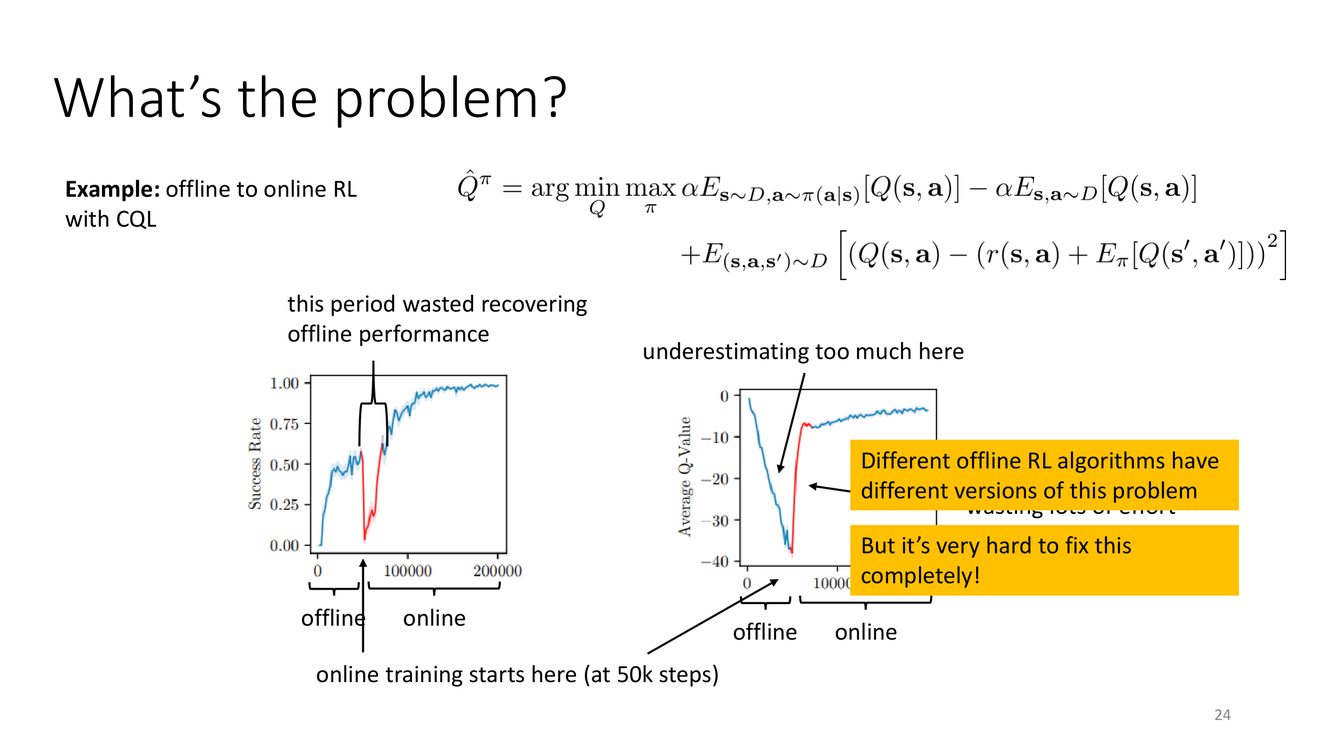
問題診斷:離線到在線的"性能低谷"
概念详解
Slide 24 用 CQL 的實驗數據生動地展示了離線到在線RL面臨的核心問題。圖中兩條曲線對比了"純離線"(offline,即繼續只使用離線數據訓練)和"離線到在線"(offline→online,從50k步開始接入在線數據)的表現隨訓練步數的變化。
關鍵觀察點:(1) 在線訓練的起點(50k步處,即 offline pre-training 結束、online fine-tuning 開始的時刻),策略的表现已经达到了离线阶段的水平;(2) 然而,一旦開始在線微調,性能立即經歷了一個顯著的下降——"this period wasted recovering offline performance"(這段時間浪費在恢復離線性能上);(3) 性能下降後需要相當長的時間才能恢復並超越離線階段的表現。
Levine 教授為這種現象給出了診斷:"underestimating too much here, wasting lots of effort recalibrating the value function"——CQL 的保守偏置在離線階段壓低了 Q 值以保證安全,但在在線階段,這種壓低成為了"矯枉過正"——策略過於悲觀,需要大量在線數據來"重新校準"(recalibrate)價值函數。
深度剖析
這個"性能低谷"現象揭示了離線到在線RL中的一個關鍵困境:離線階段越保守的方法,在在線階段的"校準成本"越高。CQL 通過系統性地壓低 OOD 動作的 Q 值來實現安全性,但這同時意味著:對於那些在數據中不常見但在真實環境中是好選擇的動作,CQL 也傾向於給出低估的 Q 值。當策略進入在線階段,它可以實際嘗試那些之前被低估的動作,發現它們實際上很好——但這需要時間和數據。
更具體地說,CQL 的保守正則化項 $\mathbb{E}_{s\sim\mathcal{D}}[\log\sum_a \exp(Q)] - \mathbb{E}_{(s,a)\sim\mathcal{D}}[Q]$ 在離線階段強制 Q 函數的低估偏置。但在在線階段,新的數據流迫使 Q 函數進行"矛盾"的調整:一方面,CQL 正則化(如果繼續施加的話)試圖保持低估;另一方面,新的真實獎勵信號(特別是高獎勵的軌跡)試圖提高 Q 值。這兩股力量之間的衝突導致了 Q 函數的震盪和性能的短期下降。
Levine 教授坦率地指出:"Different offline RL algorithms have different versions of this problem, but it's very hard to fix this completely!"——不同的離線RL算法都有各自版本的性能低谷問題,而且從根本上完全消除這個問題極其困難。
实例与类比
這好比一個極為謹慎的投資者。在只依靠歷史數據進行紙上交易時(離線階段),他形成了"新興市場風險極高,盡量避免"的保守策略——這在純歷史分析中是合理的。但當他開始真金白銀地交易(在線階段),實際市場經驗告訴他某些新興市場其實很穩健。然而,要讓他的保守模型"相信"這一點,需要積累相當多的盈利經驗來抵消根深蒂固的保守偏見。在這個"積累證據"的過程中,他錯失了一些好機會——這就是"性能低谷"。
关键要点
- 在線微調開始時策略性能會經歷明顯下降——需要時間恢復離線階段的表現水平
- 診斷原因:CQL 的低估偏置需要在線數據來"重新校準"
- 越保守的離線方法,在線校準成本越高——這是一個根本性的權衡
- Levine 教授的坦率評價:"very hard to fix this completely"
- 性能低谷是離線到在線RL最核心的未解決問題之一
→ 性能低谷問題引出了一個更深層的追問:是否存在一個"終極算法",能同時在離線和在線階段都表現出色?
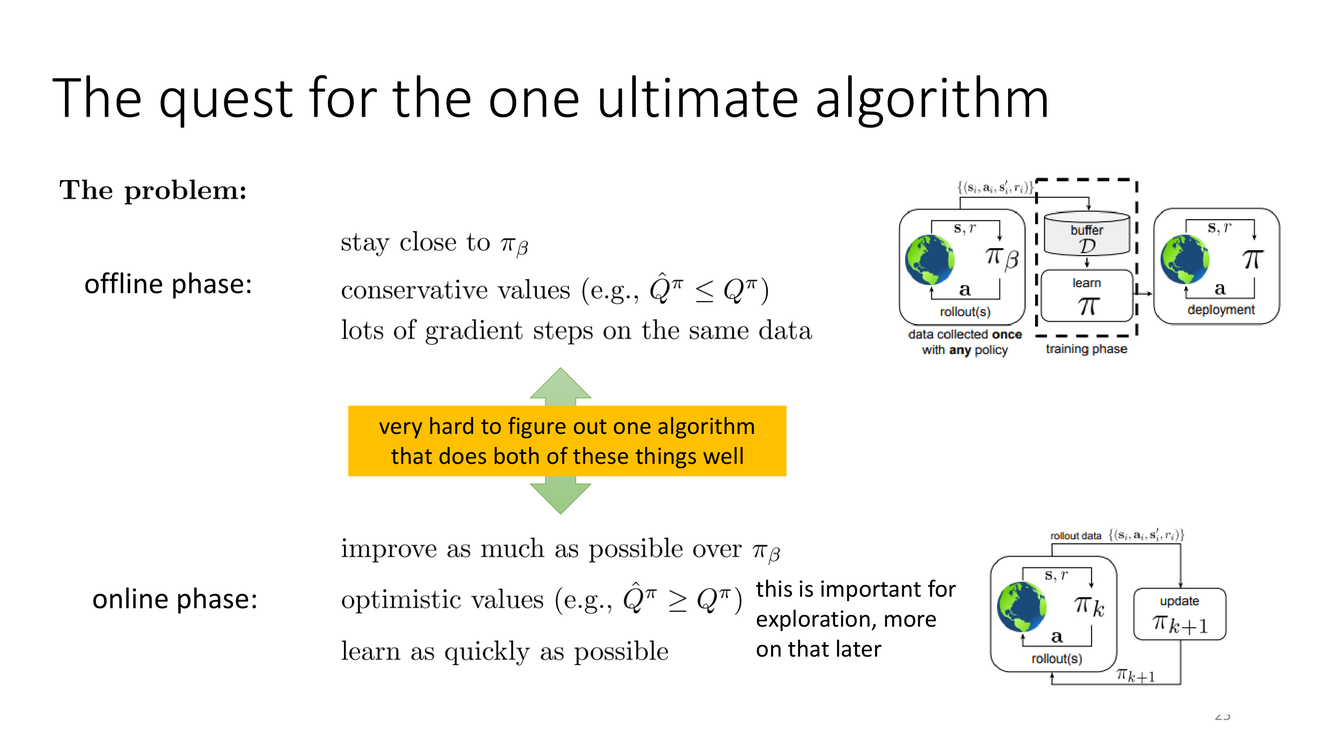
終極算法的追求:一個算法統治兩個階段?
概念详解
Slide 25 直面了一個根本性的問題:能否設計一個算法,同時在離線和在線兩個階段都表現出色?Levine 教授將離線和在線階段對算法的要求並列對比,揭示了兩者之間的根本矛盾。
離線階段的要求:算法需要保持保守——避免 OOD 動作、壓低虛高的 Q 值、確保策略不偏離數據支持。核心關注點是防止災難性過度估計。
在線階段的要求:算法需要樂觀地探索——對於不確定的區域,需要"樂觀地面對不確定性"(optimism in the face of uncertainty),這是高效在線探索的基礎(如 UCB 類方法)。核心關注點是高效的探索。
"very hard to figure out one algorithm that does both of these things well"——Levine 教授承認設計一個統一的算法來平衡這兩種矛盾的需求極其困難。這本質上是因為離線RL需要悲觀主義(pessimism),而在線RL的探索需要樂觀主義(optimism)——這兩種原則在面對不確定性時的方向是相反的。
深度剖析
悲觀主義 vs 樂觀主義的對立是理解離線到在線RL困境的理論鑰匙。在不確定性面前:
悲觀主義(離線RL):對於不確定或未見的動作,假設最壞情況。數學表現為:$\hat{Q}(s,a) = Q(s,a) - \beta \cdot u(s,a)$,其中 $u(s,a)$ 是對 $(s,a)$ 不確定性的度量(如 ensemble Q 函數的方差),$\beta > 0$。(這與 CQL 的保守正則化、MOPO 的不確定性懲罰一致。)
樂觀主義(在線探索):對於不確定或未見的動作,假設最好情況。數學表現為:$\hat{Q}(s,a) = Q(s,a) + \beta \cdot u(s,a)$,其中 $\beta > 0$。(這是 UCB、Bootstrapped DQN 等方法的基礎。)
符號的翻轉($-\beta$ vs $+\beta$)暴露了深層的不可調和性:沒有單一的 $\beta$ 能在兩個階段都最優。這一困境指向了一種可能的解決方案:階段感知的自適應機制——在離線階段使用較大的正 $\beta$(悲觀),在過渡到在線階段時逐漸減小甚至翻轉 $\beta$ 的符號(變為樂觀)。但設計這樣的自適應機制在實踐中極具挑戰性,因為很難準確判斷"何時應該從悲觀切換到樂觀"。
实例与类比
一個新手醫生在只讀課本時(離線階段)應該對罕見病的診斷保持謹慎(悲觀)——"如果症狀不明確,不要輕易診斷為罕見病"。但當他積累了足夠的臨床經驗後(在線階段),應該開始對某些模式保持警覺(樂觀的探索)——"這個症狀組合之前沒見過,可能是新的疾病亞型"。問題在於:何時從"謹慎的初學者"轉變為"自信的探索者"?太早轉變可能導致誤診(性能低谷),太晚轉變可能限制成長速度。
关键要点
- 離線階段需要悲觀主義(pessimism),在線探索需要樂觀主義(optimism)——兩者本質上矛盾
- 悲觀主義:$\hat{Q} = Q - \beta u$;樂觀主義:$\hat{Q} = Q + \beta u$
- 符號的翻轉暴露了深層的不可調和性
- 潛在解決方案:自適應機制在兩階段之間平滑過渡 $\beta$ 的符號和大小
- Levine 教授的誠實評價:設計統一的"終極算法"極其困難
→ 然而,在追求"終極算法"的焦慮之外,一個極其簡單的方法出人意料地有效——甚至很難被任何"正規"的離線到在線方法擊敗。
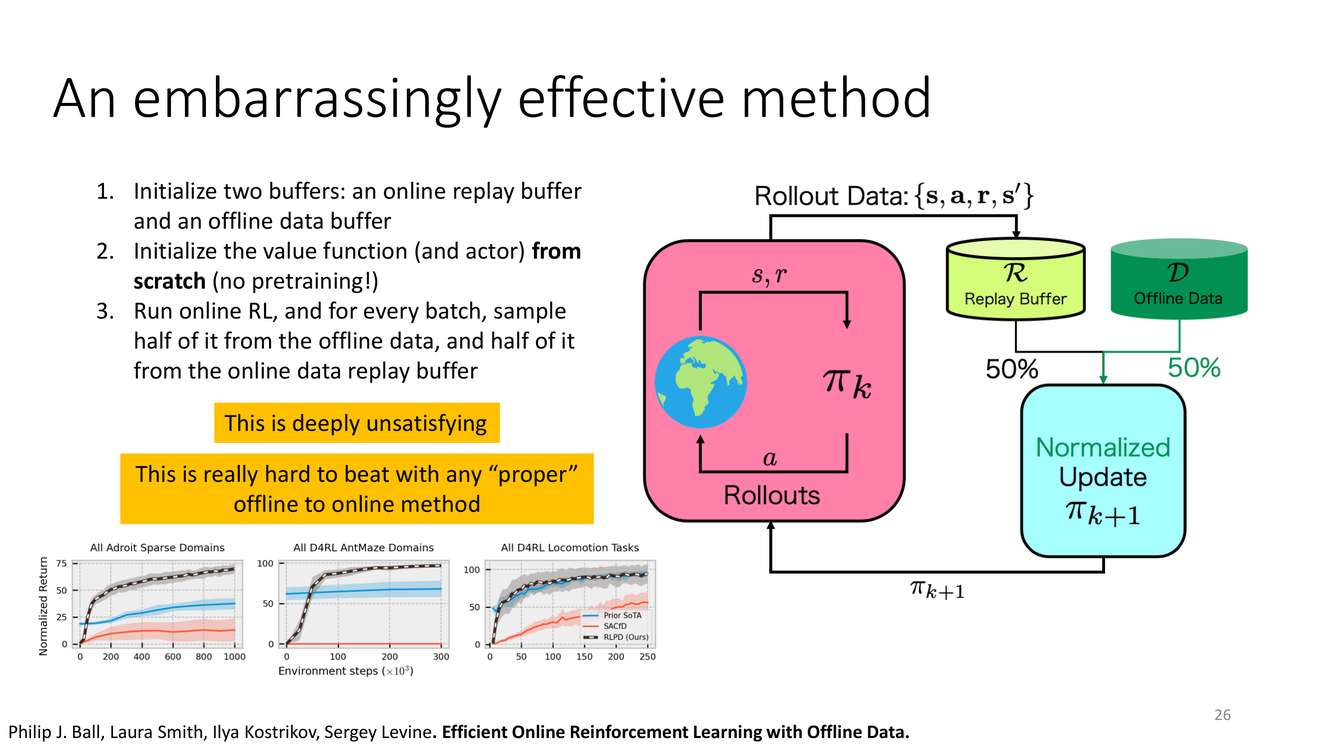
尷尬但極其有效:混合緩衝的簡單方案
概念详解
Slide 26 介紹了 Philip J. Ball, Laura Smith, Ilya Kostrikov, Sergey Levine 提出的方法("Efficient Online Reinforcement Learning with Offline Data"),其核心思想簡單到令人尷尬——但極其有效,以至於很難被任何"正規"的離線到在線方法擊敗。方法僅有三步:
(1) 初始化兩個回放緩衝區:一個在線回放緩衝(online replay buffer)和一個離線數據緩衝(offline data buffer)。
(2) 從零開始初始化價值函數和 Actor:不使用任何離線預訓練!
(3) 運行標準在線RL:對於每一個訓練批次,從離線數據中採樣一半,從在線數據緩衝中採樣一半。
就是這樣——沒有預訓練權重、沒有保守正則化、沒有策略約束。僅僅是在在線訓練時用離線數據"稀釋"每一批的採樣。Levine 教授坦率地評價:"This is deeply unsatisfying"(這在知識上令人深感不滿——因為它沒有回答"為什麼"這個方法有效),"This is really hard to beat with any 'proper' offline to online method"(它真的很難被任何正規的離線到在線方法擊敗)。
深度剖析
這個"尷尬但有效"的方法為我們提供了關於離線到在線RL的深刻洞見。為什麼從零開始訓練 + 混合採樣能打敗精心設計的預訓練 + 微調流程?我認為有以下幾個因素在起作用:
1. 消除了"價值函數重新校準"問題:因為不從預訓練權重開始,所以不存在"離線階段的保守偏置需要在線數據來修正"的問題。Q 函數從一開始就同時接觸離線和在線數據,它的偏置是均衡的而非一邊倒的。
2. 離線數據作為"正則化錨點":從在線數據緩衝中學習時,Q 函數可能因為在線數據的有限覆蓋而產生高方差或過度估計。離線數據(特別是大量、多樣化的離線數據)提供了穩定的"背景信息",防止 Q 函數過度擬合少量的在線數據。
3. 避免了"災難性遺忘":離線預訓練 + 在線微調的範式可能類似於持續學習(continual learning)中的災難性遺忘問題——在微調時,網絡可能"忘記"離線階段學到的有用表徵。從零開始訓練則徹底繞開了這個問題。
4. 簡單性的力量:這個方法沒有任何需要精細調節的過渡機制(如"何時從悲觀切換到樂觀"),因此沒有因調參不當而引入的性能損失。
实例与类比
假設你要學習一門新語言。傳統的"離線預訓練 + 在線微調"範式好比先花三個月死記硬背課本(離線階段建立"保守"的語法模型),然後去當地國家實踐(在線階段修正課本模型的偏差)。而 Ball et al. 的方法好比從第一天開始就在當地國家生活,但每天保留一半時間回顧課本。令人驚訝的是,後者的學習速度和使用效果可能更好——因為你的語言模型從一開始就是基於真實語言環境建立的,課本只是補充信息,而不是需要被"修正"的基礎。
关键要点
- 方法極簡:兩個緩衝區(離線+在線),從零初始化,每批混合採樣50/50
- 無離線預訓練、無保守正則化、無策略約束、無過渡機制
- "This is deeply unsatisfying"——它在知識上沒有解釋"為什麼有效"
- "This is really hard to beat"——作為基線,它的性能出人意料地強大
- 洞見:離線數據應該作為"持續的正則化錨點"而非"一次性預訓練材料"
→ 除了混合緩衝這個"簡單粗暴"的方法外,另一個出人意料的方向是使用擴散模型(diffusion models)作為策略表示——它們在離線到在線RL中展現了意外的優勢。

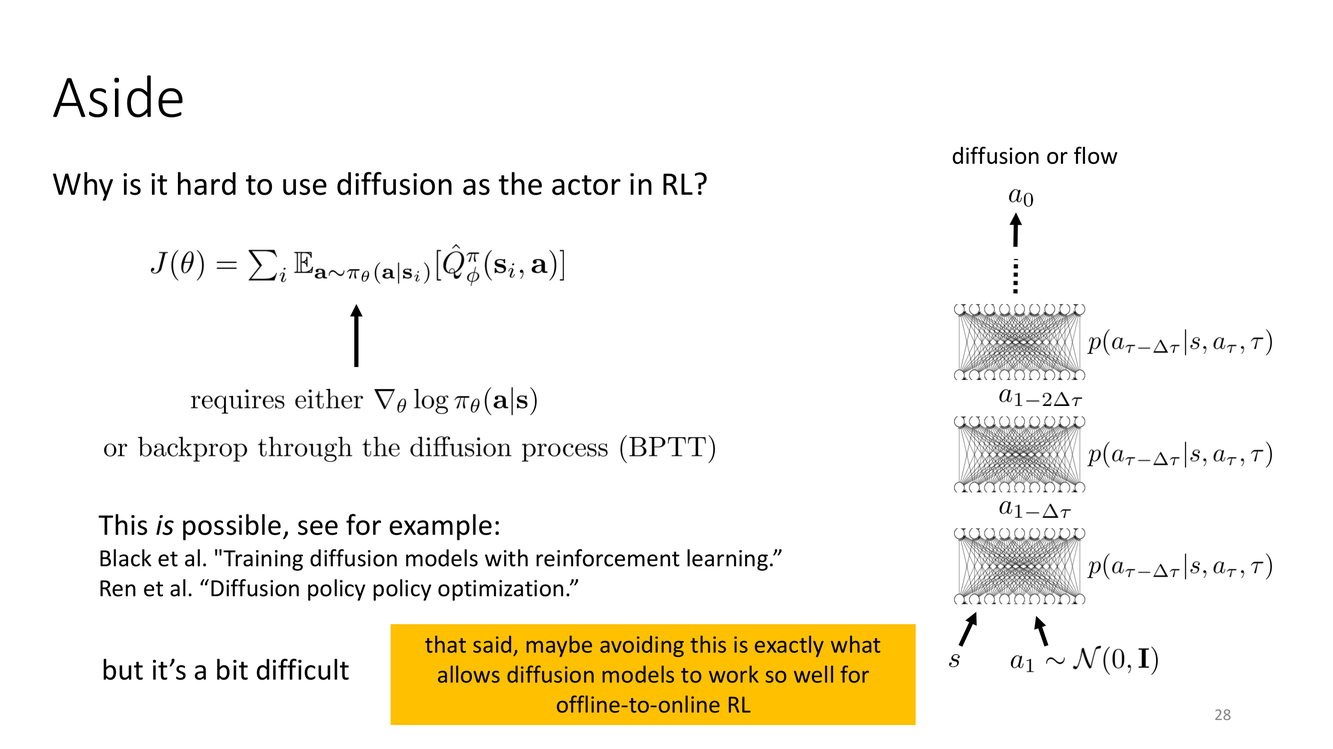
擴散模型:跨界到RL的意外英雄?
概念详解
Slides 27-28 討論了一個近期的趨勢:使用擴散模型(diffusion models)或流匹配(flow matching)來表示策略(actor)。擴散模型是一類生成模型,通過學習從噪聲到數據的去噪過程來生成樣本。在RL中,擴散策略 $\pi_\theta(a|s)$ 不直接輸出動作,而是將狀態 $s$ 作為條件,通過迭代去噪從噪聲中生成動作 $a$。
Levine 教授觀察到一個有趣的現象:"For some reason, algorithms that use diffusion models or flow matching to represent the actor tend to make this work better"——使用擴散/流匹配作為策略表示的方法,在離線到在線RL中表現得意外地好。但他也坦承:"I don't know exactly why that's the case"——並不完全理解為什麼。
Slide 28 進一步解剖了為什麼用擴散模型做RL Actor本身是困難的。"Why is it hard to use diffusion as the actor in RL?"——因為訓練擴散模型通常需要通過其迭代去噪過程進行反向傳播(backpropagating through the denoising chain),這在計算上是昂貴的且梯度可能不穩定。然而,"surprisingly, many of the offline-to-online RL methods we'll discuss only train the diffusion/flow model with supervised learning!"——令人驚訝的是,許多有效的離線到在線RL方法只用監督學習(即行為克隆)來訓練擴散策略,完全避免了RL訓練擴散模型的困難。
深度剖析
擴散模型在離線到在線RL中的成功隱含了一個重要的方法論轉向。傳統 Actor-Critic 的邏輯是"策略通過優化來提升"——Actor 被訓練來最大化 Q 值。而擴散策略的方法則不同:策略通過更好的表示來提升。
擴散模型的關鍵優勢可能在於:
1. 多模態建模能力:行為數據通常是高度多模態的(同一狀態下可能有多種合理動作)。高斯策略(標準 SAC/TD3 的 Actor)只能捕捉單一模式,而擴散模型天然適合建模複雜的多模態分佈。"no need to capture multiple modes"——擴散模型不需要刻意去"捕捉"多個模式,這對它們來說是自然而然的事。
2. 分佈內生成的保證:如果擴散模型是在離線數據上通過監督學習(BC)訓練的,它生成的樣本自然傾向於落在訓練分佈內——這恰好實現了"策略約束"的效果,但不需要任何顯式的散度計算或 Lagrange 乘子。
3. 平滑的過渡特性:在從離線(純BC訓練的擴散策略)到在線(Q值引導的擴散策略或混合訓練)的過渡中,擴散模型的生成過程提供了一個天然的"平滑性"——小的條件變化(如 Q 值的引導)導致小的生成分佈變化,使得過渡更平穩。
Levine 教授提到的"that said, maybe avoiding this is exactly what allows diffusion models to work so well for offline-to-online RL"——正是因為避開了用RL訓練擴散模型的複雜性(只用監督學習),擴散策略反而在離線到在線場景中表現出色。這是一個有趣的"不做比做更好"的案例。
实例与类比
傳統的高斯策略 Actor 好比一個只會給出"平均"建議的參謀——在多模態情況下,它會給出一個在各模式之間的加權平均,最終的建議不在任何模式上。擴散策略則好比一個能同時理解多種戰術風格的參謀——對於同一個戰場態勢,它既能給出"保守推進"的方案,也能給出"大膽突擊"的方案,而且是從訓練中真實見過的方案中"選"出來的(而非平均出來的)。Battle-tested 的經驗表明:在實際戰爭中(在線RL),能提供多個有明確來源的方案比提供一個折中方案更有價值。
关键要点
- 擴散模型/流匹配作為策略表示在離線到在線RL中意外地表現出色
- 可能原因:多模態建模能力、自然的"分佈內生成"約束效果、平滑的過渡特性
- 用RL訓練擴散模型很困難(需要通過去噪鏈反向傳播),但很多有效方法只用監督學習訓練擴散策略
- "不做比做更好"——避免RL訓練擴散模型的複雜性,反而獲得更好的離線到在線表現
- Levine 教授誠實地承認不完全理解為什麼這有效——這是活躍的研究方向
→ 讓我們具體看看兩個代表性的擴散策略離線到在線RL方法:IDQL 和 FQL。

IDQL:隱式Q學習遇上擴散策略
概念详解
IDQL(Implicit Q-Learning as an Actor-Critic Method with Diffusion Policies)由 Hansen-Estruch, Kostrikov, Janner, Grudzien, Levine 提出,它優雅地將 IQL 的價值學習框架與擴散策略結合起來。
回顧 IQL 的三步驟:(1) 用期望回歸學 $V_\psi$——逼近數據支持集下 Q 值的上分位數;(2) 用 SARSA 風格的 TD 學習更新 $Q_\phi$;(3) 用優勢加權回歸提取策略 $\pi_\theta$。IDQL 保持了前兩步不變,但在第三步將標準的高斯策略替換為擴散策略。擴散策略的訓練目標仍然是在數據集上做加權最大似然,權重由 $\exp(A/\alpha)$ 給出:
$$\max_\theta \mathbb{E}_{(s,a)\sim\mathcal{D}}\left[\exp\left(\frac{A(s,a)}{\alpha}\right) \cdot \log p_\theta(a|s)\right]$$
但這裡 $\log p_\theta(a|s)$ 是擴散模型的對數似然(通過去噪得分匹配來近似),而非簡單的對角高斯對數似然。
Levine 教授提出了兩個引導性問題:"why is this good?"和"why is this bad?"——鼓勵學生批判性地思考 IDQL 的優劣。好的方面:擴散策略的多模態能力使其能更好地捕獲行為數據中的多模態結構,加權最大似然自然地實現了"從數據中選擇好模式"而非"創造新模式"。不好的方面:擴散模型的推斷速度(需要迭代去噪)遠慢於高斯策略的單步前向傳播;訓練計算開銷大;而且在在線微調時如何"引導"擴散策略朝向更高 Q 值區域仍然是一個未完全解決的問題。
深度剖析
IDQL 的設計中,最精妙的地方在於它完全避免了用 RL 訓練擴散模型。擴散策略的訓練僅僅是(加權)監督學習——對數據中的動作做(加權)去噪得分匹配。這意味著:(1) 沒有策略梯度通過去噪鏈反向傳播的問題;(2) 擴散模型生成的動作天然地落在訓練分佈的支持集內(只要去噪過程是在訓練分佈上學習的)。
這種設計有效地將"策略提升"的責任從策略網絡本身轉移到了價值函數上:IQL 的 $V_\psi$(通過期望回歸)負責識別"數據中哪些動作是好的",而擴散策略只是負責"將這些好動作的生成模式學到手"。這種分工——價值函數負責"判斷"(evaluation),擴散策略負責"生成"(generation)——避免了 Actor-Critic 中 Actor 通過 Q 值梯度"想像"新動作的風險。
在在線微調階段,IDQL 可以選擇:(a) 繼續使用加權 BC(安全但保守),(b) 開始使用某種形式的 Q 值引導(探索但風險更高),或 (c) 如 Ball et al. 那樣用混合緩衝進行標準在線 RL。擴散策略的生成靈活性為這些選擇提供了空間。
实例与类比
IDQL 好比一個"精品選品店"的商業模式。價值函數(V/Q)是市場分析師——它不"創造"新產品,而是分析現有產品中哪些賣得好(期望回歸識別高Q值動作)。擴散策略是產品設計師——它不是"發明"全新的產品類型,而是基於分析師的反饋,將"好產品"的設計元素提煉並重新組合(加權去噪得分匹配)。這種"分析→提煉"的模式比"分析→憑空創造"(傳統Actor-Critic)更不容易出錯,因為每一步都在已知的領域內操作。
关键要点
- IDQL = IQL的價值學習框架 + 擴散策略替代高斯策略
- 擴散策略完全用(加權)監督學習訓練,避免RL訓練擴散模型的困難
- 優勢:多模態行為建模、自然的"分佈內生成"、與IQL框架無縫集成
- 劣勢:推斷速度慢(迭代去噪)、訓練計算開銷大、在線引導機制未完全解決
- 分工哲學:價值函數"判斷" + 擴散策略"生成",各司其職
→ IDQL 使用擴散策略進行"純生成",而 FQL 則採用了一種不同的策略——讓一個普通神經網絡 Actor"靠近"擴散模型的行為分佈。

FQL:讓普通 Actor "靠近"擴散模型
概念详解
FQL(Flow Q-Learning)由 Park, Li, Levine 提出,採用了一種與 IDQL 互補的策略來利用擴散模型的優勢,同時避開其劣勢。IDQL 直接用擴散模型作為策略,推斷時需要迭代去噪。FQL 則採用了一種更靈活的架構:
離線階段:(1) 用標準 BC 在數據集上訓練一個擴散/流匹配行為模型(diffusion/flow behavior model)$\mu(a|s)$——這是一個純生成模型,捕捉行為分佈的多模態結構;(2) 訓練一個普通神經網絡 Actor $\pi_\theta(a|s)$(如 MLP),這個 Actor 的輸入包括一個隨機噪聲 $z$("this actor is not a diffusion model! It's just a regular neural net that takes in z");(3) Actor 的訓練目標是最大化 $\mathbb{E}_{s\sim\mathcal{D}, z\sim p(z), a=\pi_\theta(s,z)}[Q(s,a)]$(標準的 Q 值最大化),但加上一個關鍵的約束——讓 $\pi_\theta$ 生成的動作分佈靠近 $\mu$。
這個約束確保了 Actor 不會生成 OOD 動作,同時 Actor 本身是一個快速的前饋網絡(不需要迭代去噪)。在在線階段,這個普通 Actor 的推斷速度使其適合作為即時決策的策略。
深度剖析
FQL 的設計體現了一個更一般的方法論原則:將"表示能力"與"執行效率"分離。擴散/流匹配模型提供了強大的表示能力——它可以精確地捕獲複雜、多模態的行為分佈。但擴散模型的迭代推斷特性使其不適合作為需要低延遲決策的 Actor(特別是在機器人等實時系統中)。FQL 的做法是:讓擴散模型在訓練時充當"老師"(提供行為分佈的豐富表示),讓普通神經網絡在推斷時充當"學生"(快速的動作生成器)。
具體的"靠近"約束可以通過多種方式實現。一種是蒸餾(distillation)——最小化 $\pi_\theta$ 與 $\mu$ 之間的 KL 散度:
$$\min_\theta D_{KL}(\pi_\theta(\cdot|s, z) \| \mu(\cdot|s))$$
另一種是對抗訓練——使用判別器確保 $\pi_\theta$ 的生成分佈與 $\mu$ 不可區分。不論哪種方式,核心目標都是讓 $\pi_\theta$ 的行為"停留在" $\mu$ 的支持集內,從而繼承擴散模型的"分佈內生成"安全性。
"why is this good?"——Levine 教授再次引導學生思考。FQL 的優勢在於:訓練時利用擴散模型的表示能力,推斷時利用普通神經網絡的速度。它在不犧牲在線推斷效率的前提下,獲得了擴散模型在行為建模上的優勢。
实例与类比
FQL 類似於"大師帶徒弟"的師徒制。大師(擴散行為模型)對領域有深刻、全面的理解——他知道所有可能的做法及其細微差異。但他做決策很慢(需要深思熟慮)。徒弟(普通神經網絡 Actor)一開始跟著大師學習,將大師的知識"蒸餾"進自己的快速決策系統。在實際操作中(在線階段),徒弟可以快速做出決策,而他的決策因為是在大師的知識體系內訓練的,不會"走偏"太遠。如果徒弟需要進一步提升(在線微調),他可以帶著從大師那裡學到的基礎回到實踐中。
关键要点
- FQL 將"表示能力"(擴散模型)與"執行效率"(普通神經網絡)分離
- 擴散/流匹配行為模型 $\mu$ 作為"老師",捕捉行為分佈的多模態結構
- 普通 Actor $\pi_\theta(s, z)$ 作為"學生",通過"靠近" $\mu$ 的約束來保證安全性
- 推斷時只需單步前向傳播(vs IDQL的迭代去噪),適合實時系統
- 核心約束:$\min_\theta D_{KL}(\pi_\theta \| \mu)$,通過蒸餾或對抗訓練實現
→ 另一個利用擴散模型優勢的創新方向是"擴散引導"(Diffusion Steering)——在擴散模型的隱空間中做在線RL,而非在動作空間中。
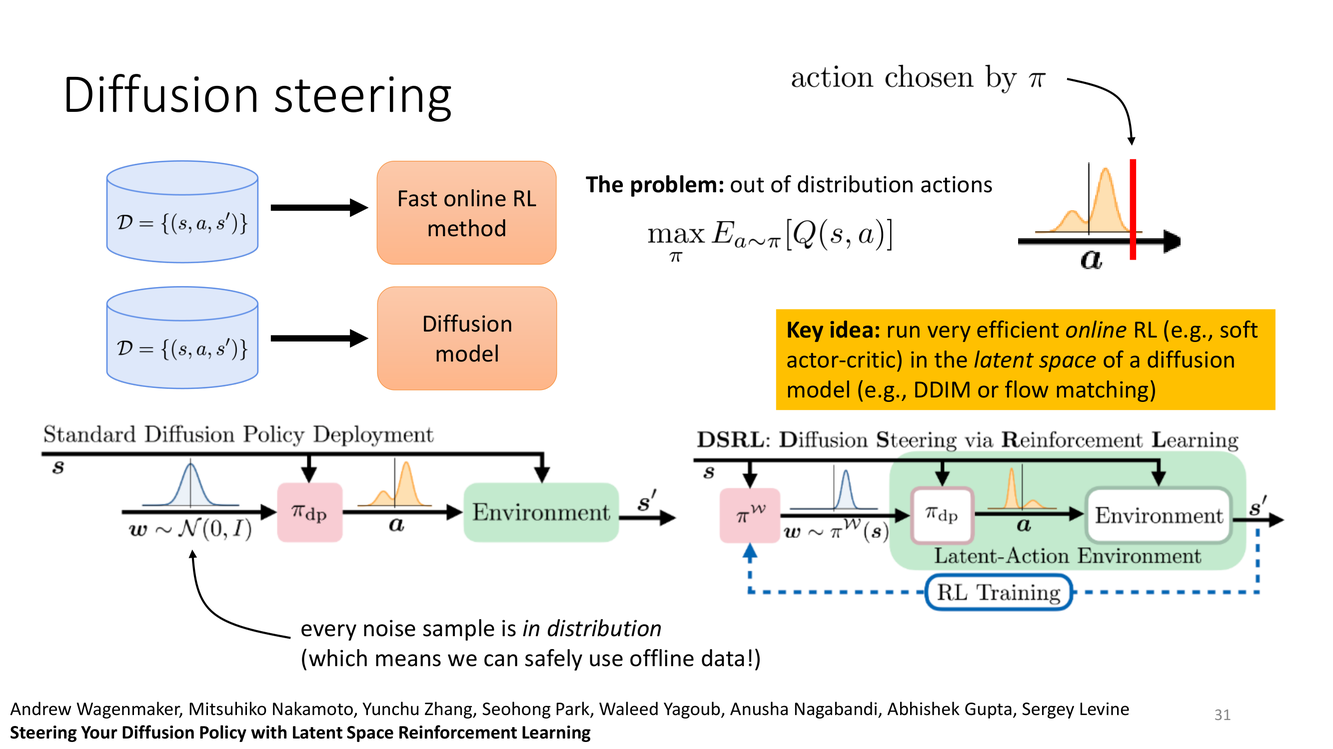
擴散引導:在隱空間中做在線RL
概念详解
擴散引導(Diffusion Steering)由 Andrew Wagenmaker, Mitsuhiko Nakamoto, Yunchu Zhang, Seohong Park, Waleed Yagoub, Anusha Nagabandi, Abhishek Gupta, Sergey Levine 提出("Steering Your Diffusion Policy with Latent Space Reinforcement Learning")。其核心洞見解決了離線到在線RL中的一個關鍵困境:
問題回顧:"The problem: out of distribution actions"——在在線RL中,策略的探索可能產生 OOD 動作,這對從離線數據中學到的 Q 函數來說是危險的(Q 函數在 OOD 區域不準確)。
關鍵想法:"Key idea: run very efficient online RL (e.g., soft actor-critic) in the latent space of a diffusion model (e.g., DDIM or flow matching)"——在擴散模型的隱空間(latent space)中運行在線RL。擴散模型(如 DDIM)的去噪過程可以表示為一個確定性的隱空間軌跡,每個噪聲樣本 $z$ 對應一個唯一的生成動作。在這個隱空間中:
"every noise sample is in distribution (which means we can safely use offline data!)"——每一個噪聲樣本都在分佈內。因為擴散模型是在離線數據上訓練的,從其隱空間中採樣並去噪生成的任何動作都自然地在訓練分佈內。這意味著在隱空間中進行RL探索永遠不會產生 OOD 動作。
深度剖析
擴散引導的方法論創新在於改變了探索發生的空間。傳統RL在動作空間中探索——策略參數化一個動作分佈 $\pi(a|s)$,探索通過在這個分佈上添加噪聲來實現。問題在於:動作空間中的隨機擾動可能導致動作脫離數據支持集。擴散引導則將探索移到了隱空間——隱空間由擴散模型的噪聲先驗 $p(z)$ 參數化,所有隱變量 $z$(在標準高斯先驗下)對應的生成動作都保證在訓練分佈內。
具體的技術方案:使用 DDIM(Denoising Diffusion Implicit Models)或流匹配(flow matching)來獲得一個確定性的隱空間到動作空間的映射 $a = f(s, z)$,其中 $z \sim \mathcal{N}(0, I)$。在這個設定下,我們可以在隱空間中訓練一個策略 $\pi(z|s)$(如 SAC Actor),它的輸出是隱變量 $z$ 而非動作 $a$。然後將 $z$ 通過凍結的擴散解碼器 $f(s, z)$ 映射為實際執行的動作。整個訓練過程中,Critic 評估的是 $Q(s, f(s, z))$,而 $f(s, z)$ 因為 $f$ 是在離線數據上訓練的且被凍結,保證了輸出在分佈內。
"Fast online RL method"——因為隱空間RL的參數化非常高效(隱變量 $z$ 的維度可以遠小於動作空間),加上 SAC 本身就是高效的online RL算法,整個系統可以在線快速學習。
实例与类比
擴散引導好比這樣一種遊戲設計:你有一個非常複雜的遊戲引擎(擴散模型的動作生成器),它能生成極其逼真且多樣的動畫。但你不想讓玩家(RL策略)直接在動畫的每一幀像素上做決策(動作空間探索),因為這可能產生物理上不可能或極其怪異的動畫(OOD動作)。相反,你給玩家一個簡化的控制面板(隱空間),面板上的每個按鈕和滑桿(隱變量 $z$)都對應一組"被引擎驗證過的"動畫序列。玩家在控制面板上探索(隱空間中的在線RL),永遠不會觸發"引擎無法處理的輸入"(OOD動作)。
关键要点
- 擴散引導的核心:在擴散模型的隱空間中做在線RL,隱空間中所有樣本都在分佈內
- 隱空間到動作空間的映射 $a = f(s, z)$ 在離線數據上預訓練並凍結
- 在線RL只需學習 $\pi(z|s)$,輸出隱變量 $z$,由凍結的解碼器 $f$ 生成安全動作
- 優勢:永遠不產生OOD動作、在線RL極其高效(隱空間通常遠小於動作空間)
- 使用 DDIM 或流匹配實現確定性的編碼-解碼
- 論文:"Steering Your Diffusion Policy with Latent Space Reinforcement Learning"
→ 我們現在轉向最後一個大主題——基於模型的離線RL。與前面所有方法不同,基於模型的方法學習環境本身的動力學,並以此來輔助決策。
第5章:基于模型的离线RL — Model-Based Offline RL

第五部分引言:基于模型的离线RL
概念详解
第五部分介紹了離線RL中的另一個重要範式:基於模型的離線RL(Model-Based Offline RL)。前面討論的所有方法(策略約束、IQL、CQL、離線到在線RL)都是無模型(model-free)方法——它們直接從數據中學習策略和/或價值函數,而不顯式地建模環境的動力學。基於模型的方法則開闢了另一條路徑:先從離線數據中學習一個環境動力學模型(dynamics model)$\hat{P}(s'|s,a)$,然後用這個模型來輔助策略優化。
基於模型的方法在在線RL中具有顯著的樣本效率優勢——模型可以"模擬"大量的虛擬交互,減少對真實環境交互的需求。但在離線設定中,基於模型的方法面臨一個獨特的挑戰:模型本身是從有限的離線數據中學習的,因此模型在數據覆蓋良好的區域是準確的,但在 OOD 區域的預測是不可靠的。如果策略在模型上規劃時利用這些不可靠的預測(即"模型利用"或 model exploitation),就可能被誤導——這就是基於模型離線RL的核心問題。
深度剖析
基於模型的方法在離線與在線設定中的處境形成了鮮明對比。在在線RL中,當模型在 OOD 區域做出錯誤預測時,智能體可以在真實環境中驗證這些預測的正確性,從而修正模型。"模型只是輔助工具,真相始終來自環境"。但在離線RL中,真實環境是不可訪問的——模型是唯一的"世界模擬器"。如果模型在 OOD 區域高估獎勵或低估風險,策略可能被引導到一個"模型中的烏托邦",而這個烏托邦在真實環境中根本不存在。
這意味著基於模型的離線RL需要一個類似於無模型方法中的"保守性"機制——在模型預測上疊加某種悲觀修正。具體來說,有兩種主要的技術路線:(1) 不確定性懲罰(uncertainty penalty,如 MOPO)——在模型的獎勵預測中減去一個與模型不確定性成正比的值,從而對"模型不了解的區域"自動施加悲觀;(2) 保守模型基RL(如 COMBO)——將 CQL 的保守正則化思想推廣到模型生成的數據上,確保 Q 函數對模型生成的(可能的 OOD)狀態-動作對保持悲觀。
实例与类比
無模型方法好比一個只依靠歷史經驗做決策的醫生(不試圖理解疾病的底層機制)。基於模型的方法好比一個建立了疾病機制模型(動力學模型)的醫生。在在線場景中,後者可以通過實驗來驗證和修正他的模型。但在離線場景中(只能看歷史病歷),如果醫生過度相信他的機制模型,可能在遇到新症狀組合時給出錯誤的診斷(模型利用)。MOPO 和 COMBO 本質上是給這個機制模型加上各種"安全係數"——對於模型不確定的推斷,系統性地降低其權重。
关键要点
- 基於模型的離線RL先學環境動力學模型 $\hat{P}(s'|s,a)$,再用模型輔助策略優化
- 核心挑戰:模型在 OOD 區域的預測不可靠 → 策略可能被誤導(模型利用)
- 在線 vs 離線的關鍵區別:在線可以驗證/修正模型,離線無法
- 兩種解決路線:不確定性懲罰(MOPO)+ 保守模型基RL(COMBO)
→ 先來理解基於模型RL的基本工作原理,以及它在離線設定中的失效模式。
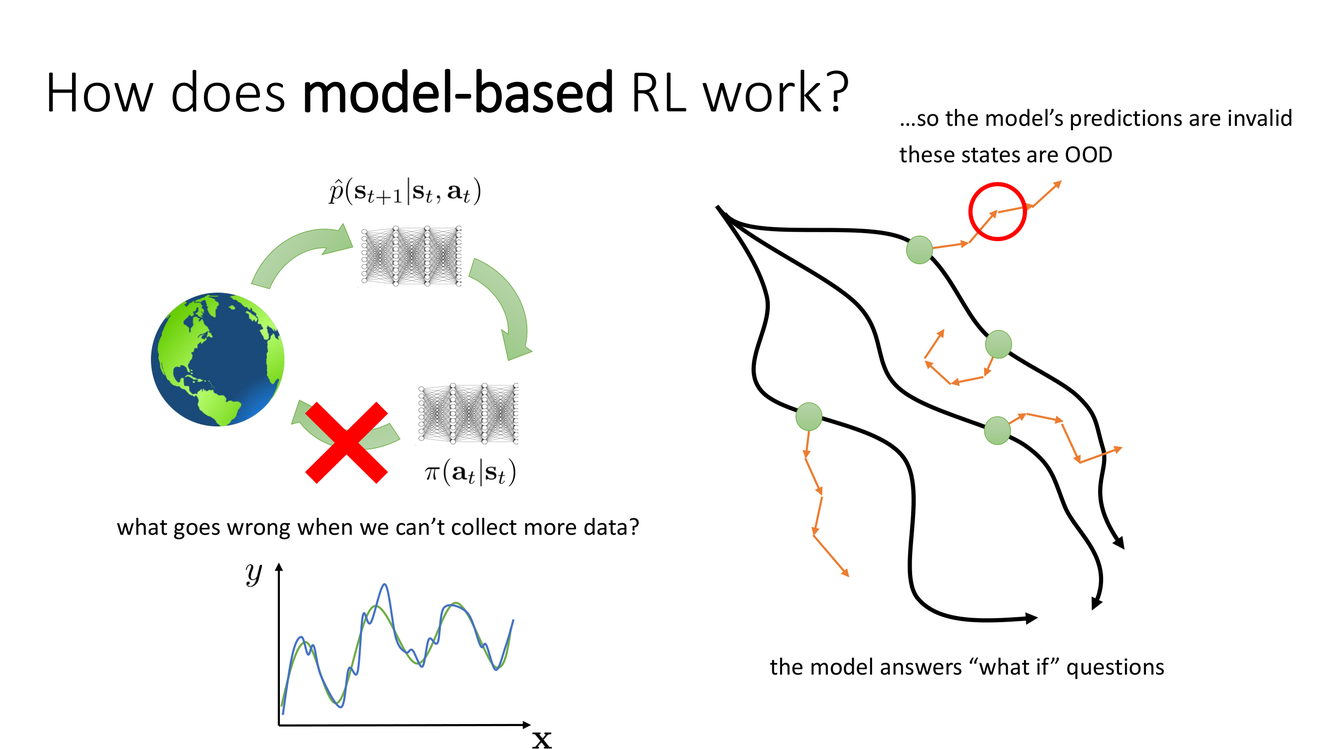
基於模型RL的原理與離線失效模式
概念详解
Slide 33 用一個示意圖解釋了基於模型RL的基本原理和其在離線設定中的失效模式。在標準的基於模型RL中,模型充當一個"反事實推理引擎"——它回答"what if"問題("如果我在狀態 $s$ 採取動作 $a$,會發生什麼?")。具體流程:
(1) 從真實環境中收集數據 $\mathcal{D} = \{(s, a, r, s')\}$;(2) 訓練動力學模型 $\hat{P}(s'|s,a)$ 來預測狀態轉移;(3) 使用這個模型生成(模擬)額外的訓練數據;(4) 在真實數據和模型生成數據的混合上訓練策略。
然而在離線RL中——"what goes wrong when we can't collect more data?"——當我們無法收集更多數據時,問題出現了。圖中用兩個圈表示了這個問題:內圈是數據集覆蓋的狀態空間(模型預測可靠),外圈是 OOD 狀態("these states are OOD")。當策略在模型上規劃時,可能引導智能體走向 OOD 狀態——"so the model's predictions are invalid"(模型的預測無效)。因為模型從未在這些狀態上被訓練過,其預測可能任意偏離真實動力學。更危險的是,模型可能自信地錯誤——它可能對 OOD 狀態做出高置信度的不準確預測,因為神經網絡傾向於在訓練分佈外也給出看似合理的輸出。
深度剖析
基於模型RL的 OOD 問題可以通過模型誤差的複合放大效應來理解。在模型上進行 rollout(軌跡展開)時,第一步模型預測 $\hat{s}_1 = f(s_0, a_0)$ 引入一個小的誤差 $\epsilon_1$。但第二步的預測 $\hat{s}_2 = f(\hat{s}_1, a_1)$ 的輸入就是 $\hat{s}_1$(而非真實的 $s_1$),這意味著 $\epsilon_1$ 傳播進入第二步,產生更大的誤差 $\epsilon_2$。經過 $H$ 步 rollout 後,累計誤差可能呈指數增長:
$$\|\hat{s}_H - s_H\| \approx O(L^H \cdot \epsilon_0)$$
其中 $L$ 是模型在狀態空間中的 Lipschitz 常數($L > 0$)。在數據覆蓋良好的區域,$L$ 可能小於 1(收縮);但在 OOD 區域,$L$ 可能大於 1(發散),導致 rollout 快速偏離真實軌跡。
這與無模型方法中的 Q 值過度估計形成了有趣的對稱:無模型方法中,max 操作導致 Q 值在 OOD 區域被高估;基於模型方法中,模型的錯誤預測導致策略在 OOD 區域被誤導。兩者都是"樂觀偏置"的表現——智能體傾向於相信"未嘗試過的可能更好"。
实例与类比
基於模型RL的 OOD 問題好比這樣:你有一個地圖(模型)涵蓋了你所在城市(數據覆蓋區域)的詳細道路信息。你在地圖上規劃從A到B的最優路線(模型規劃)。問題在於,你的最優路線可能經過地圖沒有覆蓋的郊區道路(OOD狀態)——地圖上顯示這些路"看起來可以通行",但實際上可能已經封路、施工或根本不存在。如果你的路線過度依賴這些未經驗證的道路,你可能在現實中嚴重偏航。MOPO 和 COMBO 的解決方案是:給地圖上未驗證的區域標記為"高風險"(不確定性懲罰),讓最優路線傾向於走已被驗證過的道路。
关键要点
- 基於模型RL的基本循環:收集數據 → 訓練模型 → 用模型生成數據 → 訓練策略
- 離線設定中無法收集新數據來糾正模型 → OOD區域模型預測不可靠
- 模型誤差在 rollout 中複合放大:$\|\hat{s}_H - s_H\| \approx O(L^H \epsilon_0)$
- 與無模型方法的對稱:都是"樂觀偏置"的不同表現形式
- 神經網絡傾向於在 OOD 區域給出"自信但錯誤"的預測
→ MOPO 是解決這一問題的第一個系統性嘗試——通過對模型生成的獎勵施加不確定性懲罰。
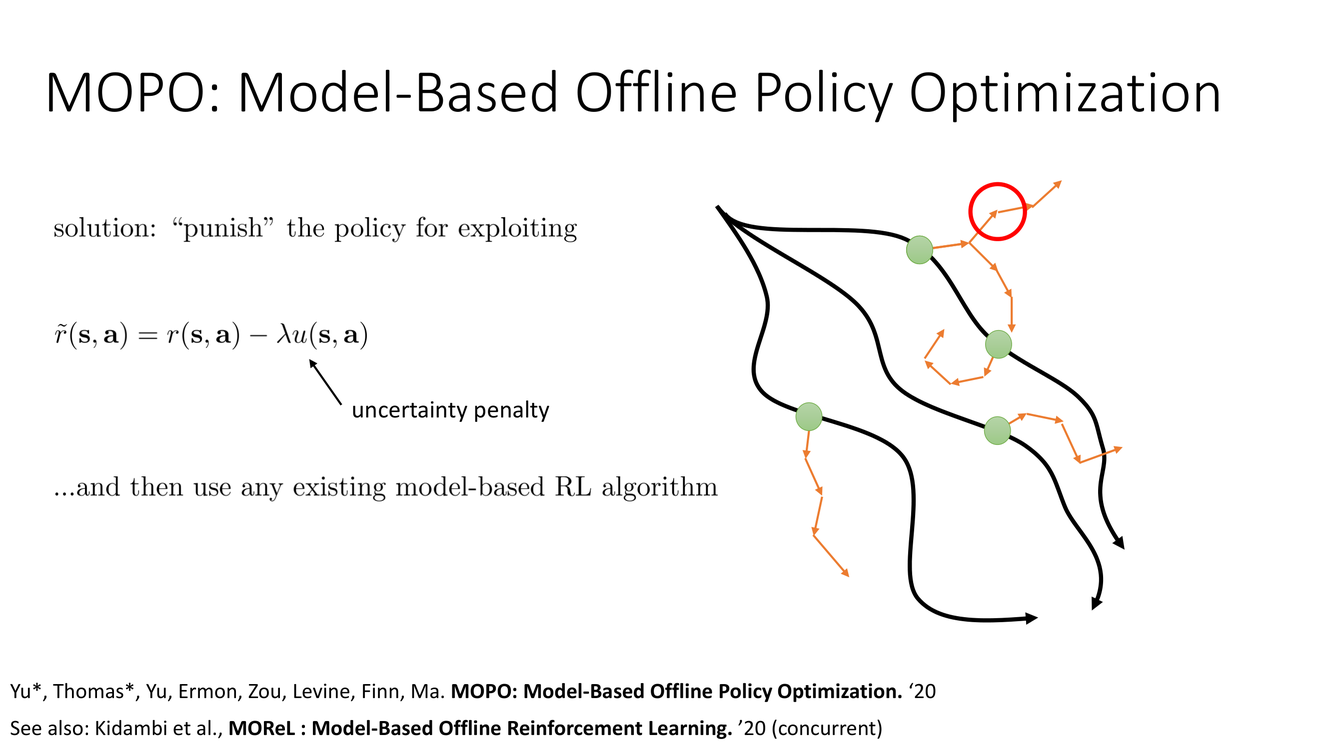
MOPO:帶有不確定性懲罰的基於模型離線RL
概念详解
MOPO(Model-Based Offline Policy Optimization)由 Yu, Thomas, Yu, Ermon, Zou, Levine, Finn, Ma 於 2020 年提出。其核心思想極其直觀:在模型的獎勵預測上減去一個不確定性懲罰(uncertainty penalty),從而阻止策略利用模型在 OOD 區域的錯誤樂觀預測。修改後的獎勵為:
$$\tilde{r}(s,a) = \hat{r}(s,a) - \lambda \cdot u(s,a)$$
其中 $\hat{r}(s,a)$ 是模型預測的獎勵,$u(s,a)$ 是模型對 $(s,a)$ 處預測的不確定性度量,$\lambda > 0$ 是懲罰係數。策略在 MDP 中優化這個修改後的獎勵函數,MDP 的動力學由學到的模型 $\hat{P}(s'|s,a)$ 提供。
不確定性度量 $u(s,a)$ 是 MOPO 的關鍵設計。常見的選擇包括:(a) Ensemble 方差——訓練多個動力學模型(ensemble),用它們對下一狀態預測的方差作為不確定性:$u(s,a) = \text{Var}_{i=1,...,K}[\hat{P}_i(s'|s,a)]$;(b) 模型預測誤差的對數似然——但這需要一個單獨的誤差模型。Ensemble 方法是最常用的,因為它不需要額外的架構設計,且在多個 RL 工作中被證明是有效的。
深度剖析
MOPO 的不確定性懲罰機制可以從貝葉斯視角來理解。假設我們有一個模型後驗分佈 $p(\hat{P}|\mathcal{D})$,表示了在給定數據 $\mathcal{D}$ 後對動力學模型的信念分佈。後驗反映了兩種不確定性:(a) 認知不確定性(epistemic uncertainty)——由於數據不足導致的不確定性,可以通過收集更多數據來減少;(b) 偶然不確定性(aleatoric uncertainty)——環境固有的隨機性,無法通過更多數據來消除。
MOPO 的 ensemble 方差主要捕捉的是認知不確定性——如果多個模型在 $(s,a)$ 處的預測差異很大,說明該區域數據不足,模型不可靠。在這些區域,不確定性懲罰 $\lambda u(s,a)$ 自動降低獎勵,阻止策略在這些區域"投機"。
然而,MOPO 的一個潛在限制是:不確定性懲罰施加在即時獎勵上,而非長遠的價值估計上。這意味著:如果一個 OOD 狀態的即時模型預測不確定性較小(例如,模型對那個狀態的預測恰好"自信地錯誤"),但長遠來看會導致糟糕的結果,MOPO 可能無法充分懲罰這種情況。這是 COMBO 試圖解決的問題。
MOPO 的同期工作包括 Kidambi et al. 的 MOReL(Model-Based Offline Reinforcement Learning),它採用了類似的理念(不確定性懲罰),但在實現細節上有所不同(MOReL 使用了更複雜的不確定性度量,包括構建一個"已知區域"的Pessimistic MDP)。
实例与类比
MOPO 好比一個旅遊規劃系統。系統根據歷史遊記(離線數據)建立了一個世界地圖(動力學模型)。當你讓它規劃從北京到巴黎的旅行路線時,標準模型可能推薦一條"看起來最有趣"的路線,其中包含一些"在地圖上顯示可行但實際無人走過"的偏僻小路。MOPO 則在每段路的"預計風景評分"(預測獎勵)上減去"該路段有多少人走過"(不確定性懲罰),從而自然偏好"成熟的路線"而非"偏僻小路"。這樣,即使模型的預測存在誤差,最終的路線也更傾向於安全、被驗證過的選項。
关键要点
- MOPO 核心:$\tilde{r}(s,a) = \hat{r}(s,a) - \lambda u(s,a)$,在模型獎勵上減去不確定性懲罰
- 不確定性 $u(s,a)$ 通常通過 ensemble 模型的預測方差來估計
- 主要捕捉認知不確定性(epistemic uncertainty)——可通過更多數據減少的模型不確定性
- 貝葉斯視角:對模型的後驗分佈保持悲觀,在不確定區域降低獎勵
- 限制:懲罰施加在即時獎勵上,可能無法充分捕獲長遠的 OOD 風險
- 同期工作:MOReL(Kidambi et al.),理念相似但實現不同
→ COMBO 將 MOPO 和 CQL 的思想合二為一——在基於模型的設定中引入 CQL 風格的保守 Q 值正則化。
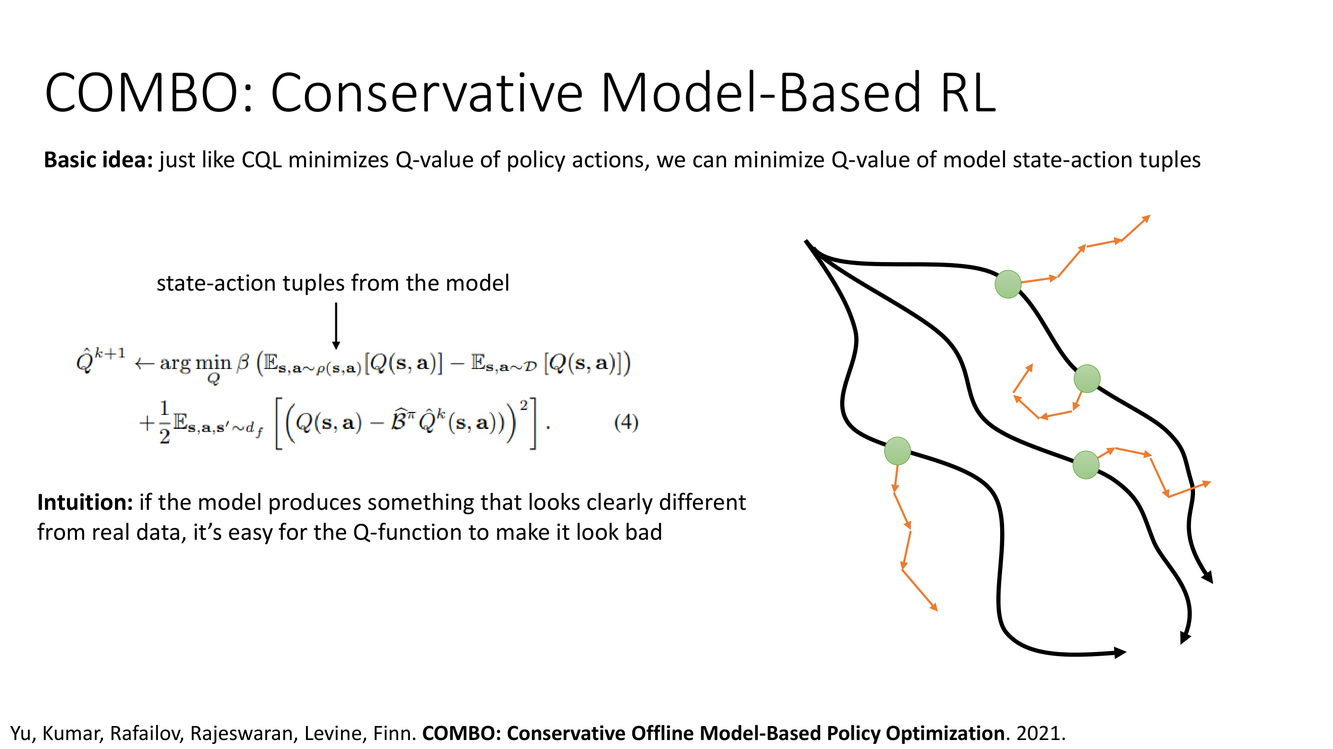
COMBO:保守的基於模型離線RL
概念详解
COMBO(Conservative Offline Model-Based Policy Optimization)由 Yu, Kumar, Rafailov, Rajeswaran, Levine, Finn 於 2021 年提出。它橋接了兩條此前平行的研究線路:MOPO 的基於模型離線RL和 CQL 的保守 Q 學習。
COMBO 的核心思想——"Basic idea: just like CQL minimizes Q-value of policy actions, we can minimize Q-value of model state-action tuples"——正如 CQL 压低策略生成动作的 Q 值,COMBO 压低模型生成的状态-动作对的 Q 值。具體來說,CQL 的保守正則化項操作在"當前策略的動作"上:
$$\mathcal{L}_{\text{CQL-reg}} = \alpha (\mathbb{E}_{s\sim\mathcal{D}, a\sim\pi}[Q(s,a)] - \mathbb{E}_{(s,a)\sim\mathcal{D}}[Q(s,a)])$$
而 COMBO 將其擴展到"模型生成的狀態-動作對"上:
$$\mathcal{L}_{\text{COMBO-reg}} = \alpha (\mathbb{E}_{(s,a)\sim\rho_{\text{model}}}[Q(s,a)] - \mathbb{E}_{(s,a)\sim\mathcal{D}}[Q(s,a)])$$
其中 $\rho_{\text{model}}$ 是在學到的動力學模型中通過策略 rollout 產生的狀態-動作分佈。這裡的關鍵是:$\rho_{\text{model}}$ 包括了模型推向 OOD 區域的數據點。通過壓低這些點的 Q 值,COMBO 直接對抗模型的樂觀偏置——即使模型在 OOD 區域預測了誘人的獎勵,Q 函數對這些區域的值也被保守正則化壓低了。
深度剖析
COMBO 相對於 MOPO 的關鍵進步在於正則化發生的層面。MOPO 在獎勵層面施加不確定性懲罰——直接修改模型獎勵 $\tilde{r} = \hat{r} - \lambda u$。COMBO 則在價值層面施加保守性——通過 Q 函數的正則化來壓低模型生成數據的價值。這種差異的意義在於:
MOPO 的獎勵修正 $\tilde{r} - \lambda u$ 只在當前步驟起作用,它在 Bellman 備份中是"局部"的。如果模型在一個 OOD 區域的即時不確定性較低(模型對自己的錯誤預測很自信),但從該區域出發的長期後果是不利的,MOPO 的局部懲罰可能不足以防止策略進入該區域。
COMBO 的價值正則化則通過 Bellman 備份的遞歸性質傳播到所有未來步驟。即使當前步驟的不確定性較低,如果未來步驟的不確定性高,這些步驟對應的 Q 值也會被壓低。這意味著 COMBO 能夠捕獲那些"模型預測看似合理,但長期後果糟糕"的 OOD 區域。
此外,COMBO 利用了 CQL 的理論保證——在表格設定下,COMBO 的 Q 函數是對真實 Q 函數的下界(lower bound)。這為 COMBO 提供了與 CQL 相同的理論安全性。"Intuition: if the model produces something that looks clearly different from real data, it's easy for the Q-function to make it look bad"——如果模型產生的數據明顯不同於真實數據,Q 函數很容易使其看起來差(因為 Q 函數被訓練為壓低與數據分佈不同的區域)。
实例与类比
MOPO 好比在導航時對未知道路標記"此路風險高,預計車程增加20分鐘"——它直接修改了該道路的"成本"(獎勵)。COMBO 則好比建立了一個綜合評估系統——不僅考慮當前道路的風險,還考慮從該道路出發可能到達的所有後續道路的風險。即使當前這條未知道路"看起來很平坦"(模型低不確定性),如果它通往一片完全未探索的區域,COMBO 的評估系統也會給出低分(壓低 Q 值)。這種"長遠眼光"使 COMBO 在某些場景中比 MOPO 更穩健。
关键要点
- COMBO = MOPO的模型基框架 + CQL的保守Q值正則化
- 核心正則化:$\mathcal{L}_{\text{COMBO}} = \alpha(\mathbb{E}_{\rho_{\text{model}}}[Q] - \mathbb{E}_{\mathcal{D}}[Q])$
- 相對於MOPO的進步:正則化在價值層面(而非獎勵層面),通過Bellman備份傳播到所有未來步驟
- 能捕獲"模型預測看似合理但長期後果糟糕"的OOD區域
- 繼承CQL的理論保證:在表格設定下,Q函數是真實Q函數的下界
- 直覺:模型生成的數據若不同於真實數據,Q函數自然壓低其值
→ 至此,我們完成了對離線RL五大算法家族的完整巡禮。從策略約束到IQL,從CQL到離線到在線RL,再到基於模型的方法——每一種方法都以不同的方式回應了同一個根本挑戰:在無法與環境交互的情況下,如何安全地從固定數據中學習最優策略。