CS 285: Deep Reinforcement Learning — 第17讲 详细讲义
第1章:什么是离线强化学习?(What is Offline RL?)

课程概述:离线强化学习的定位
概念详解
第17讲的主题是离线强化学习(Offline Reinforcement Learning,也称 Batch RL)。这是 CS 285 课程中一个承前启后的重要环节。在之前的课程中,我们系统学习了在线强化学习(online RL)的两大范式——基于策略的方法(on-policy RL,如 policy gradient、TRPO、PPO)和离策略方法(off-policy RL,如 Q-learning、DDPG、SAC)——它们都假设智能体(agent)能够与环境实时交互并收集新数据。离线RL则提出了一个截然不同且更为实际的问题设定:在无法与环境交互的前提下,仅利用预先收集的静态数据集来训练策略。
这个设定的现实意义非常重大。在机器人学、自动驾驶、医疗决策、推荐系统等真实应用中,在线交互往往代价高昂、危险甚至根本不可行——你不能让一个未经训练的自动驾驶汽车上路撞几次来"学习",也不能在重症监护病房里用病人的生命做探索实验。离线RL试图回答的问题是:给定一批由某个(可能是次优的、甚至是未知的)行为策略(behavior policy)生成的历史数据,我们能否学习出一个优于数据中展现的所有行为的策略?
深度剖析
在 CS 285 的课程架构中,这一讲处于关键位置。前面几讲(Lec 13-16)深入讨论了 Q-learning、actor-critic、以及 max-entropy RL(SAC),这些方法都属于 off-policy RL——它们在技术上可以利用历史数据训练。那么问题来了:如果 off-policy RL 已经可以从历史数据中学习,离线RL有什么特别的?答案是:off-policy RL 虽然可以用历史数据,但它本质上仍然假设可以持续与环境交互来纠正错误,而离线RL完全排除了这种可能性。这个看似微小的差别导致了根本性的算法挑战——分布偏移(distributional shift)——我们将在本章和后续章节中深入剖析。
Sergey Levine 在课程中特别强调一个哲学层面的观点:理解离线RL不仅仅是学会一种新算法,更重要的是它帮助我们更深刻地理解RL本身。当剥离了"可以通过试错来纠错"这个安全网后,RL算法中隐藏的脆弱性——函数逼近误差、采样误差、过度估计偏差——都会被放大到致命的程度。这使得离线RL成为了一面放大镜,让我们重新审视那些在在线设定下"还凑合"的算法设计选择。
实例与类比
想象你是一家自动驾驶公司的算法工程师。公司已经积累了数百万英里的真实驾驶数据——由人类驾驶员操作、记录了各种天气、路况和交通场景。这些数据包含了大量"正常驾驶"行为,也有一些"不完美"的变道、突然刹车等。你不能让一个训练中的AI模型在真实道路上自由尝试,因为那太危险了。离线RL的目标就是:仅凭这些已有的驾驶记录,训练出一个驾驶策略,它甚至可能在特定场景下表现得比数据中的人类驾驶员更好。这就是离线RL的终极魅力所在。
关键要点
- 离线RL的基本设定:利用固定的、预先收集的静态数据集训练策略,不允许任何新交互
- 与 on-policy RL 和 off-policy RL 的层次关系:off-policy可以用历史数据,离线RL在此基础上完全切断交互能力
- 现实驱动力:机器人、医疗、自动驾驶等场景不允许在线试错探索
- 方法论意义:离线RL是一面放大镜,暴露标准RL算法在缺乏纠错机制时的深层脆弱性
→ 在理解了离线RL的基本定义后,我们需要更精确地厘清它与其他RL范式的关系——下一组 slides 将通过直观的图示和分类来确立这一定位。
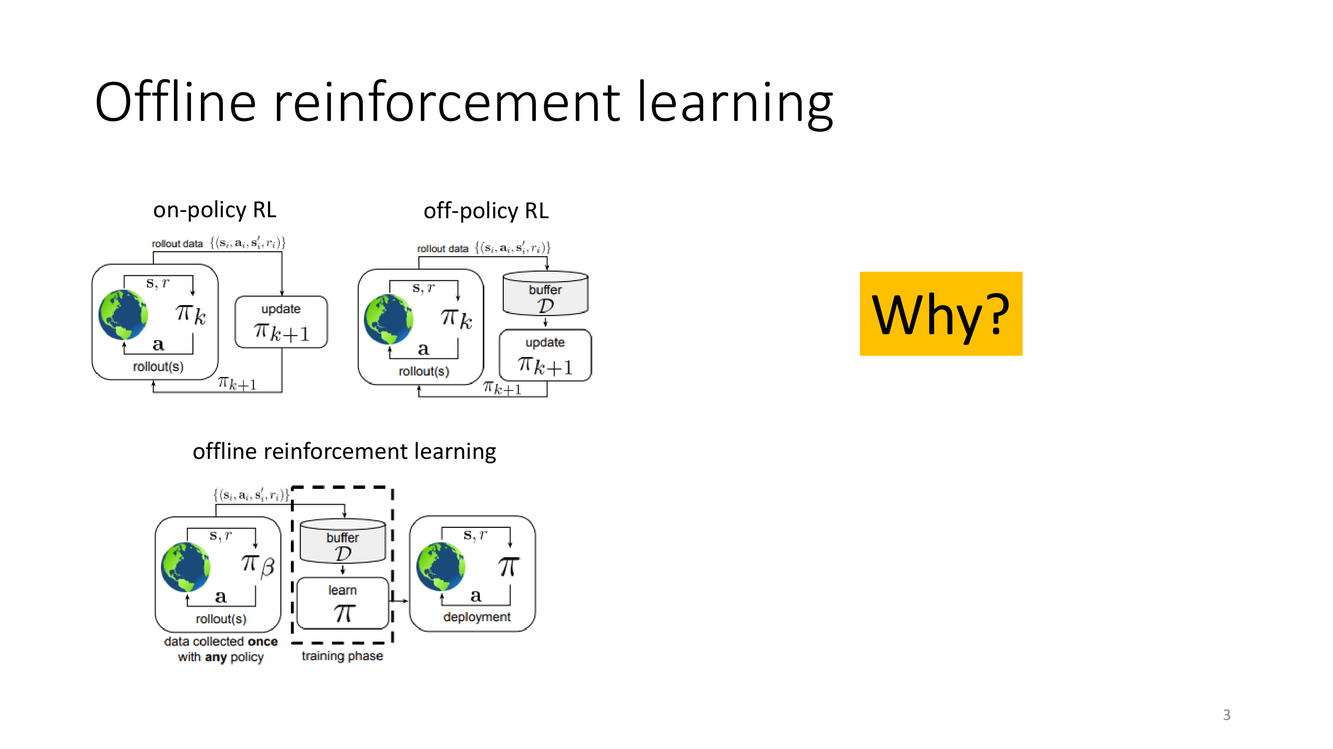
离线RL的定义:与 on-policy RL 和 off-policy RL 的区分
概念详解
为了准确把握离线RL的独特之处,我们需要回顾三种RL范式之间的区别,它们形成了一个从"最互动"到"最不互动"的光谱:
On-policy RL(基于策略的强化学习):智能体用当前策略 $\pi_\theta$ 采集数据,更新策略,然后丢弃旧数据。每个数据批次只能使用一次,因为更新后的策略分布已经改变,旧数据不再能代表当前策略的行为。典型代表有 Vanilla Policy Gradient(VPG/REINFORCE)、TRPO、PPO。
Off-policy RL(离策略强化学习):智能体可以使用任何策略(包括历史策略)生成的数据来更新当前策略。这意味着数据可以来自经验回放缓冲区(replay buffer),允许复用历史数据以提高样本效率。典型代表有 DQN、DDPG、SAC。然而,off-policy RL 仍然假设智能体可以持续与环境交互来填充回放缓冲区,并且可以通过探索策略(如 $\epsilon$-greedy 或高斯噪声)来主动收集关于不确定区域的信息。
Offline RL(离线强化学习,又叫 Batch RL):数据是固定的、预先收集的,没有机会与环境进行任何新的交互。数据只能读取(read-only),不能通过任何形式的探索来补充。行为策略(生成数据的策略)可能是未知的、混合的、且通常是次优的。
深度剖析
Slides 上的三幅图标非常直观地展示了这几种范式。On-policy RL 的数据和策略更新形成一个紧密咬合的闭环——策略更新后必须用新策略重新采样。Off-policy RL 放宽了这一点,数据和策略"解耦"了——来自任意策略的数据都可以用于更新,但底层的交互通道仍然存在。离线RL则将交互通道完全切断——我们用虚线框住"环境"这一部分,表示它已经不在我们的算法运行时可触及的范围内。
这里有一个容易混淆的点:off-policy RL 是否就等于离线RL?答案是否定的。Off-policy RL 的"离策略"指的是学习算法可以处理由不同于当前策略的行为策略产生的数据。但这并不限制你继续与环境交互来收集更多数据。很多 off-policy 算法(如 SAC)在实际应用中仍然严重依赖在线交互来保持较好的性能。实际上,如果直接把标准的 off-policy RL 算法(不做任何特殊处理)应用于纯粹的离线数据集,通常会导致灾难性的性能崩溃——这正是本讲后半部分要揭示的核心问题。因此,离线RL不仅仅是"off-policy RL 的一个子集",它要求专门的算法设计来处理分布偏移问题。
实例与类比
可以把这三种范式类比为不同的学习方式:On-policy 就像学生做练习题,每做完一道题就立刻获得答案反馈,然后调整解法做下一题——每道题只能做一次。 Off-policy 则是学生可以反复翻阅之前做过的所有题目(包括自己独立做的、以及看别人做的),但随时可以自己做新题来填补知识盲区。 Offline RL 则像是学生只能看一本固定题库——不能自己做新题来验证理解,只能在脑海中"推算"哪些解法更好。这本题库里可能有好解法,也有错误解法,学生必须从中学到最好的解题策略,却不能通过做题来确认自己的判断是否正确。
关键要点
- On-policy:数据由当前策略生成,用后即弃——样本效率低但理论保证好
- Off-policy:数据可以复用,但仍可通过交互收集新数据——放宽了数据约束但保留了交互能力
- Offline RL:数据完全固定,不允许任何新交互——这是最严苛但最贴近实际应用的设定
- "Off-policy ≠ Offline":直接将标准 off-policy 算法应用于离线数据通常会导致灾难性失败
→ 那么,为什么离线RL如此重要?它的价值不仅在于理论上的挑战,更在于它在真实世界的人工智能里程碑中已经展现出了惊人的能力——让我们以 AlphaGo 的"第37手"为例。

AlphaGo "Move 37":强化学习的创造力
概念详解
2016年3月,AlphaGo 与韩国围棋九段李世石(Lee Sedol)的第二局比赛中,AlphaGo 下出了载入史册的"第37手"——一步五路肩冲(shoulder hit on the fifth line)。这一手让所有观看比赛的专业棋手和评论员陷入了震惊和沉默。根据人类围棋的千年经验,肩冲在五路(比通常的三路高出两路)几乎是"不可思议"的,它会被认为是一种浪费——在外围走一步,放弃了角部实地。然而,这步棋最终证明是整个棋局的胜负手,为 AlphaGo 建立了无懈可击的中心势力。
李世石本人花了超过12分钟思考回应(在1分钟读秒的比赛中这是极其罕见的长考),在场九段评论员说"我认为这是 AlphaGo 的失误",解说员甚至以为程序出错了。但事实证明,AlphaGo 通过自我对弈强化学习,发现了一种超越人类千年围棋智慧的策略。围棋传奇李世石在赛后坦诚:"AlphaGo的这一手完全出乎我的预料,我从没见过有人这么下。它让我怀疑自己的判断。"
深度剖析
Sergey Levine 将这张 slide 放在这里,目的远不止于讲述一个历史趣闻。Move 37 完美地诠释了强化学习的核心承诺:通过优化一个目标函数(在围棋中是"赢棋"这个稀疏奖励),智能体不仅能够复现人类已有的最佳实践,还能够涌现出(emergent)超越人类经验的新策略。这不是简单地模仿人类棋谱(那是监督学习/模仿学习),而是通过从零开始的自我对弈和自我探索,在巨大的策略空间中找到了一个人类从未踏足的"甜点"。
这张 slide 也隐含着一个更深的命题:如果强化学习可以纯粹通过自我对弈(本质上是一种"在线RL"的方式,AlphaGo 通过蒙特卡洛树搜索 + 价值网络进行自我对弈训练)达到如此令人惊艳的效果,那么强化学习是否可以成为"通用人工智能"(AGI)的核心引擎?Sergey 在这里设置了一个思想张力——一方面,在线RL展示了极强的创造力;另一方面,真实世界中的应用往往要求离线学习。这自然引出了下一个问题:我们能否在离线设定下也实现类似的创造力?能否仅凭已有的围棋棋谱(而不进行任何自我对弈)训练出一个超越人类水平的围棋 AI?答案是:极难。这正是离线RL要攻克的核心困难。
实例与类比
Move 37 可以类比为一次"科学发现"。科学史上最伟大的发现——哥白尼的日心说、爱因斯坦的相对论、量子力学的基本原理——都不是通过对已有数据的简单拟合得出的。它们本质上是一种"创造性外推"(creative extrapolation):从已知的数据中推断出超越数据本身覆盖范围的新知识。RL 的在线探索机制给了智能体这种外推的"试验场"——它可以提出一个前所未有的大胆策略,然后通过实际操作来验证它。而离线RL面临的挑战是:你必须在没有试验场的情况下完成这种创造性外推——基于有限的、可能充满偏见的已有数据,推断出更好的行为方式。
关键要点
- AlphaGo "Move 37" 展示了RL的核心价值:通过优化目标函数涌现出超越人类经验的新策略
- 这一成就依赖于在线自我对弈——智能体可以大胆探索并实时验证新策略
- 离线RL面临的核心矛盾:如何在缺乏"试验场"的情况下实现同样级别的创造性外推?
→ AlphaGo 的成就集中体现了"优化"驱动的AI的威力,但在现实中,我们大多数时候拥有的只有"数据"——接下来让我们审视"数据驱动的AI"与"强化学习"之间的鸿沟。
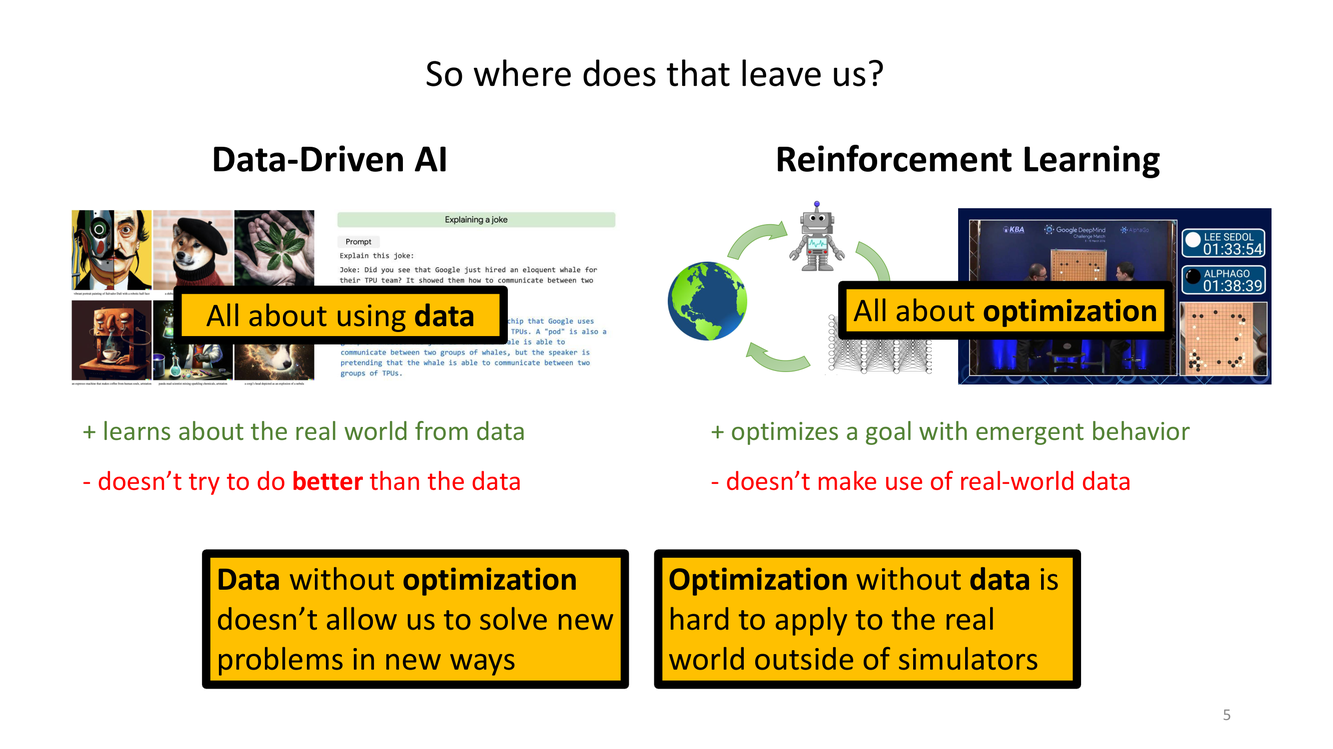
数据驱动的AI vs 强化学习:两大范式的对决
概念详解
这张 slide 是整讲中最重要的"世界观" slide 之一。Sergey Levine 将当今 AI 的两大主流范式进行了鲜明的对比和剖析:
数据驱动 AI(Data-Driven AI),其核心范式是监督学习(supervised learning)和模仿学习(imitation learning)。优点在于:
- 能够从真实世界数据中学习,数据来自人类专家或自然分布(如互联网文本、人类标注、专家示范)
- 训练过程稳定、可预测,有大量成熟的优化理论支撑
- 在大数据时代取得了巨大成功——ImageNet 图像识别、GPT 语言模型等都是杰出代表
但它的根本局限在于:不会试图做得比数据更好(doesn't try to do better than the data)。监督学习的目标函数(如交叉熵损失、均方误差)本质上是在最小化模型预测与数据标签之间的差异——它被设计为忠实地"拟合"数据分布,而非"超越"数据分布。
强化学习(Reinforcement Learning) 则从另一个角度切入:通过优化一个长期累积奖励目标,产生具有涌现行为的智能体。优点在于:
- 可以优化某个明确的目标,产生创造性的、超出预期的策略
- 不依赖于"正确答案"标签——只需要一个标量奖励信号就能自主学习
- 在游戏、仿真、机器人控制等环境中展现了超越人类的性能
但它也有一项致命短板:无法有效利用真实世界数据(doesn't make use of real-world data)。强化学习通常需要一个仿真的、可以低成本交互的环境——AlphaGo 需要数百万局自我对弈,OpenAI Five 需要数万年的游戏时间。对于大多数真实应用,这种交互是不现实的。
深度剖析
Sergey 用两个对角象限概括了问题的本质:
左上角:没有优化的数据(Data without optimization)——无法以新的方式解决新的问题。你可能有海量的驾驶数据,但如果只是模仿人类的平均表现,你不可能训练出一个比最好的人类驾驶员更安全的自动驾驶系统。因为人类的平均驾驶水平本身就有很多缺陷(疲劳驾驶、分心、路怒等),简单模仿只会放大这些缺陷。
右下角:没有数据的优化(Optimization without data)——难以应用到真实世界(除非在仿真环境中)。你能在 MuJoCo 仿真中训练出一个完美行走的机器人,但一旦放到真实世界中,因为仿真到真实的"现实鸿沟"(reality gap),策略可能完全失效。
离线RL试图弥合这条鸿沟——在固定的真实世界数据上执行优化。这是野心极大的目标:既保留 RL 的优化能力(试图超越数据中最好的表现),又依赖于数据驱动的稳定性(使用真实世界的数据而非仿真器)。这也正是为什么离线RL被许多人视为强化学习走向真实世界应用的"关键钥匙"。
Side note: 在大语言模型(LLMs)的时代,这张 slide 的对比显得格外有先见之明。LLMs 的成功路径其实是一种折中——它们通过大规模的模仿学习(next-token prediction)进行预训练(数据驱动),然后通过 RLHF(Reinforcement Learning from Human Feedback)进行微调(优化驱动)。这与后面 slide 6 提到的"离线预训练 + 在线微调"的模式如出一辙。
实例与类比
类比:数据驱动的AI像是"抄作业"——你能忠实地复现参考答案,但如果遇到一道全新的、不在已有作业中的题,你可能束手无策。强化学习则像是"自己解题"——你可以自由探索各种解法,可能找到更好的方法,但你也可能耗用30张草稿纸、花费数小时却一无所获(甚至更糟——学到了一些错误的"捷径")。离线RL试图做到的是:只给你一本已经做好的习题集(不能自己做新题),但你不仅要"理解"这些题,还要能从中推导出比答案更好的解法。
关键要点
- 数据驱动的AI(监督/模仿学习):善于利用数据,但受限于数据质量上限
- 强化学习:善于优化超越数据,但无法高效利用真实世界数据
- 离线RL试图弥合二者的鸿沟:在固定真实世界数据上执行优化,既利用数据又追求超越
- LLM的成功路径(预训练+RLHF)暗合了离线RL的"预训练+微调"理念
→ 这一宏大愿景如何落地?离线RL的实用图景是怎样的?下一张 slide 给出了完整的回答。
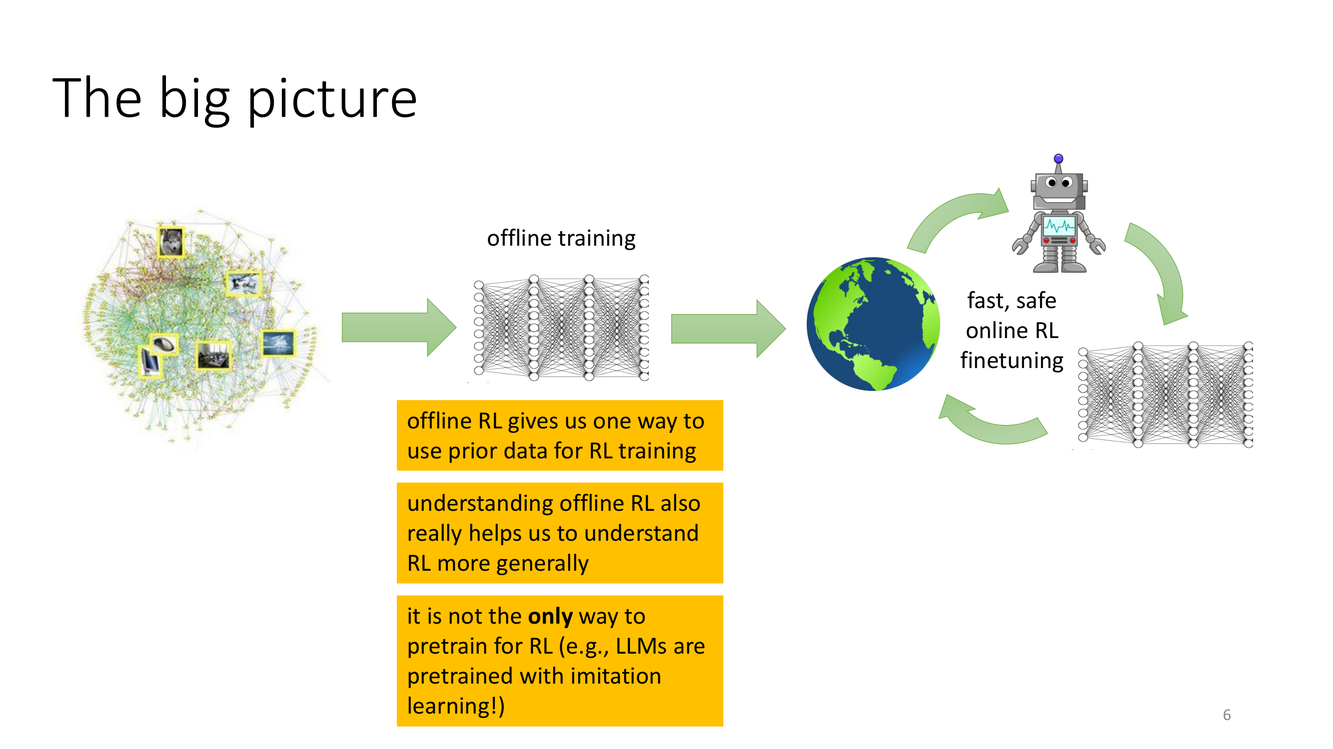
离线RL的宏大图景:预训练 + 微调范式
概念详解
这张 slide 描绘了离线RL在实际应用中的理想工作流,也是 Sergey Levine 研究组多年来一直倡导的范式:
第一阶段——离线训练(offline training):利用大规模离线数据集(如人类操作员的示范、历史运行日志、多种策略的混合数据等),在安全、可控的计算环境中训练出一个RL策略。这个过程不涉及任何与真实环境的交互,因此可以在"桌面"上完成,快速迭代。
第二阶段——在线微调(online RL finetuning):将离线训练得到的"预训练"策略部署到真实环境中,通过少量、快速且安全的在线交互进行微调,以弥合离线数据与真实环境之间的分布差距(distribution gap)。由于已经有了很强的初始策略,在线微调不再需要从零开始探索,可以非常高效和安全。
这个两阶段的模式与当今深度学习在 NLP 和 CV 领域的预训练+微调范式(BERT→fine-tune on specific task, GPT→RLHF)高度相似。它解决了纯在线RL的"冷启动"问题——大多数在线RL算法在开始时完全随机,需要非常多的试错才能学到有用的行为。
深度剖析
一个关键的元层次洞见是:离线RL 可以(且应该)和模仿学习(imitation learning)形成互补。Sergey 特别指出"离线RL不是RL预训练的唯一方式——LLMs 就是通过模仿学习(next-token prediction)进行预训练的"。这是一个精准的观察:
- 模仿学习预训练的优势在于简单、稳定——你只需要最小化与数据分布的差异,不存在 RL 特有的分布偏移和过度估计问题。GPT 系列和大多数 LLM 都采用了这条路线。
- 离线RL预训练的优势在于可以主动优化某个特定目标——在机器人等领域,如果数据中有大量的次优行为和一小部分优质行为,离线RL可以学会区分优劣并以优化为导向进行策略改进,而模仿学习只会尝试复现平均行为。
此外,Sergey 提到一个富有哲思的观点:理解离线RL可以帮助我们更好地理解RL本身。当你能在离线设定下训练出好的策略时,你实际上已经理解了RL中哪些组件是真正鲁棒的、哪些组件依赖了在线交互的"安全网"。这迫使算法设计者重新思考每个组件——Q函数的逼近、Bellman 更新的执行、探索-利用的权衡——在"无交互"约束下的本质含义。
实例与类比
自动驾驶中的实际应用场景:你作为自动驾驶公司的工程师,手头有数百万英里的真实驾驶数据(含各种天气、路况、驾驶员风格)。第一阶段,你用离线RL在这些数据上训练一个基础驾驶策略。经过离线训练后,这个策略已经学会了基本的方向盘和油门控制,能在简单场景中行驶。第二阶段,你把这个策略部署到封闭测试道路上(可控的安全环境),让它通过少量在线交互微调——这些微调专门针对离线数据中覆盖不足的边缘场景(如罕见的道路施工、极端天气下的行人行为等)。最终,你得到了一个既稳健又高效的驾驶系统。这个工作流远比从零开始在仿真器中训练、然后直接"硬迁移"到真实道路要实用和安全得多。
关键要点
- 离线RL+在线微调=预训练+微调的经典范式在序列决策中的应用
- 离线训练解决了"冷启动"问题——避免在线RL前期的大量无效试错
- 在线微调针对OOD(out-of-distribution)状态和数据覆盖不足边缘场景进行精细化调整
- 离线RL与模仿学习是互补的预训练手段,各自适用于不同数据特性
→ 在确立了离线RL的宏大愿景后,一个自然的问题浮现出来:仅凭一批静态数据,怎么可能学到比数据中最好的行为还好的策略?这不就是"无中生有"吗?下一张 slide 揭示了离线RL的三大机制。

离线RL何以可能?三大核心机制
概念详解
面对"仅凭固定数据如何超越数据"的质疑,Sergey Levine 用三个简洁而有力的论点给出了回答:
1. 发现数据中的"好东西"(Find the "good stuff"):离线数据集通常不是同质的——它可能包含不同技能水平的操作员在不同条件下产生的行为轨迹。有些轨迹可能非常优秀(如专家操作员的演示),有些可能一般,有些可能很差。离线RL的第一步能力就是能够识别并"放大"数据中的优质行为模式。这本质上是一种信号选择(signal selection)——数据集中混合了好信号和坏信号,RL算法通过价值函数估计来区分它们。
2. 泛化(Generalization):深度神经网络的泛化能力意味着,在一个状态下的良好行为模式可以"指示"(suggest)在相似但未见过的状态下的良好行为。例如,如果数据集中有专家在"晴天高速公路"上的驾驶数据,以及专家在"小雨城市道路"上的驾驶数据,泛化机制可以帮助策略在"多云半高速公路半城市道路——数据集中没有精确覆盖"的混合状态中做出合理的推断。这是深度函数逼近的固有优点——在参数空间中,相似输入会产生相似输出。
3. 拼接(Stitching):这是离线RL最具特色的能力,也是本讲反复强调的核心概念。离线数据可能包含从状态 $s_A$ 到 $s_B$ 的优质轨迹片段,以及另一条从状态 $s_B$ 到 $s_C$ 的优质轨迹片段,但没有任何一条完整轨迹是从 $s_A$ 到 $s_C$ 的。离线RL如果能够将这两段"拼接"起来,就能产生一条比数据中任何一条完整轨迹都要好的新路径。这本质上是一种时域上的组合泛化(temporal compositional generalization)。
深度剖析
这三个机制之间存在清晰的逻辑递进关系。第一步(发现好东西)是最基础的——你需要先知道什么是好的。第二步(泛化)让"好"的定义不再局限于数据中精确见过的状态——相邻状态的行为可以进行合理的推断。第三步(拼接)则是从"局部的普遍化"跃迁到"全局的最优性"——将来自不同时空片段的优质行为组合成一个整体上比任何单一片段都更优的轨迹。
但拼接是一个非常棘手的挑战。考虑以下困境:假设数据中轨迹 A 从状态 $s_1$ 到 $s_2$(获得高奖励),轨迹 B 从 $s_2$ 到 $s_3$(也获得高奖励)。要拼接这两段,智能体必须在状态 $s_2$ 时执行与轨迹 A 中相同的动作,但在 $s_2$ 时它恰好处于两条轨迹的"交接点"。然而,如果在轨迹 A 生成时,$s_2$ 之后的状态转移受到了特定动作序列的上下文影响(例如,轨迹 A 中的 $s_2$ 状态可能蕴含了"即将左转"的信息,而轨迹 B 从 $s_2$ 开始是"保持直行"——这两种情境下 $s_2$ 虽然在状态表示上可能相似,但在动力学上需要非常不同的动作序列),那么简单拼接就会失败。这引出了后续课程(Lec 18-19)中关于模型基离线RL和高阶拼接的更深入讨论。
实例与类比
用烹饪来类比:你的离线数据集包含两段视频——一段展示了一位大厨如何"切洋葱"(从完整的洋葱到整齐的洋葱丁),另一段展示了如何"炒洋葱"(从整齐的洋葱丁到金黄色的炒洋葱)。没有任何视频展示了从"完整的洋葱"直接到"金黄色的炒洋葱"的完整过程。离线RL的任务就是:学习先从状态"完整的洋葱"走"切"这一步到达状态"洋葱丁",再从"洋葱丁"走"炒"这一步到达"炒洋葱",从而拼接出一个超越任何单段视频的新"菜谱"。关键挑战在于:你需要精确地在"洋葱丁"这个中间状态完成切换——切得太细或太粗都会影响炒的效果。
关键要点
- 机制一(发现好东西):价值函数学习区分数据中高低质量的行为,选择性"放大"优质信号
- 机制二(泛化):深度网络的参数共享使得在相邻状态中的好行为可以相互借鉴
- 机制三(拼接/Stitching):从不同轨迹片段组合出全新的、比任何单条轨迹更优的完整行为序列
- 拼接是离线RL最具特色但也最难实现的能力——它要求时域上的组合泛化
→ 说到拼接,这个概念可以进一步细化为两个尺度——宏观尺度和微观尺度。下一张 slide 通过直观的可视化展示了离线RL方法在拼接上应该做到什么。
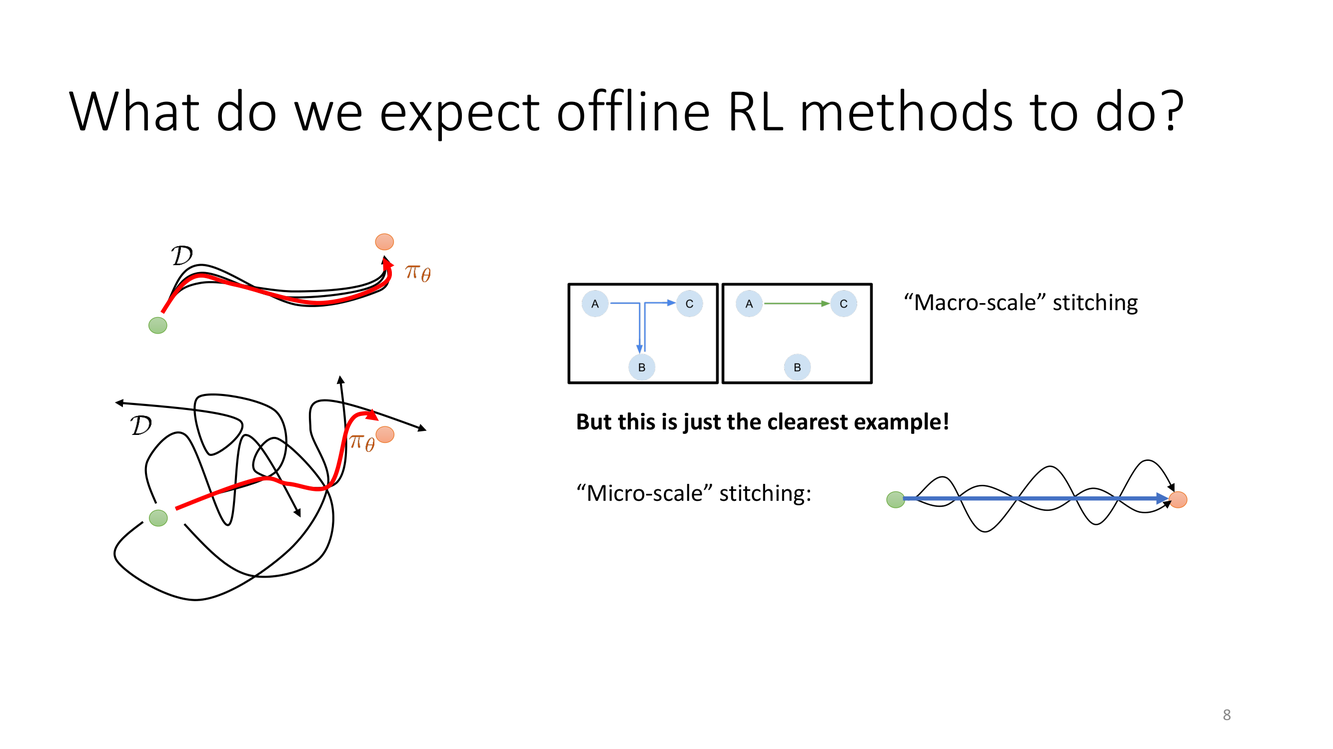
宏观拼接与微观拼接:离线RL的期望能力
概念详解
拼接(stitching)可以发生在两个不同的尺度上,理解这一区分对于评价离线RL算法的能力非常重要:
宏观拼接(Macro-scale stitching):这是最容易理解、也最直观的拼接形式。数据集中有两条完全不同的子任务轨迹——轨迹 A 展示了"从 A 到 B"的最佳路径,轨迹 B 展示了"从 B 到 C"的最佳路径。离线RL需要学会在 B 点把两段"粘合"在一起,从而产生一条 A → B → C 的全新路径。这在 slide 左侧的图示中有清晰的展示——两条不同颜色的轨迹在中间某个状态处"对接"。
微观拼接(Micro-scale stitching):这是更为精细但也更为普遍的拼接需求。在每一时刻,数据中可能有多种不同的"局部"行为片段(如略微不同的转向角度、细微不同的加速力度等),这些片段没有形成完整的"宏观"子任务,但它们可以以各种微妙的组合方式产生新的行为模式。微观拼接发生在几乎每一步决策中,而不只是在少数几个"交接点"。
深度剖析
Sergey 特别强调:"宏观拼接只是最清晰的例子!"("But this is just the clearest example!")。这句话暗示了一个重要的认识论转变:不要把拼接看作一种特殊的能力或偶尔需要调用的机制,而应该把它理解为离线RL价值函数学习的核心——即由动态规划(dynamic programming)驱动的 Bellman 备份天然地就是一种微观拼接。
让我们回顾 Bellman 最优方程的核心结构:
$$Q^*(s, a) = r(s, a) + \gamma \max_{a'} Q^*(s', a')$$
这个递归式本身就蕴含着拼接——当前的 Q 值依赖于下一步的最优 Q 值,而下一步的最优 Q 值可能来自数据集中的另一条完全不同的轨迹。当你执行一个 Bellman 更新时,你实际上是在说:"在状态 $s$ 下执行动作 $a$ 的价值,等于即时奖励 $r$ 加上后续最优行为的价值 $\max_{a'} Q(s',a')$。"注意这里的 $\max_{a'}$ 不关心 $a'$ 是来自哪条轨迹——它在所有数据中搜索最好的后续动作。因此,Bellman 备份天然地执行了拼接。
理解这一点至关重要:Bellman 备份的拼接能力是离线RL可能超越数据的理论基础。问题不在于"能不能拼接",而在于"如何在拼接时不引入灾难性的外推误差"——这正是第二部分要深入讨论的分布偏移问题。
实例与类比
宏观拼接:一个机器人需要在厨房中完成"拿杯子→倒水→端水到桌子"的任务。数据集里有"拿杯子"的轨迹和"端水到桌子"的轨迹,但没有完整的"拿杯子→倒水→端水到桌子"轨迹。宏观拼接就是在"倒水完成"这个中间状态处将两段粘合。微观拼接:在每一毫秒的运动控制中,数据集中有多个不同"风格"的微小动作片段——有的轨迹里机器人手臂微微向上偏移,有的微微向左——离线RL需要选择在每一步选择哪个微观风格,以整体上最小化耗能或最大化稳定性。
关键要点
- 宏观拼接:组合完整子任务轨迹 — 直观但罕见
- 微观拼接:在每步决策层次上进行局部行为组合 — 普遍存在,是Bellman备份的本质
- Bellman最优方程天然执行微观拼接:$\max_{a'}$ 跨越所有数据中的后续行为
- 拼接是离线RL的理论基础设施——问题不在于"能不能",而在于"如何安全地"做
→ 我们花了大量篇幅说明离线RL为什么令人兴奋、它能做什么。但热情需要让位于冷静的分析——现在让我们面对离线RL的核心敌人:分布偏移(distributional shift)。
第2章:分布偏移(Distributional Shift)
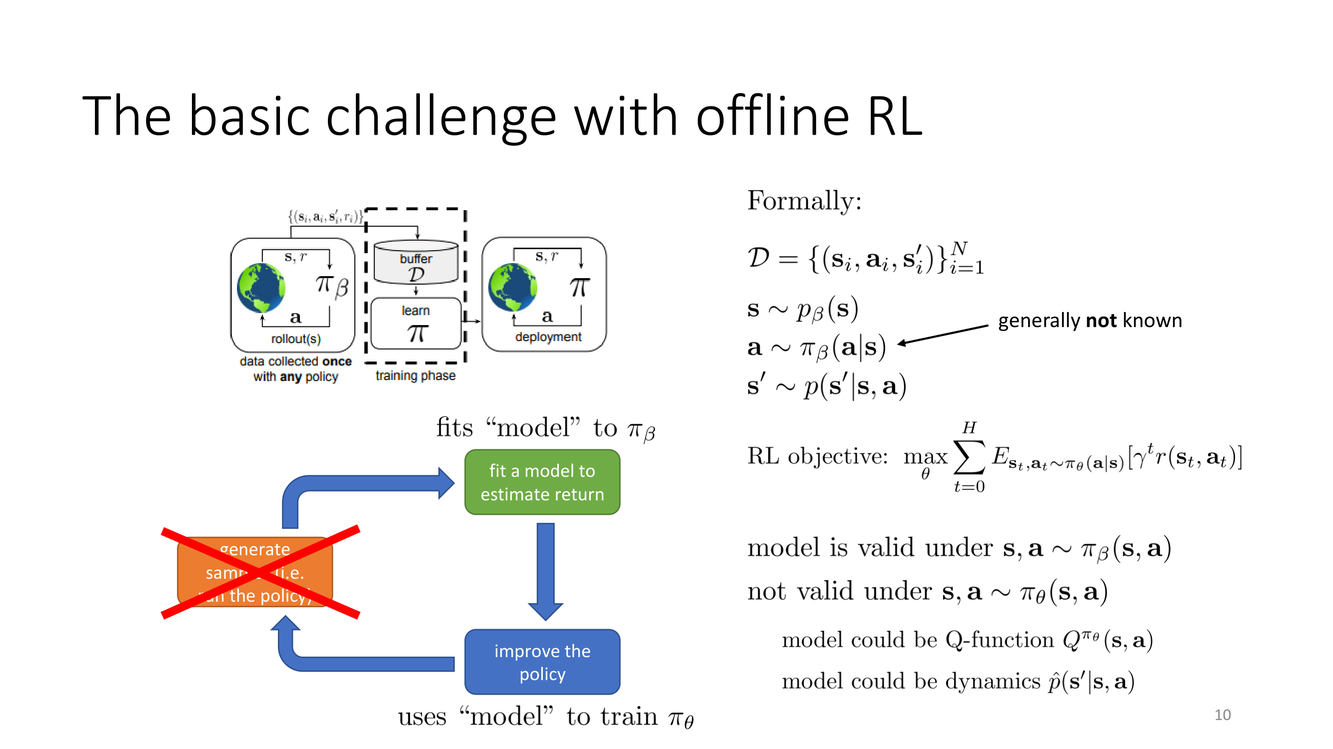
离线RL的基本挑战:被切断的反馈回路
概念详解
标准强化学习算法可以被解构为三个紧密耦合的组件,形成一个自我强化的反馈回路:
- 生成样本(Generate samples):用当前策略 $\pi_\theta$ 与环境交互,产生轨迹数据 $(s_t, a_t, r_t, s_{t+1})$。这些样本天然地分布在策略 $\pi_\theta$ 访问的状态-动作空间内。
- 估计回报(Fit a model to estimate return):根据采集的数据,更新价值函数 $Q(s,a)$ 或拟合一个动力学模型 $\hat{p}(s'|s,a)$。由于数据来自当前策略,价值估计在策略访问的区域具有较低的近似误差。
- 改进策略(Improve the policy):利用改进后的回报估计来更新策略参数 $\theta$,使策略朝着价值更高的方向移动——例如通过 $\theta \leftarrow \theta + \alpha \nabla_\theta J(\theta)$ 进行梯度上升。
这三个步骤构成一个自我调整的平衡系统:策略的分布决定了数据的分布,数据的分布决定了价值估计的准确度,而价值估计的准确度又反过来约束策略改进的方向和幅度。在在线RL中,这个过程缓慢而稳定地"漂流"向越来越好的策略。
在离线RL中,这个反馈回路被从根部切断了:第一步"生成样本"不再可能——数据是固定的、来自未知的行为策略 $\pi_\beta$(behavior policy)。第二步和第三步仍然执行,但它们在"真空"中运行——策略更新后无法去实际环境中"验证"那些新策略选择的状态-动作对是否真的如价值函数所估计的那样好。
深度剖析
问题的本质可以形式化为训练-测试分布不匹配(train-test distribution mismatch)。设:
- $p_{\text{train}}(s,a)$ = 离线数据集中状态-动作对的分布(由 $\pi_\beta$ 决定)
- $p_{\text{test}}(s,a)$ = 我们学到的策略 $\pi_\theta$ 在真实环境中访问的状态-动作分布
在标准监督学习中,我们依赖 $p_{\text{train}} \approx p_{\text{test}}$(独立同分布假设)来保证泛化。但在离线RL中,$\pi_\theta$ 被有意地训练为偏离 $\pi_\beta$——如果它不偏离,它就永远不能超越数据中的行为。因此,$p_{\text{train}} \neq p_{\text{test}}$ 是离线RL的本质属性而非偶然问题。价值函数 $Q(s,a)$ 在训练分布上拟合得很好,但在测试分布上可能存在巨大的泛化误差。
更糟糕的是,这种偏差不会自我纠正——因为无法从环境中获得新数据,我们永远无法知道 $Q(s,a)$ 在那些"新"的状态-动作对上是否准确。这直接导致了本章后续讨论的反事实查询和过度估计问题。
实例与类比
类比:想象你是一个股票分析师,你的"数据集"是过去5年所有股票的每日走势和对应收益。你训练一个模型来预测"如果我今天买入这只股票,明天的收益是多少"。你的训练数据告诉你,当某个技术指标出现时,买入通常有利可图。但问题是——这个结论是基于市场在那些指标出现时恰好有某种结构的前提。如果你的"策略"建议你在一个历史上从未与该指标同时出现的市场环境中买入(比如一个完全不同的利率环境),你的预测可能完全失效。而在标准监督学习中,你不会遇到这个问题——因为你不试图"改变市场",你只预测市场本身。
关键要点
- 标准RL的三大组件(采样→估计→改进)在离线设定下被切断:采样环节不可用
- 分布偏移不是bug而是feature——策略必须偏离数据分布才能超越数据
- $p_{\text{train}} \neq p_{\text{test}}$ 是离线RL的根本矛盾
- 价值函数在OOD区域的外推可能产生灾难性错误,且无法通过交互纠正
→ 为了更具体地理解这个问题,让我们看一个直观的例子——反事实查询。
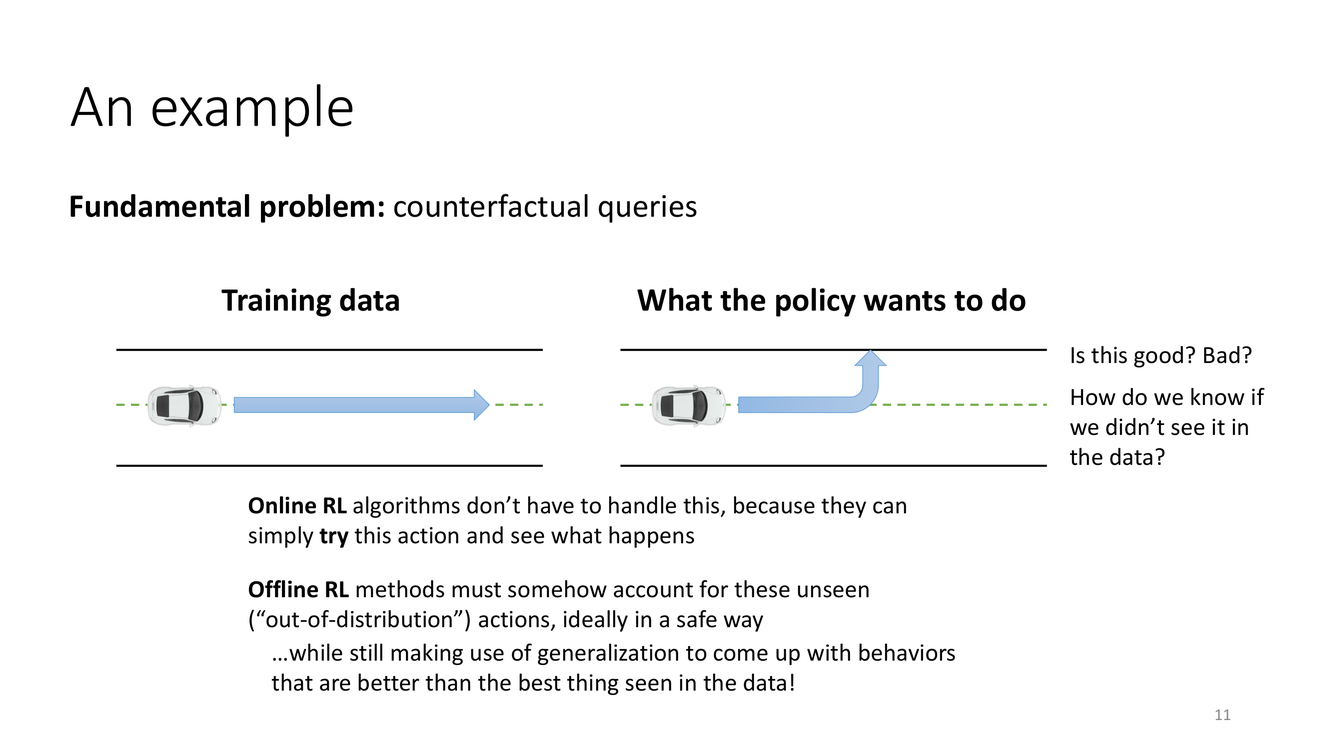
反事实查询:离线RL的根本困境
概念详解
反事实查询(Counterfactual Query) 是因果推断中的核心概念,在离线RL中扮演着关键角色。在因果推断中,一个反事实问题是:"如果当初做了不同的事,结果会怎样?"(What would have happened if we had done X instead of Y?)在RL中,这对应于:给定状态 $s$,数据中只记录了实际执行的动作 $a_{\text{data}}$(由行为策略 $\pi_\beta$ 选择),但学习者(当前策略 $\pi_\theta$)可能想选择一组不同的动作 $a_{\text{new}}$。计算 $Q(s, a_{\text{new}})$ 就是一个反事实查询——"如果我们在状态 $s$ 下选择了不同于数据的动作 $a_{\text{new}}$,预期收益是多少?"
在在线RL中,这个问题不存在,因为你可以直接尝试 $a_{\text{new}}$,观察环境反应,然后更新你的价值估计。但离线RL中,你只能依靠对已有数据的拟合来回答这个反事实问题——而这正是神经网络的泛化/外推能力被推到极限的地方。Slide 上的图示非常传神:左边是训练数据(Training data)的分布,右边是策略想要去的地方(What the policy wants to do)。两者之间的差距直观展示了问题的本质。
深度剖析
让我们把这个问题放到更形式化的框架中。考虑标准的 Bellman 最优算子 $\mathcal{T}^*$:
$$(\mathcal{T}^* Q)(s, a) = r(s, a) + \gamma \mathbb{E}_{s' \sim p(\cdot|s,a)} \left[ \max_{a'} Q(s', a') \right]$$
在离线RL中,我们对 $\mathcal{T}^* Q$ 的估计依赖于一个经验性版本的算子 $\hat{\mathcal{T}}^*$,它仅在有数据覆盖的状态-动作对上被定义:
$$(\hat{\mathcal{T}}^* \hat{Q})(s_i, a_i) = r_i + \gamma \max_{a'} \hat{Q}(s_i', a')$$
这里的关键在于 $s_i, a_i, r_i, s_i'$ 都来自离线数据集 $\mathcal{D}$。当 $\pi_\theta$ 在某个状态 $s$ 下建议一个数据集中罕见的动作 $a_{\text{OOD}}$ 时,$\hat{Q}(s, a_{\text{OOD}})$ 的值完全取决于神经网络的外推行为。而神经网络的外推行为在训练分布之外是不可预测的——它可能给出一个极其乐观(过度高估)的值,从而在策略改进步骤中被 $\max_{a'}$ 操作贪婪地选中,形成一个自我强化的错误循环。
Sergey 用极简的语言总结了问题的严重性:"Is this good? Bad? How do we know if we didn't see it in the data?"——我们根本无法知道,因为没有数据覆盖就意味着没有经验性的依据。而标准 RL 算法对此毫无抵抗力。
实例与类比
想象一个自动驾驶数据集,所有的人类驾驶员在一个特定路口遇到黄灯时都选择刹车(因为数据收集策略偏保守)。离线RL训练的策略可能"推断"出——如果在这个路口黄灯时加速冲过去,会获得更高的奖励(因为能更快到达目的地奖励点)。但问题是,数据中没有任何信息可以告知"加速冲过去"后的真实后果(比如是否有横向来车)。Q函数在"黄灯+加速"这个反事实查询上可能给出一个天真的乐观估计——比如说"奖励+100"——因为神经网络看到"加速"这个动作在其他状态下与高奖励相关联(比如在空旷的高速公路上加速)。但在黄灯路口加速显然是非常危险的。然而因为没有交互反馈,RL算法永远不会知道这一点。
关键要点
- 反事实查询:"如果选择了数据中没有的动作 a_new,会怎样?"——无法经验性验证
- 标准RL(在线)可以直接尝试来回答反事实问题;离线RL只能依赖外推
- 神经网络在OOD区域的外推是不可靠的——可能产生乐观偏差
- max 操作在策略改进时贪婪地利用这种乐观偏差,形成错误的正反馈
→ 反事实查询引出了一个更广泛的问题——分布偏移(distributional shift)。分布偏移到底有多严重?下一张 slide 用一个经典的类比给出了令人难忘的答案。

分布偏移到底有多严重?
概念详解
Sergey 用一个经典而且非常幽默的类比来总结分布偏移的严重性:
"想象你为一场数学考试做足了准备(Imagine you prepare for a math exam),然后你拿到了一份古希腊文学试卷(and get an exam on ancient Greek literature)。"
在标准监督学习中,分布偏移通常不被认为是一个致命的问题——因为 i.i.d. 假设意味着训练集和测试集来自同一个分布。即使有轻微的分布偏移(比如训练数据是在夏天收集的,测试数据在冬天),深度神经网络通常展现出令人惊讶的鲁棒性——它们能够通过大量参数和隐式正则化机制在分布边界附近实现一定程度的泛化。因此,在监督学习社区中,"分布偏移"往往是一个边缘话题(直到 domain adaptation 和 domain generalization 等子领域的兴起)。
但在离线RL中,事情有着本质的区别:分布偏移不是偶然发生的,而是算法主动制造和追求的。策略改进步骤(policy improvement)被设计为有意识地偏离行为策略——因为如果不偏离,性能就不会提升。这意味着 RL 训练的每一次更新都在主动创造更大的分布偏移。
深度剖析
让我们用一个更技术性的视角来看待这个问题。离线RL与监督学习在误差传播上有本质区别。在监督学习中,一个训练样本的预测误差 $\hat{y}_i - y_i$ 是局部性的——它只影响那个特定的样本,不会"感染"其他样本。但在RL中,由于 Bellman 备份的递归性质:
$$Q(s,a) \leftarrow r + \gamma \mathbb{E}_{s'} [\max_{a'} Q(s', a')]$$
在状态 $s'$ 处的一个 Q 值估计误差会向后传播到所有能转移到 $s'$ 的先前状态-动作对。这形成了一个误差的"滚雪球"效应——一个在小区域内出现的外推误差,可以沿着 Bellman 备份链条扩散到整个状态空间。
更关键的是,策略改进步骤中的 $\max_{a'}$ 操作使得误差传播具有系统性偏向高估(systematic overestimation bias)。因为在没有数据覆盖的区域,神经网络可能随机地某些动作赋予较高值、更低值——而 $\max$ 操作会贪婪地选择那些被高估的动作。每一次 Bellman 更新都可能让这个高估值变得更高,因为在下一步的更新中,被高估的 $Q(s',a')$ 会通过 Bellman 方程反馈到当前 $Q(s,a)$ 中。
实例与类比
Sergey 的"数学考试→古希腊文学"类比还可以进一步细化。在监督学习中,如果你训练了一个数学题解答模型,然后给它一道稍微超纲的物理题(相关领域),它可能还能应付——因为数学和物理共享一些代数推理能力。这对应了深度网络的插值泛化。但在RL中,策略改进相当于你给模型一道完全无关的题(古希腊文学 vs 数学),并且你不仅要求它给出答案,还要求它的答案比所有已知解答更好(对应 max 操作)。RL在OOD区域同时押注于"泛化正确"和"超越最好"——两个概率都很低的事件相乘,失败几乎不可避免。
关键要点
- 离线RL中分布偏移是算法主动制造的(策略改进必然偏离行为策略)
- RL的Bellman备份导致误差传播:局部OOD误差沿递归链扩散到全局
- max操作引入系统性高估偏差——选择性地放大OOD区域的随机乐观估计
- "数学考试→古希腊文学"类比:RL不仅要求泛化,还要求在OOD区域"做得更好"
→ 为了更精确地分析问题,下一张 slide 将分布偏移放入经验风险最小化(ERM)的框架中进行形式化审视。
经验风险最小化(ERM)与泛化:监督学习的视角
概念详解
为了理解为什么离线RL中的分布偏移如此致命,我们需要先理解为什么在监督学习中它通常不是问题。监督学习中最核心的训练范式是经验风险最小化(Empirical Risk Minimization, ERM):
我们希望最小化真实风险(true risk):
$$R_{\text{true}}(\theta) = \mathbb{E}_{(x,y) \sim p_{\text{data}}}[\mathcal{L}(f_\theta(x), y)]$$
但由于 $p_{\text{data}}$ 通常未知,我们用经验风险(empirical risk)来近似它:
$$R_{\text{emp}}(\theta) = \frac{1}{N}\sum_{i=1}^{N} \mathcal{L}(f_\theta(x_i), y_i)$$
其中 $\{(x_i, y_i)\}_{i=1}^N$ 是从 $p_{\text{data}}$ 中 i.i.d. 采样得到的训练集。当 $p_{\text{data}}$ 等于测试分布时,经验风险最小化能够保证 $\hat{R}_{\text{emp}}$ 收敛到 $R_{\text{true}}$,且泛化误差可以用统计学习理论(如 VC 维、Rademacher 复杂度)来界定。
此外,ERM 等价于最大似然估计(MLE)——在分类任务中使用交叉熵损失、在回归中使用均方误差损失,都是在给定模型下最大化观测数据的似然函数。
深度剖析
在监督学习中,"泛化"一词通常指在同分布(in-distribution)测试集上的表现——即测试样本来自与训练样本相同的采样分布。当我们说"神经网络泛化得很好"时,我们指的是它能够对训练时未见过的、但来自同一底层分布的新样本做出准确预测。这是一种插值泛化(interpolation generalization)——测试点位于训练分布的支撑集之内或紧邻。
但在离线RL中,情况完全不同。设离线数据分布为 $\mu(s,a)$(由行为策略 $\pi_\beta$ 诱导产生的状态-动作联合分布)。RL的策略 $\pi_\theta$ 被训练为在分布 $\pi_\theta(a|s)$ 下最大化价值,而 $\pi_\theta(a|s)$ 与 $\pi_\beta(a|s)$ 有系统地不同。这导致 $Q(s,a)$ 被要求对 $\mu(s,a)$ 的支持集之外的输入进行准确预测——这是一种外推泛化(extrapolation generalization),远比插值泛化困难且不可靠。深度网络虽然在插值上表现出色,但在外推上常常给出任意且不稳定的输出,因为它们没有在那些区域接受过任何形式的约束或指导。
Slide 上的公式很可能展示了经典的 ERM 框架——训练集损失 $\frac{1}{N}\sum_{i=1}^N \mathcal{L}(f_\theta(x_i), y_i)$——来强调监督学习范式天然依赖于 i.i.d. 假设,而这个假设在离线RL中被系统性地违反了。
实例与类比
举一个CIFAR-10图像分类的例子:你用5万张训练图像训练了ResNet,然后在1万张测试图像上获得了95%的准确率。这就是标准的插值泛化——测试图像虽然网络从未见过,但它们与训练图像来自同一个"自然图像"分布。如果你把这个模型拿去给X光医学图像做分类(完全没有在训练数据中),准确率会暴跌。这就是外推——网络在没有数据支持的区域做出了任意的猜测。离线RL中的OOD动作就像是那些"X光医学图像"——策略想要做的那些动作在训练数据中可能完全没有出现过,Q函数却要被迫给出一个"准确"的价值估计。
关键要点
- ERM(经验风险最小化)依赖 i.i.d. 假设,在监督学习中通常不构成问题
- 插值泛化(in-distribution)≠ 外推泛化(out-of-distribution),前者可靠,后者极其不可靠
- 离线RL要求Q函数进行外推——对数据支持集之外的状态-动作对给出准确估计
- 神经网络在OOD区域的外推行为没有理论保障
→ 既然我们已经从监督学习的角度理解了分布偏移的普遍性,接下来的问题是:在具体的RL方法(policy gradient、Q-learning、actor-critic)中,分布偏移是如何具体表现出来的?

分布偏移在各类RL方法中的具体表现
概念详解
这三张连续的 slides 可能是本讲中最重要的技术性内容。Sergey 系统地审视了分布偏移如何在三种主要的 off-policy RL 方法中显现出来:
1. Policy Gradient(策略梯度方法)
在标准的策略梯度中,梯度估计的形式为:
$$\nabla_\theta J(\theta) \approx \frac{1}{N}\sum_{i=1}^N \nabla_\theta \log \pi_\theta(a_i|s_i) \cdot \hat{Q}(s_i, a_i)$$
但在离线设定中,数据由 $\pi_\beta$ 生成而非 $\pi_\theta$。这就引入了重要性采样(Importance Sampling)的需求:
$$\nabla_\theta J(\theta) = \mathbb{E}_{(s,a) \sim d^{\pi_\beta}} \left[ \frac{\pi_\theta(a|s)}{\pi_\beta(a|s)} \nabla_\theta \log \pi_\theta(a|s) \cdot \hat{Q}(s, a) \right]$$
这里的重要性比率(importance ratio) $\frac{\pi_\theta(a|s)}{\pi_\beta(a|s)}$ 就是分布偏移的直接体现。当 $\pi_\theta$ 和 $\pi_\beta$ 在给定状态下分配的动作概率差异较大时,这个比率可能极大或极小,导致梯度估计的方差爆炸(exploding variance)。更糟的是,当 $\pi_\beta(a|s) \approx 0$ 而 $\pi_\theta(a|s) \gg 0$ 时(即策略偏好数据中几乎从未出现过的动作),这个比率趋于无穷大——这就是 slide 上所说的 "ratio very far from 1.0 = exploding variance"。
2. Q-Learning(Q学习)
Q-learning 的更新规则使用 Bellman 最优性算子:
$$Q(s,a) \leftarrow r + \gamma \max_{a'} Q(s', a')$$
分布偏移在 Q-learning 中以一种更为隐蔽但可能更为致命的方式显现——通过 $\max_{a'}$ 操作。在数据分布的支持集内,$Q(s',a')$ 的值是相对可靠的(因为这些 $(s',a')$ 对出现在训练数据中)。但在数据支持集之外,$Q(s',a')$ 是外推的结果。而 $\max$ 操作恰好会积极选择那些被外推高估的动作——因为外推误差会使某些OOD动作的 Q 值人为偏高,$\max$ 就会选择它们。
这造成了 slide 上指出的关键困境:反事实问题的答案具有"高方差"(high variance)——取决于你碰巧在数据中看到了什么。对于 $(s',a')$ 在训练分布中的情况,答案相对确定;对于OOD情况,答案完全取决于网络的随机外推行为。
3. Actor-Critic
在 actor-critic 方法中,两种问题同时存在:Critic(价值函数)遭受与 Q-learning 相同的 $\max$ 过度估计问题;Actor(策略)通过最大化 Critic 的输出进行更新,从而受到 Critic 外推误差的直接引导。这导致了 slide 16 中提出的策略约束(policy constraint)的动机——"just don't go there"(干脆不要去那里)。既然OOD区域的 Q 值不可靠,最简单的策略就是强制 $\pi_\theta$ 不选择那些OOD动作。
深度剖析
让我们更深入地分析 actor-critic 中分布偏移的复合效应。考虑 actor 的更新(确定性策略的情况):
$$\theta \leftarrow \theta + \alpha \nabla_\theta \mathbb{E}_{s \sim \mathcal{D}} [Q_\phi(s, \pi_\theta(s))]$$
这个更新依赖于链式法则 $\nabla_a Q_\phi(s,a)|_{a=\pi_\theta(s)} \cdot \nabla_\theta \pi_\theta(s)$。如果 $Q_\phi$ 在 $\pi_\theta(s)$ 附近给出了过于乐观的估计(因为 $\pi_\theta(s)$ 可能恰好处于一个OOD区域),梯度 $\nabla_a Q_\phi$ 会引导 $\pi_\theta$ 进一步深入那个OOD区域——一个自我强化的灾难循环。
在 SAC(Soft Actor-Critic)中,这个效应因为有 entropy bonus 而被部分缓解(熵正则化鼓励策略保持一些随机性,自然地限制了它过于自信地集中到少数动作上),但远远不够。下一张 slide 将展示 SAC 在离线设定下的实证结果——你会看到,即使是最好的 off-policy 算法,在没有特殊处理的情况下,也会在离线数据上遭受灾难性的性能崩溃。
这也引出了一个深层的哲学问题:在离线RL中,"泛化"的能力和"过度泛化"的风险是一体两面的。泛化让我们能够从有限的数据中推理出更广泛的规律(这是RL的核心优势),但同样的泛化机制也使得Q函数在OOD区域产生不可靠的外推。如何保留泛化的好处同时控制其风险,这是整个离线RL领域的核心研究问题。
实例与类比
用金融来类比:Policy gradient 的重要性比率问题就像是用少数几个极端值的平均来估计总体均值——如果某个投资者赚了100倍(重要性比率很大),而其他人都亏了,样本均值会被极端值严重扭曲。Q-learning 的 max 操作问题则像是"基金经理选择偏差"(survivorship bias)——你只看到那些幸存下来的(被max选中的OOD动作被赋予了高Q值),却看不到那些失败的(被低估的OOD动作从未被选中,因此它们的低估永远不会被发现和纠正)。Actor-critic 则结合了这两者的风险。
关键要点
- Policy Gradient:重要性比率 $\frac{\pi_\theta}{\pi_\beta}$ 导致方差爆炸——当策略严重偏离行为策略时梯度估计不可靠
- Q-Learning:$\max_{a'}$ 系统性选择被外推高估的OOD动作——"幸存者偏差"式的高估
- Actor-Critic:Actor受Critic的外推误差引导,形成自我强化的错误循环
- 策略约束("just don't go there")是应对分布偏移的最直接思路
→ 理论分析清楚地揭示了脆弱性,但这些分析到底有多严重?让我们看一个具体的实证例子——SAC在离线数据上的表现。
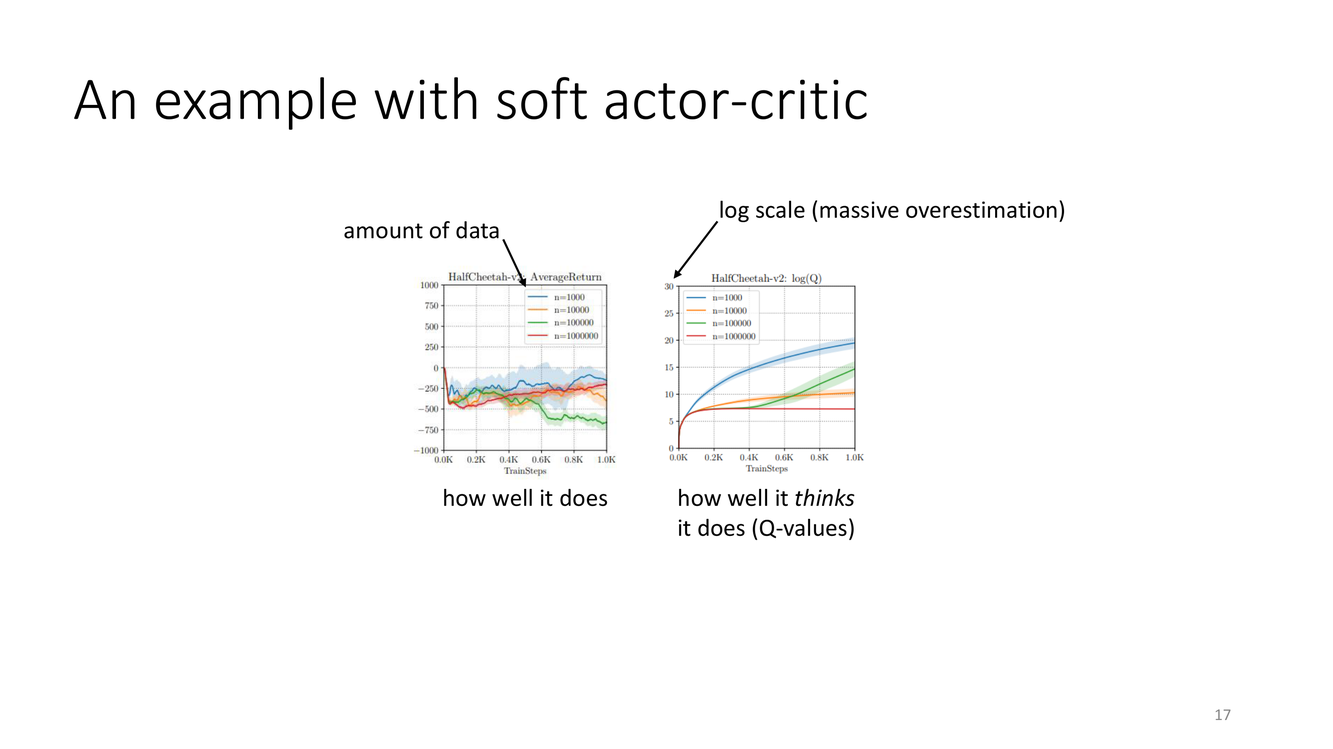
SAC的离线灾难:实证证据
概念详解
这张 slide 是整讲中最重要的实证结果展示,它用数据和图表无可辩驳地证明了离线RL问题的严重性。实验的设定是:使用 Soft Actor-Critic(SAC)——当时最先进的 off-policy RL 算法之一——在标准的离线数据集上训练,不添加任何离线特定的修改。结果的呈现涉及两条关键的曲线:
- "how well it does"(实际表现):策略在真实环境中的测试表现(如累积奖励)。这条曲线衡量的是策略的真实性能。
- "how well it thinks it does"(自我评价):Critic(Q函数)对策略的估计价值。这条曲线衡量的是算法对自己表现的"自信程度"。
如果算法工作正常,这两条曲线应该大致重合(即Q函数的估计与实际性能相符)。但实验结果令人震惊——随着训练数据和训练步数的增加,两条曲线急速背离:Q值呈对数级增长(massive overestimation),而实际性能却持续下降。
深度剖析
这个现象的最令人担忧之处在于:当我们给算法更多的数据(横轴"amount of data"增加)时,它不仅没有变好,反而变得更差。这在直觉上是反常的——在监督学习中,更多的数据几乎总是带来更好的泛化性能。为什么在离线RL中更多的数据会导致更差的性能?
答案隐藏在 actor-critic 的动态平衡中。当数据量增加时,行为策略 $\pi_\beta$ 的数据覆盖范围也增大——这意味着在数据支持集的边界处,有更多的"边界区域"(boundary regions)供Q函数进行外推。更多的边界意味着更多的机会让Q函数产生外推误差。每一个这样的误差——即使最初非常微小——都会在 Bellman 备份的循环中通过策略改进步骤被放大和传播。随着训练步骤的增加,这些误差累积成一个巨大的、自我实现的"乐观偏差"。更糟的是,实际性能不仅没有提高反而下降——因为策略被错误的高Q值引导到了数据中从未充分覆盖的危险区域。
这在深层上反映了离线RL中的一个反直觉悖论:更多的数据并不一定更好,数据质量(覆盖的全面性和策略的多样性)远比数据数量重要。在一个"窄且单一"的数据集上(比如全是专家轨迹),策略反而不太可能产生OOD动作(因为它只需要模仿专家的行为模式即可)。在一个"宽但混杂"的数据集上(比如混合了专家和随机探索的轨迹),策略有更大的空间去"想象"新的动作组合,从而面临更严重的分布偏移风险。
实例与类比
用"考试自信度"来类比:想象一个学生在考试前做了大量练习题(数据量增加)。正常来说这应该提高考试成绩。但如果学生从不检查答案的对错(没有在线交互来纠错),反而可能会形成"虚假的自信"——随着练习量的增加,学生越来越相信自己"理解"了材料(Q值上升),但实际上他学到的是错误的理解(实际表现下降)。在学生的主观感受中,似乎一切都很好——但这些自信是建立在未经验证的推理之上的。SAC 的离线崩溃就是这种"不检查答案的过度自信"在数学上的精确体现。
关键要点
- SAC 在离线设定下同时出现:Q值对数级爆炸增长(过度估计)和实际性能持续下降
- "自己觉得自己很好"与"实际表现很差"之间的背离是离线RL失败的标志性信号
- 更多数据不一定更好——更宽的数据支持集意味着更大的OOD外推风险
- 数据质量(覆盖全面性、行为多样性)远比数据数量重要
→ SAC的失败不是孤例,而是一个普遍规律的体现——在线设定下可控的错误在离线设定下被无限放大。下一张 slide 从理论角度分析了为什么这些错误在离线RL中不会被自我纠正。

在线RL vs 离线RL:错误的自我纠正机制
概念详解
这张 slide 是对前述所有讨论的总结和升华。Sergey 指出:标准RL中存在两种固有的误差来源——采样误差(sampling error)和函数逼近误差(function approximation error)——它们在任何RL算法中都存在,但在在线设定和离线设定下,它们的命运截然不同。
在线RL设定下:这些误差是可容忍的。原因是存在一个自我纠正机制(self-correcting mechanism)——当策略因为价值估计误差而被引导到一个"错误"的方向时,它会在下一步通过与环境的实际交互发现自己的错误。如果Q值高估了某个动作的价值,策略会倾向于选择那个动作。但一旦动作被执行,真实的环境会返回实际的奖励和下一状态,这些真实的反馈会逐渐修正之前的高估。因此,在线RL形成了一个负反馈系统——误差导致行为改变,行为获得新数据,新数据修正估计误差。虽然这个过程可能很慢(需要大量交互),但它具有稳定性。
离线RL设定下:这个自我纠正机制被完全切断。策略由于Q值的误差被引导至OOD区域、选择了之前从未见过的动作,但这并不会产生新的数据来进行纠正。因此,原来在在线RL中"可容忍"的采样误差和函数逼近误差,在离线RL中变成了"滚雪球"式的放大——每一个微小的初始误差都被 Bellman 备份和策略改进的循环不断放大,因为没有外部反馈来刹车。从控制理论的角度看,离线RL的系统变成了一个正反馈系统——误差自我强化。
深度剖析
将这个问题从信息论的角度理解更为深刻。在线RL拥有一个关键的信息通道:环境反馈通道(environment feedback channel)。这个通道不断地为价值函数和策略提供"真实的"监督信号(至少在预期的意义上——$r$ 和 $s'$ 是真实动力学和奖励函数的采样)。离线RL则完全失去了这个信息通道——它唯一的信息来源是固定的数据集 $\mathcal{D}$,而这个数据集是在一个未知的旧策略下收集的。
从贝叶斯推理的角度,在线RL中的先验(Q函数的当前信念)可以通过似然(新数据的证据)持续更新。在离线RL中,我们没有新的似然信息——数据是固定的,因此我们的一切"改进"都只能来自先验(参数化Q函数的平滑泛化)的重新组合。这就像是在一个封闭的信息系统中进行推理——在没有新信息注入的情况下,推理最终会"漂移"到与事实无关的方向上。
这也解释了为什么离线RL中,简单地"训练更久"或"使用更大的网络"往往不仅不会提高性能,反而会加速失败——更大的网络具有更强的外推能力(在OOD区域产生更极端、更多变的输出),而更长的训练时间意味着更多的Bellman备份循环,每个循环都可能在传播和放大外推误差。
实例与类比
GPS导航的类比:在线RL就像是一个有实时GPS信号的导航系统——如果你走错了路,GPS会立刻告诉你并重新规划路线。离线RL则像是你只看一张几个月前买的老地图——你可能根据这张地图推断出了一条"近路"(策略改进),但你没有GPS信号来验证这条路在现实中仍然畅通。如果那条路实际上已经因为施工封路了,你的地图(数据)并没有包含这个信息——你会继续沿着错误的路线走,直到无路可走。
关键要点
- 在线RL形成负反馈系统(误差→行为→新数据→修正),具有内在稳定性
- 离线RL形成正反馈系统(误差→行为→无新数据→误差放大),缺乏稳定性保证
- 环境反馈通道的缺失是离线RL的根源性脆弱性——失去信息更新的来源
- "训练更久"和"更大的网络"在离线RL中可能加速失败(更强的外推+更多的错误传播循环)
→ 既然我们彻底诊断了问题——分布偏移、反事实查询、系统性过度估计、以及缺失的自我纠正机制——现在是时候讨论解决方案了。第三部分聚焦于现代离线RL中最基础也最重要的一类方法:策略约束(policy constraints)。
第3章:策略约束(Policy Constraints)

离线RL的三大原则性方法
概念详解
在深入策略约束的数学细节之前,Sergey 给出了离线RL方法论的一个高层分类。他总结了三种基本的设计原则——它们共享深层逻辑(都以某种方式处理分布偏移),但在实现这一目标的手段上有所不同:
原则一:悲观主义(Pessimism)——代表方法:CQL (Conservative Q-Learning)
核心思想是:既然Q函数在OOD区域倾向于过度估计,那就主动地、系统性地压低这些区域的Q值。CQL通过在标准Bellman误差之上添加一个正则化项来实现这一点——该项惩罚那些在数据集中不常见但Q值很高的动作。形式化地:
$$\mathcal{L}_{\text{CQL}} = \mathcal{L}_{\text{Bellman}} + \alpha \left( \mathbb{E}_{s \sim \mathcal{D}, a \sim \pi_\theta} [Q(s,a)] - \mathbb{E}_{s,a \sim \mathcal{D}} [Q(s,a)] \right)$$
这个额外的正则化项强制Q函数对策略偏好的动作($\mathbb{E}_{a \sim \pi_\theta}[Q(s,a)]$)给出比数据中实际动作($\mathbb{E}_{a \sim \mathcal{D}}[Q(s,a)]$)更低的估计——除非数据已经"证明"了某些策略偏好的动作确实很好。这本质上是一种保守的(conservative)价值估计,避免了对未知动作的乐观外推。
原则二:策略约束(Policy Constraints)
核心思想是:既然问题的根源在于 $\pi_\theta$ 偏离 $\pi_\beta$ 太远导致OOD动作,那就显式地限制策略与行为策略之间的距离。通过学习一个优化目标,它不直接最大化Q值,而是最大化Q值的同时惩罚 $\pi_\theta$ 与 $\pi_\beta$ 之间的某种散度(divergence):
$$\max_\theta \mathbb{E}_{s \sim \mathcal{D}} \left[ \mathbb{E}_{a \sim \pi_\theta(\cdot|s)} [Q(s,a)] - \alpha \cdot D(\pi_\theta(\cdot|s) \| \pi_\beta(\cdot|s)) \right]$$
这是本章剩余部分的核心议题。
原则三:避免OOD动作参与更新(Avoid OOD actions in updates)——代表方法:IQL (Implicit Q-Learning)
核心思想是:将策略改进和价值函数学习解耦。在标准actor-critic中,actor通过最大化Q函数的输出来更新策略——这天然地涉及对OOD动作(新策略选择的动作)的Q值估计。IQL通过一种巧妙的技术——期望回归(expectile regression)——来训练价值函数,使其只对数据中已经出现过的动作给予准确值,而不需要对策略建议的新动作进行外推。具体而言,IQL使用以下形式的更新来逼近 $\max Q$ 而不需要显式地对OOD动作求 $\max$:
$$V(s) = \mathbb{E}_{a \sim \pi_\beta(\cdot|s)} \left[ Q(s,a) \right]$$
其中通过不对称的损失函数(对高于 $V(s)$ 的 $Q(s,a)$ 赋予更高权重)来隐式地编码 $\max$ 操作,但只考虑数据中已有的动作。
深度剖析
将这三个原则放在一起比较,可以看出它们在"干预位置"上的差异,形成了一个完整的解决方案空间:
- CQL(悲观主义)干预的是Critic(Q函数)——修改Q函数的训练目标,使其在OOD区域输出悲观(低)值。优点是简单直接且理论保证较强,缺点是过度悲观可能会抑制有价值的探索。
- 策略约束干预的是Actor(策略)——限制策略的搜索空间,使其不进入Q函数估计不可靠的区域。优点是将问题从"修复Q函数"转化为"限制策略",使两者各司其职(Critic专注在数据内的准确估计,Actor被安全地约束在这个区域内优化)。缺点是当行为策略本身表现不佳时,约束可能限制策略的改进空间。
- IQL(避免OOD动作)干预的是Actor-Critic的耦合方式——通过解耦策略改进和价值学习,从根本上避免OOD动作参与Bellman更新。这是最"优雅"的方案——它不修改任何组件的内在功能,而是改变它们的交互方式。然而,在复杂的拼接场景中,完全避免OOD动作也可能限制了算法发现全新行为组合的能力。
在实践中,这三种原则并不是互斥的——很多最先进的离线RL方法结合了它们中的两个甚至三个。本讲的余下部分聚焦于策略约束,因为它是概念上最直接、教学上最清晰的方法。
实例与类比
用一个"围墙花园"的类比来理解三种方法的关系:
- CQL 是在花园围墙外的空地上竖立"危险⚠"的警示牌——降低围墙外区域的价值估计,使策略尽可能不出去
- 策略约束 是把花园的围墙建高——物理上阻止策略走出去,即使策略"想"出去
- IQL 是改变花园的设计——使得从花园内部(数据中的动作)已经足够做出最优决策,从而根本不需要"出墙"
关键要点
- CQL(悲观主义):压低OOD区域的Q值——干预Critic
- 策略约束:限制策略不偏离行为策略——干预Actor
- IQL:解耦策略改进和价值学习——干预Actor-Critic耦合方式
- 三种方法可组合使用,形成更强大的离线RL算法
→ 在三大原则中,策略约束是最直观的——它的核心思想"just don't go there"在上一部分已经反复出现。现在让我们进入它的数学细节。

策略约束的形式化
概念详解
策略约束的核心思想可以直接形式化为一个带约束的优化问题:我们希望在最大化期望Q值的同时,确保策略 $\pi_\theta$ 与行为策略 $\pi_\beta$ 之间的距离不超过某个阈值 $\epsilon$。标准的策略优化目标(如DDPG中的确定性策略梯度)是:
$$\max_\theta \mathbb{E}_{s \sim \mathcal{D}} \left[ Q(s, \pi_\theta(s)) \right]$$
策略约束版本将其修改为:
$$\max_\theta \mathbb{E}_{s \sim \mathcal{D}} \left[ Q(s, \pi_\theta(s)) \right] \quad \text{s.t.} \quad D(\pi_\theta(\cdot|s) \| \pi_\beta(\cdot|s)) \leq \epsilon$$
其中 $D(\cdot\|\cdot)$ 是某种概率分布之间的距离度量(最常用的是KL散度),$\epsilon$ 是允许的最大偏离程度。这个形式可以通过拉格朗日松弛(Lagrangian relaxation)转化为无约束优化:
$$\max_\theta \mathbb{E}_{s \sim \mathcal{D}} \left[ \mathbb{E}_{a \sim \pi_\theta(\cdot|s)} [Q(s,a)] - \alpha \cdot D_{\text{KL}}(\pi_\theta(\cdot|s) \| \pi_\beta(\cdot|s)) \right]$$
其中 $\alpha$ 是拉格朗日乘子,控制约束的严格程度。当 $\alpha \rightarrow \infty$ 时,策略被迫完全复制 $\pi_\beta$(相当于行为克隆);当 $\alpha \rightarrow 0$ 时,退化为无约束的actor-critic。
Slide 上有一句重要的注释公式:"up to a constant"(常数差异范围内)。这指的是 KL 散度约束与策略改进的单调性保证之间的关系——在一定的条件下(行为策略与当前策略之间的KL散度受控),策略改进可以保证单调递增。
深度剖析
这个形式化与我们在本课程早期学到的 TRPO(Trust Region Policy Optimization,第13讲)之间存在深刻的理论联系。在TRPO中,策略更新也受KL散度约束的限制:
$$\max_\theta \mathbb{E}_{s \sim d^{\pi_{\text{old}}}, a \sim \pi_\theta} \left[ \frac{\pi_\theta(a|s)}{\pi_{\text{old}}(a|s)} A^{\pi_{\text{old}}}(s,a) \right] \quad \text{s.t.} \quad D_{\text{KL}}(\pi_{\text{old}} \| \pi_\theta) \leq \delta$$
注意两个关键的差异:
- 约束方向:TRPO约束的是 $\pi_{\text{old}} \| \pi_\theta$(从旧策略到新策略的前向KL),而离线RL的策略约束通常约束的是 $\pi_\theta \| \pi_\beta$(从行为策略到学习策略的KL散度——这涉及到"前向KL vs 后向KL"的讨论,见下一张 slide)。
- 动机:TRPO使用KL约束是为了保证策略改进的单调性(防止策略更新过大导致性能崩溃),而离线RL的策略约束是为了防止策略进入Q函数不可靠的OOD区域。前者关注的是优化稳定性,后者关注的是分布偏移下的安全性。
尽管动机不同,但两者共享同一个数学工具——KL散度约束——这说明TRPO与离线RL的策略约束方法之间可能存在深层的理论统一性。
实例与类比
用"跑步训练"来类比:一个教练(Q函数)建议你今天的训练计划是"跑20公里"。但你昨天只跑了5公里(行为策略)。无约束的策略更新可能会让你今天就尝试20公里——结果可能是受伤(OOD动作的灾难性后果)。策略约束相当于在你的训练计划中加入一条规则:"本周的训练量不能超过上周的150%"。这确保了你的进步是渐进的、安全的——每次都在已有经验的"舒适区"边缘扩展,而不至于冒然进入完全未知的区域。
关键要点
- 策略约束将actor更新改为:$\max \mathbb{E}[Q] - \alpha \cdot D_{\text{KL}}(\pi_\theta \| \pi_\beta)$
- $\alpha$ 控制约束强度:$\alpha \to \infty$ = 行为克隆,$\alpha \to 0$ = 无约束actor-critic
- 与TRPO的理论联系:都使用KL约束,但动机不同(优化稳定性 vs OOD安全性)
- 拉格朗日松弛将有约束优化转化为无约束优化,便于实现
→ 策略约束的形式化看起来简单——加一个KL惩罚项就行。但它到底为什么能解决分布偏移?下一张 slide 通过可视化给出了直观的回答。
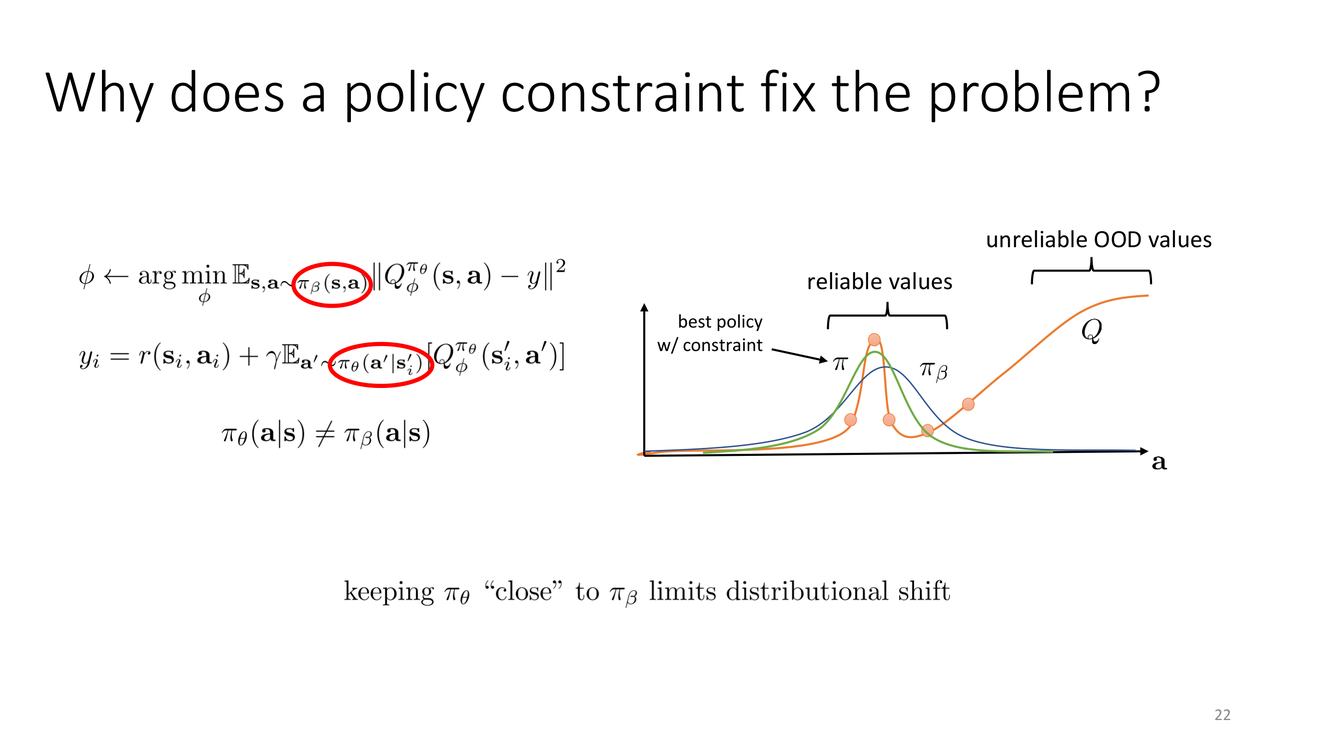
策略约束为何能解决分布偏移?
概念详解
这张 slide 通过一个精心设计的可视化,直观地展示了策略约束的核心洞察。图中的横轴代表动作空间(action space),纵轴代表Q值。关键元素包括:
- 数据支持集(data support):训练数据中实际出现的动作区域。在这个区域内,Q函数的估计是相对可靠的(有数据支持),图中的"reliable values"区域标出了这一点。
- OOD区域(out-of-distribution region):数据中未出现的动作区域。在这个区域中Q函数的值完全是外推的、不可靠的——"unreliable OOD values"。
- 无约束最优策略:在OOD区域的峰值处——Q函数在那些区域产生了人为的高估值(由外推导致),因此无约束的actor会被吸引到那里。
- 有约束最优策略:在可靠区域内的最高点——策略被约束在数据支持集内,所以它在"安全区"内找到最优解,避免了OOD区域的虚假高估值。
核心信息非常清晰:通过将策略限制在Q函数可靠的区域内,策略约束从根本上杜绝了策略被不可靠的Q值误导的可能性。策略仍然可以在数据支持集内进行优化——找到该区域内的最佳动作——但它不会被外推误差产生的"海市蜃楼"所诱惑。
深度剖析
这个可视化也揭示了一个微妙但重要的权衡——约束的松紧度与性能上界之间的权衡。如果约束太紧($\alpha$ 太大),策略只能在行为策略的极近邻域内搜索,这可能会限制其性能上界——因为如果在数据的支持集之外确实存在更好的动作(只是数据没有覆盖到),策略将永远无法发现它们。如果约束太松($\alpha$ 太小),策略可能会进入Q函数不可靠的OOD区域,导致与无约束情况相同的失败模式。
这引出了一个根本的张力:离线RL的性能上界由行为策略的覆盖质量(coverage quality)决定。如果 $\pi_\beta$ 在某状态 $s$ 下的支持集恰好覆盖了最优动作 $a^*(s)$ 的附近区域,那么策略约束就有机会找到接近最优的解。但如果 $\pi_\beta$ 的支持集与最优解的区域完全无交集——也就是说,行为策略的数据中完全没有"指向"最优解的线索——那么无论约束多松多紧,策略约束方法都无法找到最优解。这是离线RL的一个基本限制:数据决定上界。
这个限制直接关系到拼接(stitching)的可行性。拼接之所以"可能",正是因为行为策略的数据支持集虽然可能不直接包含最优动作,但由于Bellman备份的递推性质,局部正确的Q值估计(在有数据支持的动作上)可以沿着状态转移链传播,从而在"间接"的意义上为最优行为提供信号。
实例与类比
用地图类比来理解 OOD 区域中的"虚假峰值"。想象你在一个陌生城市里用百度地图找餐馆。地图APP的评分系统(Q函数)基于用户评价——在市中心区域(数据支持集)评分是可信的。但在郊区(OOD区域),由于评价样本很少,某家餐馆可能基于两个"好评"就显示为4.9分——这是一个不可靠的峰值。如果没有任何约束,你可能会被这个4.9分吸引到郊区的"假好评"餐馆。但如果约束自己只在市中心(数据支持集)内搜索,你可能找到一家真实的4.5分餐馆——虽然评分略低于虚假的4.9,但这是真实可靠的选择。
关键要点
- 策略约束将优化空间限制在Q函数可靠的数据支持集内
- 避免了OOD区域中外推产生的虚假高估值峰值
- 约束松紧度存在权衡:太紧限制性能上界,太松无法防止灾难性失败
- 离线RL的性能上界由行为策略的数据覆盖质量决定——数据决定上界
→ 策略约束的有效性已经清晰,但一个细节问题仍待解答:我们应该使用哪种具体的距离度量来定义"策略偏离行为策略"?最常见的两种选择——前向KL和反向KL——在实际效果上有根本性的差异。

前向KL与反向KL:模式覆盖 vs 模式寻求
概念详解
KL散度(Kullback-Leibler divergence)不是一个对称的距离度量——$D_{\text{KL}}(P \| Q)$ 与 $D_{\text{KL}}(Q \| P)$ 有截然不同的行为。在策略约束的上下文中,这个不对称性具有实质性的影响。让我们精确地定义这两个方向:
前向KL散度(Forward KL):$D_{\text{KL}}(\pi_\beta \| \pi_\theta)$
$D_{\text{KL}}(\pi_\beta \| \pi_\theta) = \mathbb{E}_{a \sim \pi_\beta(\cdot|s)} \left[ \log \frac{\pi_\beta(a|s)}{\pi_\theta(a|s)} \right] = \int \pi_\beta(a|s) \log \frac{\pi_\beta(a|s)}{\pi_\theta(a|s)} \, da$
前向KL被称为模式覆盖(mode covering)。为什么?因为积分是在 $\pi_\beta$(行为策略)的分布下进行的。这意味着前向KL"关注"的是 $\pi_\beta$ 有概率质量的地方——它对 $\pi_\theta$ 的要求是:在 $\pi_\beta$ 有概率质量的所有区域,$\pi_\theta$ 也必须分配足够的概率。换句话说,$\pi_\theta$ 必须"覆盖" $\pi_\beta$ 的所有模式。如果 $\pi_\theta(a|s)$ 在某处趋近于零(而 $\pi_\beta(a|s) > 0$),则 $\log(\pi_\beta / \pi_\theta)$ 趋于无穷大——这是不可接受的。
这在实际中意味着,前向KL约束强制学习策略 $\pi_\theta$ 在 $\pi_\beta$ 的每一个模式上都保持非零概率——即使 $\pi_\beta$ 的某些模式质量很低(低奖励的行为),$\pi_\theta$ 也不能忽略它们。
反向KL散度(Reverse KL):$D_{\text{KL}}(\pi_\theta \| \pi_\beta)$
$D_{\text{KL}}(\pi_\theta \| \pi_\beta) = \mathbb{E}_{a \sim \pi_\theta(\cdot|s)} \left[ \log \frac{\pi_\theta(a|s)}{\pi_\beta(a|s)} \right] = \int \pi_\theta(a|s) \log \frac{\pi_\theta(a|s)}{\pi_\beta(a|s)} \, da$
反向KL被称为模式寻求(mode seeking)。这次积分在 $\pi_\theta$(学习策略)的分布下进行。这意味着反向KL"关注"的是 $\pi_\theta$ 选择聚焦的区域。当 $\pi_\theta$ 选择在 $\pi_\beta$ 的某个单一模式上集中概率时,反向KL很小(因为在该模式上 $\pi_\theta / \pi_\beta$ 的比率接近某个常数值,而 $\pi_\theta$ 在 $\pi_\beta$ 没有覆盖的区域趋于零时会引入很大的惩罚)。关键是,$\pi_\theta$ 不需要覆盖 $\pi_\beta$ 的所有模式——它可以"寻求"(seek out)一个高质量的模式并且只聚焦于它。
深度剖析
在离线RL中,反向KL几乎总是更好的选择。其原因与离线RL的核心逻辑——我们希望找到行为策略模式中最有价值的那些,而不是被迫保留所有行为模式——完美吻合。
考虑一个典型的离线RL场景:数据集 $\mathcal{D}$ 由行为策略 $\pi_\beta$ 收集,而 $\pi_\beta$ 本身是一个多模态分布——它在某些状态下可能同时有"高风险高回报"的动作模式、"低风险低回报"的动作模式、以及一些"纯噪声"的随机动作模式。离线RL的目标是从这些模式中选择最好的(或者组合最好的),而不是被迫保留所有模式(包括那些随机噪声)。
- 前向KL:强制 $\pi_\theta$ 在 $\pi_\beta$ 的每一个模式上维持概率质量——包括那些纯噪声的动作。结果:学习的策略可能继承了行为策略的"噪音"成分。这就是 mode covering——为了覆盖所有模式,牺牲了对最优模式的聚焦。
- 反向KL:允许 $\pi_\theta$ 选择性地聚焦于高质量的模式,而忽略低质量模式。如果行为策略在某个状态下有三种可能的动作模式,其中一种对应高奖励行为而另两种是随机的,反向KL允许 $\pi_\theta$ 将概率完全集中在高奖励的模式上。这就是 mode seeking——主动寻找最优模式。
从优化角度理解:反向KL ≈ 前向KL + 熵正则化的某种变体(分析表明有相似之处)。反向KL对 $\pi_\theta$ 集中到少数高收益动作施加了"软"惩罚,但同时也允许它忽略行为策略的低回报模式。而前向KL则强制维持所有模式——这在实际中意味着策略可能"平均化"了好的行为和坏的行为,导致整体性能不高。
实例与类比
用"自助餐选择"来类比。行为策略 $\pi_\beta$ 像是各类食物在自助餐台上的分布——有美味的牛排(高质量模式)、普通的沙拉(中等质量模式)、和放了几天的冷盘(低质量模式)。前向KL = 你必须每种都吃一点(包括冷盘),因为 $\pi_\beta$ 在每一种食物上都有分布。反向KL = 你可以专注于牛排,完全忽略冷盘——只要你的盘子($\pi_\theta$)上的食物在 $\pi_\beta$ 的"菜单"上出现过就行。反向KL让你成为一个"挑剔的食客"——这是离线RL中你想要的策略行为。
关键要点
- 前向KL $D_{\text{KL}}(\pi_\beta \| \pi_\theta)$ = mode covering:强制覆盖行为策略的所有模式
- 反向KL $D_{\text{KL}}(\pi_\theta \| \pi_\beta)$ = mode seeking:允许有选择地聚焦于高质量模式
- 在离线RL中,反向KL几乎总是更好的——不强制保留低质量的噪音行为模式
- 积分分布(前向在 $\pi_\beta$ 下,反向在 $\pi_\theta$ 下)决定了差异化行为
→ 既然我们已经确定了反向KL是更优的方向,那么下一个问题是:反向KL本身是"理想"的吗?是否存在比普通反向KL更好的约束形式?

理想的约束:"支持集约束"(Support Constraint)
概念详解
对策略约束的讨论最终归结为一个问题:什么才是"理想"的约束?Sergey 在这张 slide 中给出了令人满意的回答——反向KL与支持集约束的结合。
反向KL($D_{\text{KL}}(\pi_\theta \| \pi_\beta)$)已经是比前向KL更好的选择,因为它允许策略选择性聚焦于高质量的行为模式。但它仍然有一个局限:即便在行为策略的支持集内,它也会对概率密度的分配施加惩罚。例如,如果数据中某个动作出现的概率是 0.3,而 $\pi_\theta$ 想给它分配 0.9 的概率,反向KL会对这个"浓度增加"施加损失(因为 $\log(0.9/0.3) > 0$)。这本身不一定有问题——你确实希望策略不要过于"极端"——但在某些情况下,最优的策略可能确实需要在 $\pi_\beta$ 支持集内的某些动作上更"自信"(集中概率)。
因此出现了"支持集约束"(support constraint)的概念——也被称为 behavior-regularized MDP 框架。其核心思想是:
区分"在支持集内"和"不在支持集内"。在 $\pi_\beta$ 的支持集(support,即 $\pi_\beta(a|s) > 0$ 的所有 $a$ 的集合)内,不施加惩罚(或只施加非常轻微的惩罚),允许策略自由地在这些动作之间分配概率;只有对于支持集之外的、完全不可能在行为策略下出现的动作,才施加严厉的惩罚。
形式化地,支持集约束的惩罚项可以写为:
$$\mathcal{R}_{\text{support}}(\pi_\theta) = \mathbb{E}_{s \sim \mathcal{D}} \left[ \max_{a: \pi_\beta(a|s) < \epsilon} \log \pi_\theta(a|s) \right] \quad \text{(示例形式之一)}$$
这种惩罚只在 $\pi_\theta$ 给那些行为策略几乎从不选择的动作分配概率时才激活。
深度剖析
Sergey 在 slide 底部坦承了两个关键事实:
- "we like this because we are not forced to 'keep' bad modes with low reward"——支持集约束保留了反向KL的模式寻求特性,不会被低质量的数据模式拖累。
- "only pay the penalty for actions that really can't happen under the behavior policy, but allow any behavior that can happen in the data"——区分了"偏离原始分布"和"完全超越数据支持"两种情况。在支持集内的概率重分配被允许,真正被惩罚的只有完全 OOD 的动作。
- "very hard to approximate tractably"——这是关键的现实问题。在实际的高维连续动作空间中,判断一个动作是否在 $\pi_\beta$ 的支持集内是非常困难的。$\pi_\beta$ 本身通常是未知的(你需要从数据中估计它),而"支持集"的边界在连续空间中是一个微妙的概念——$\pi_\beta(a|s)$ 可能在很多动作上非零(由于数据收集过程中的噪声、探索噪声等),但那些非零值是极其微小的。在这种情况下,"支持集"的阈值如何设定是一个棘手的实践问题。
这解释了为什么在实践中,大多数现代离线RL方法(如CQL, IQL, TD3+BC等)并没有直接实现"支持集约束"的精确版本,而是通过各种近似手段来逼近相同的效果:
- CQL 通过保守的Q值估计间接实现——Q函数对OOD区域的低估自然阻止了策略去那里
- IQL 通过只在数据中的动作上训练Q函数来完美避开整个OOD问题
- TD3+BC 通过在actor损失中直接添加行为克隆正则项,使用普通的MSE损失而非KL散度
支持集约束是理论上的"柏拉图理想型"——指明了应该追求的方向——而实际算法是该理想的各种"务实近似"。
实例与类比
用"自由市场vs管制经济"来类比:前向KL就像高度管制的计划经济——你必须按照行为策略的精确"配比"来生产和消费,不能有偏差。反向KL像是有一定自由度的市场经济——你可以在行为策略提示的"可行选项"内进行优化选择。支持集约束则是最小化管制——"法无禁止即可为":只要行为策略的数据证明某件事"可能"(在支持集内),你就去做;只有在完全没有先例(支持集外)的情况下,管制才会介入。在离线RL中,这种最小侵入性的约束是最理想的——它在不妨碍学习的前提下,防止了致命性的外推错误。
关键要点
- 支持集约束是策略约束的"理想型":在 $\pi_\beta$ 支持集内自由优化,仅在完全OOD时施加惩罚
- 保留了反向KL的模式寻求好处(不被低质量模式拖累),同时放宽支持集内的概率分配限制
- 实践中的主要困难:连续空间中"支持集"难以精确界定;$\pi_\beta$ 需从数据中估计
- 现代方法(CQL, IQL, TD3+BC)通过不同近似手段逼近支持集约束的效果
- 本讲为后续课程(Lec 18-19)中更高级的离线RL方法(模型基方法、CQL的严格理论分析)奠定了概念基础
→ 本讲至此完成了离线RL的入门全景——从动机(为什么需要离线RL)、到问题(分布偏移和OOD外推)、到解决方案(三大原则及策略约束的深入分析)。下一讲(Lec 18)将深入模型基离线RL方法,Lec 19 将更严格地分析CQL及其他悲观性方法的理论性质。离线RL的故事远远没有结束——它只是刚刚展开了地图。