CS 285 深度学习强化学习 — 第16讲 详细讲义
第1章:使用模型进行规划(Planning with Models)

规划范式的三个层次:确定性、开环随机、闭环随机
概念详解
第16讲从第15讲的"为什么学模型"自然过渡到"学了模型之后怎么用"。Slide 3 精准地承接了上一讲的终点:上一次我们讲了如何用不确定性感知的模型来处理分布偏移——可以运行之前学过的算法——但"有更好的选择"。本讲的核心词是规划(planning):使用模型来做决策,而不显式地维护一个策略函数。
Slide 4-7 建立了一个由浅入深的规划范式谱系:确定性(deterministic)→ 随机开环(stochastic open-loop)→ 随机闭环(stochastic closed-loop)。这三种范式的根本区别在于动作序列与状态之间的信息依赖关系。
在确定性规划(Slide 4)中,给定初始状态 $s_1$ 和动力学模型 $f_\phi$,只需优化一条确定的动作序列 $a_1, a_2, \ldots, a_H$——因为模型本身是确定的,未来的状态被动作完全决定。在随机开环规划(Slide 5)中,模型是随机的,但动作序列仍然在"见到"任何实际的状态之前被一次性完全确定——这意味着动作的选择不能对未来的随机结果做出反应。Slide 5 厉声质问:"why is this suboptimal?"(为什么这是次优的?)。在随机闭环规划(Slide 7)中,策略 $\pi(a_t|s_t)$ 在每个时间步根据实际到达的状态做出决策——这是最优的,但需要策略的参与,因而与"纯规划"的思想产生了张力。
Slide 6 澄清了术语的本质:"loop"(环路)指的是信息流的方向。闭环(closed-loop):状态反馈到动作选择——双向信息流。开环(open-loop):动作序列在 $t=1$ 发送出去后就"一去不复返"——单向信息流。这个区分在控制理论中历史悠久,但在 model-based RL 中具有独特的内涵:开环规划简化了计算(只需优化一个序列而非一个策略),但以丧失对随机性的应对能力为代价。
深度剖析
开环规划为什么次优?考虑一个随机动力学:$s_{t+1} \sim p(\cdot|s_t, a_t)$。在一个随机环境中,未来的状态轨迹存在多种可能的分支。开环规划为所有可能的分支指定完全相同的动作序列——如果环境在第 $t=3$ 步随机地走到了一个出人意料的状态,动作 $a_4$ 仍按原计划执行,而不是针对这个新状态进行调整。闭环策略 $\pi(a_t|s_t)$ 能观察实际到达的状态并适应——但这也意味着我们不再仅仅是在"规划",而是在"学习策略"——二者的边界逐渐模糊。
从优化的角度看,确定性规划的优化变量是 $H$ 个动作向量:$\mathbf{a} = (a_1, \ldots, a_H) \in \mathbb{R}^{H \cdot d_a}$。随机开环规划的优化变量是一个动作序列分布 $p(a_1, \ldots, a_H)$——这在概念上等价于优化一个序列的分布参数。随机闭环规划则优化策略参数 $\theta$——这回到了策略优化,是 model-based 和 model-free 的交汇点。Sergey 在 Slide 8 中说"But for now, open-loop planning"——承认闭环最优,但先从开环入手,因为它的数学和计算更简单,且对于短视界问题(short-horizon)常常足够好。
开环规划的价值常被低估。在许多实际场景中——如机器人抓取(只需规划一条到达目标点的路径)或短时域的模型预测控制(MPC)——开环规划加上周期性的重规划(replanning)可以在实践中近似闭环行为:每执行一个(或几个)动作后重新求解开环规划问题,用新的状态观测来修正计划。这种"开环 + 重规划"范式是 MPC 的核心思想,也是 model-based RL 中 bridge 开环和闭环的实用手段。
实例与类比
开环 vs 闭环的区别可以用"发短信导航"vs"实时导航"来类比。确定性规划相当于你在出发前打印了一份详细的路线说明,严格按照"直行 500 米 → 右转 → 直行 200 米"的指令前进——只要路况和预期完全一致,你能到达目的地。开环随机规划相当于你在出发前准备了一叠"如果-则"卡片,但到达每个路口时并不检查实际路况——你直接翻下一张卡片执行下一组指令。如果施工导致某个路口封闭(随机事件),你仍然按照预先准备的那组指令走——结果可能是绕远路或迷路。闭环规划(或闭环策略)相当于你开着实时导航——GPS 在每个路口根据你的实际位置重新计算最优路线。这种对实时信息的利用正是闭环相对于开环的根本优势。
关键要点
- 三种规划范式:确定性(模型确定,一条轨迹)→ 随机开环(模型随机,但动作序列预先固定)→ 随机闭环(策略根据状态实时调整)
- 开环次优的根本原因:无法对随机环境的实际实现做出适应性反应——"发出去就收不回来"
- "开环 + 重规划"(MPC 范式)是实践中弥补开环缺陷的关键手段
- 闭环最优但回到了"学策略"领域——本讲先聚焦开环
→ 接受了开环规划的设定之后,核心问题变为:如何在动作序列空间中高效搜索?Slide 8-10 介绍了从最简单到最经典的两种随机优化方法。

随机打靶法与交叉熵方法(CEM)
概念详解
Slide 9 介绍了开环规划中最简单直接的方法:随机打靶法(Random Shooting Method)。其思想近于原始的"猜然后检验"(guess & check):从某个提议分布 $p(a_1, \ldots, a_H)$ 中采样 $N$ 条候选动作序列;使用学到的模型 $\hat{p}_\phi$ 将每条序列展开为完整的轨迹 $\tau_i = (s_1, a_1^i, s_2^i, \ldots, s_H^i, a_H^i)$;用模型预测的奖励计算每条轨迹的累积奖励 $J(\tau_i) = \sum_t \hat{r}(s_t^i, a_t^i)$;选择奖励最高的序列作为输出。
随机打靶法的问题是方差极大——在一个高维动作空间中($H \cdot d_a$ 维),从固定分布中盲目采样,绝大多数候选序列的奖励都很低(或不可行)。Slide 10 引入了交叉熵方法(Cross-Entropy Method, CEM)作为自然升级:迭代地精炼提议分布——每一轮采样的"精英"序列(奖励最高的前 $M$ 条)被用来更新提议分布的参数(通常是一个高斯分布),使下一轮的采样向高奖励区域集中。
CEM 的数学核心是重要性加权更新:设提议分布为 $\mathcal{N}(\mu, \Sigma)$。每轮采样 $N$ 条序列,选出奖励最高的前 $K$ 条("精英集" $\mathcal{E}$)。然后用精英集的样本均值与协方差来更新 $\mu$ 和 $\Sigma$:
$$\mu_{\text{new}} = \frac{1}{K}\sum_{i \in \mathcal{E}} \mathbf{a}_i, \quad \Sigma_{\text{new}} = \frac{1}{K}\sum_{i \in \mathcal{E}} (\mathbf{a}_i - \mu_{\text{new}})(\mathbf{a}_i - \mu_{\text{new}})^\top$$这相当于在动作序列空间中执行一种无梯度的分布优化——逐步将搜索集中在最有希望的区域。Slide 10 也提到了与之相关的 CMA-ES(Covariance Matrix Adaptation Evolution Strategy)——可以理解为"带动量项的 CEM",通过对协方差矩阵的平滑更新来增强稳定性。
深度剖析
CEM 在低维动作空间(如 $d_a \leq 10$)和短规划视界($H \leq 50$)中表现良好,但有几个关键弱点值得深究:
协方差退化(Covariance Collapse):随着迭代进行,$\Sigma$ 可能迅速收缩到接近奇异——这意味着搜索分布坍缩到一个极窄的区域,丧失了探索能力。如果这个窄区域恰好是一个局部最优(由模型误差造成的虚假高峰——回想第15讲的"海市蜃楼"),CEM 将在那里停滞。实践中常用正则化技术(对角加载 $\Sigma \leftarrow \Sigma + \lambda I$、最小特征值截断)来防止过早坍缩。
维度灾难的软版本:虽然 CEM 比纯粹的随机打靶更高效,搜索空间仍然是 $H \cdot d_a$ 维。当 $H$ 增长时,精英集的比例需要相应增大(否则精英集太小,协方差估计噪声很大),但总采样预算 $N$ 又受模型前向传播的计算成本限制。这导致一个根本性的权衡:样本数 vs 迭代数 vs 搜索空间维度。
CEM 与策略梯度的关系:CEM 可以被看作一种特殊的策略优化——它优化一个开环动作序列分布,使用"精英选择"作为奖励信号的二值化(精英 = 奖励高于阈值,非精英 = 忽略),更新方式类似于对分布参数的自然梯度。实际上,将 CEM 推广到闭环策略分布(即优化策略参数 $\pi_\theta$ 的分布,而非动作序列的分布)可以联系到后来的 PETS(Probabilistic Ensembles with Trajectory Sampling) 和 MB-MPO(Model-Based Meta-Policy Optimization)。
实例与类比
CEM 的运作机制可以用蒙眼射箭的比喻来理解。随机打靶法相当于你蒙着眼朝整个靶场随意射 $N$ 支箭,然后选离靶心最近的那一支——大部分箭会完全脱靶。CEM 相当于先射 $N$ 支箭观察落点分布,然后只看那最靠近靶心的 $K$ 支箭的落点,下次瞄准时把瞄准点调整为那些精英箭的平均落点——你的瞄准逐渐向靶心收敛。但如果靶场有几个虚假的"靶心幻影"(模型的"海市蜃楼"),而你恰好有几支箭落在幻影附近——你的瞄准可能被引向完全错误的方向——这就是模型偏差对 CEM 的"劫持"。
关键要点
- 随机打靶 = 从固定分布采样 → 选最优序列。简单但方差太高
- CEM = 迭代精炼提议分布(用精英集的统计量更新高斯分布的 $\mu$ 和 $\Sigma$)
- CEM 面临协方差退化、维度限制、模型偏差(海市蜃楼)三大脆弱性
- CEM 与策略优化的深刻联系:都是"分布优化",区别在于是优化动作序列分布还是策略分布
→ CEM 在低维短视界问题上效果可靠,但 Slide 11 坦率地列出了它作为通用规划器的根本局限——并打开了通往其他规划范式的大门。

CEM 的局限、替代方法与不确定性下的规划
概念详解
Slide 11 以毫不含糊的方式总结了随机优化方法(随机打靶、CEM 及其变种)的两大根本限制:
限制 1:非常严厉的维度上限(Very harsh dimensionality limit)。动作空间的维度是 $H \cdot d_a$——当规划视界 $H$ 增长或动作维度 $d_a$ 增加时,搜索空间呈指数级膨胀。在实践中,CEM 在 $H \cdot d_a \lesssim 100$ 的范围内是可行的,超过这一界限,即使迭代精炼也无法在合理的采样预算内覆盖有意义的搜索体积。
限制 2:仅为开环规划(Only open-loop planning)。CEM 输出的是一个固定的动作序列——它不能在执行过程中根据实际到达的状态做出调整。对于涉及接触、碰撞、多模态转移分布的复杂动力学,开环序列无论多精细,都无法匹敌闭环策略的适应性。
Slide 11 列举了三种适用于不同场景的替代规划范式:蒙特卡洛树搜索(Monte Carlo Tree Search, MCTS)——通过树的生长与 UCB 式节点选择在离散动作空间中高效搜索,AlphaGo/AlphaZero 的核心引擎;连续轨迹优化(如 LQR / iLQR)——利用梯度信息在连续空间中高效求解最优控制,适用于局部模型是光滑可微的场景;基于树的运动规划(如 RRT/RRT*)——在配置空间中通过随机树扩展来探索高维连续空间,广泛用于机器人运动规划。
Slide 12 引出了本讲与第15讲的关键连接:如何在不完美的、有不确定性的模型下规划?如果我们有的是一个确定性模型的分布(distribution over deterministic models)——这正是第15讲的 Bootstrap Ensembles——我们可以在每个模型上独立执行确定性规划,然后聚合结果,或使用悲观/乐观修正。其他选项包括矩匹配(moment matching)——将模型分布的前两阶矩传入规划器——以及基于 BNN 的更复杂的后验估计。
Slide 13 展示了 model-based RL 在真实世界中的一个经典案例:Nagabandi et al. 2019 — Deep Dynamics Models for Learning Dexterous Manipulation。这项工作训练了一个基于深度网络的动力学模型来操控一只多指灵巧手执行物体旋转等复杂操作,是 model-based RL 在真实机器人上的里程碑式验证。
深度剖析
MCTS、LQR/iLQR 和 RRT 这三种替代规划范式各自利用了不同形式的结构先验来绕过 CEM 的维度灾难:MCTS 利用了问题的树结构和 UCB 的探索-利用平衡来有选择性地深入搜索最有希望的分支,而不是均匀覆盖整个空间;LQR/iLQR 利用了动力学的局部线性/二次近似,将非凸的轨迹优化简化为一系列可解析求解的凸子问题;RRT/RRT* 利用了配置空间的几何结构,通过 Voronoi 偏差自然地向未探索区域扩展。
关于不确定性下的规划(Slide 12),一种实用的方案是 Trajectory Sampling with Probabilistic Ensembles:从 $K$ 个 bootstrap 模型中随机选择一个,用该模型展开一条完整的轨迹(粒子传播,TS-1);或每一步从 $K$ 个模型中独立随机选择一个(TS-∞)。这种粒子级的不确定性传播既简单又高效——它不需要维护复杂的后验,只需利用 ensemble 的天然多样性来"采样"可能的未来。
实例与类比
三种替代规划范式对应于三种不同的"寻路智慧"。MCTS 像棋手:面对巨大的可能性树($35^{80}$ 个棋局),棋手不会在所有走法上均匀分配思考时间——她只深入计算最有希望的那几条线(UCB 引导的选择性展开)。LQR/iLQR 像高尔夫球手:果岭的精确几何也许无法全局完美建模,但在球周围的局部区域内,地表可以很好地近似为一个斜面——基于这个局部二次近似来校准推杆方向和力度。RRT 像在密林中探险的人:不试图绘制整片森林的精确地图,而是从当前位置向外随机延伸探索触角——触角自然地偏向于较少被探索的方向——最终一条或多条触角会"碰到"目标区域。
关键要点
- CEM 两大死穴:维度上限($H \cdot d_a$ 不能太大)+ 纯开环(不随状态自适应)
- 替代范式利用了结构先验:MCTS(树 + UCB)、LQR(局部线性二次)、RRT(空间几何)
- 不确定性下规划 = 在模型分布上聚合 + 悲观/乐观修正
- 真实世界案例:Nagabandi et al. 2019 — 深度动力学模型驱动多指灵巧手操作
→ 第1章聚焦于"如何用模型做规划"——从最简单的随机打靶到 CEM 再到不确定性感知的规划。第2章将视角转向另一个极端:如果规划太难,能不能用模型来辅助策略学习?
第2章:使用模型进行策略学习(Policy Learning with Models)

模型辅助策略学习:两条梯度通路的对决
概念详解
第2章以 Slide 15 的"概念性学到的模拟器算法"图重新开场——这是一个贯穿第15讲和第16讲的枢纽可视化:收集数据 → 学模型 → 在模型内运行算法 → 部署策略。不同的是,这一次幻灯片追问的核心变了:不是"模型学得好不好",而是"在模型内运行什么算法"。
Slide 16-17 引入了一个关键的技术分岔口。当我们在学到的模型中优化策略时,有两种根本不同的方法计算策略参数 $\theta$ 的梯度:
路径 1 — 策略梯度(Policy Gradient):
$$\nabla_\theta J(\theta) \approx \frac{1}{N}\sum_{i=1}^N \sum_{t=1}^H \nabla_\theta \log \pi_\theta(a_t^i|s_t^i) \cdot \hat{Q}(s_t^i, a_t^i)$$这里的 $\hat{Q}(s_t^i, a_t^i)$ 可以从模型展开中通过蒙特卡洛回报估计得到。梯度流不穿过动力学模型——模型只被用来生成轨迹 $(s_t^i, a_t^i)$ 并估计回报,梯度仅对策略的对数概率求导。
路径 2 — 反向传播梯度(Backprop / Pathwise Gradient):
$$\nabla_\theta J(\theta) = \nabla_\theta \mathbb{E}_{s_1}\left[ \sum_t \hat{r}(s_t, a_t) \right], \quad a_t = \pi_\theta(s_t), \quad s_{t+1} = \hat{f}_\phi(s_t, a_t)$$梯度穿过动力学模型 $\hat{f}_\phi$——使用链式法则将通过模型的奖励直接反向传播到策略参数。与策略梯度不同,这种方法要求模型是可微的。
Slide 17 引用了 Parmas et al. 2018 (PIPP) 的分析来阐明两种方法的权衡:策略梯度可能更稳定(如果使用足够的样本),因为它不需要通过模型传播梯度——从而避免了多个 Jacobian 矩阵的连乘可能导致的不稳定性。
深度剖析
反向传播梯度穿越模型时的数学结构揭示了其脆弱性的根源。展开一条 $H$ 步的轨迹,$a_H$ 对 $\theta$ 的梯度会经过 $H-1$ 个模型转移的 Jacobian:
$$\frac{\partial s_H}{\partial \theta} = \sum_{\tau=1}^{H-1} \left( \prod_{k=\tau+1}^{H-1} \frac{\partial \hat{f}_\phi}{\partial s_k} \right) \cdot \frac{\partial \hat{f}_\phi}{\partial a_\tau} \cdot \frac{\partial \pi_\theta}{\partial \theta}\bigg|_{s_\tau}$$这个连乘积 $\prod \frac{\partial \hat{f}_\phi}{\partial s_k}$ 随 $H$ 指数级地放大或缩小梯度——这就是梯度消失/爆炸(vanishing/exploding gradients)的经典问题在 model-based RL 中的具体表现。策略梯度不穿过模型,因此不受此困扰——但它牺牲了梯度的高效性(需要更多样本)。
PIPP 的核心贡献在于揭示了模型误差如何与梯度传播交互:一个微小的局部模型误差,在通过多条模型 Jacobian 的连乘后,可以产生巨大的偏差梯度——将策略更新引向无关甚至有害的方向。策略梯度虽也有方差,但它的偏差来自回报估计而非模型误差的二阶传播——在实践中往往更可控。
从计算角度,反向传播梯度可以非常高效——只需一次前向-反向传播(像训练一个超深网络),而策略梯度需要 $N \cdot H$ 次独立的前向展开(没有反向穿过模型)。这是一个偏置-方差-计算的三维权衡。
实例与类比
这两种梯度通路可以用"看天气预报出门"vs"出门后随时调整"来类比。反向传播梯度相当于你出发前用天气预测模型(学到的动力学)完整地模拟了整个行程——温度如何随时间变化($s_t \to s_{t+1}$)、每个时刻穿什么衣服($a_t$)、舒适度如何($\hat{r}_t$),然后把这个模拟一次性反向传播来优化你的着装策略。梯度穿过每一个时间步的天气模型——如果天气预报在某个时刻不准,这个误差会向前后两个方向传播(正向影响后续状态、反向扭曲梯度)。策略梯度则相当于你做了 $N$ 次独立的模拟行程,每次记录"做了选择 X 之后感觉如何"——不深究为什么,只看结果——然后根据统计调整策略。前者用模型的结构信息(可微性)换取计算效率——但代价是对模型误差的敏感性放大。
关键要点
- 两条梯度通路:策略梯度(不穿过模型,高方差低偏置)vs 反向传播梯度(穿过模型,低方差高偏置风险)
- 反向传播的梯度连乘 $\prod J_f$ 导致梯度消失/爆炸——与 RNN 训练中的问题同构
- PIPP (Parmas et al. 2018):模型误差通过 Jacobian 连乘被放大 = "混沌诅咒"
- 实践中的选择取决于模型精度、视界长度、可用样本量——没有普适的最优方案
→ Slide 17 展示了两种梯度通路的结构性差异,但 Slide 18-19 揭示了一个更根本的问题:无论哪种梯度,当模型 rollout 太长时,误差本身就会将一切淹没。
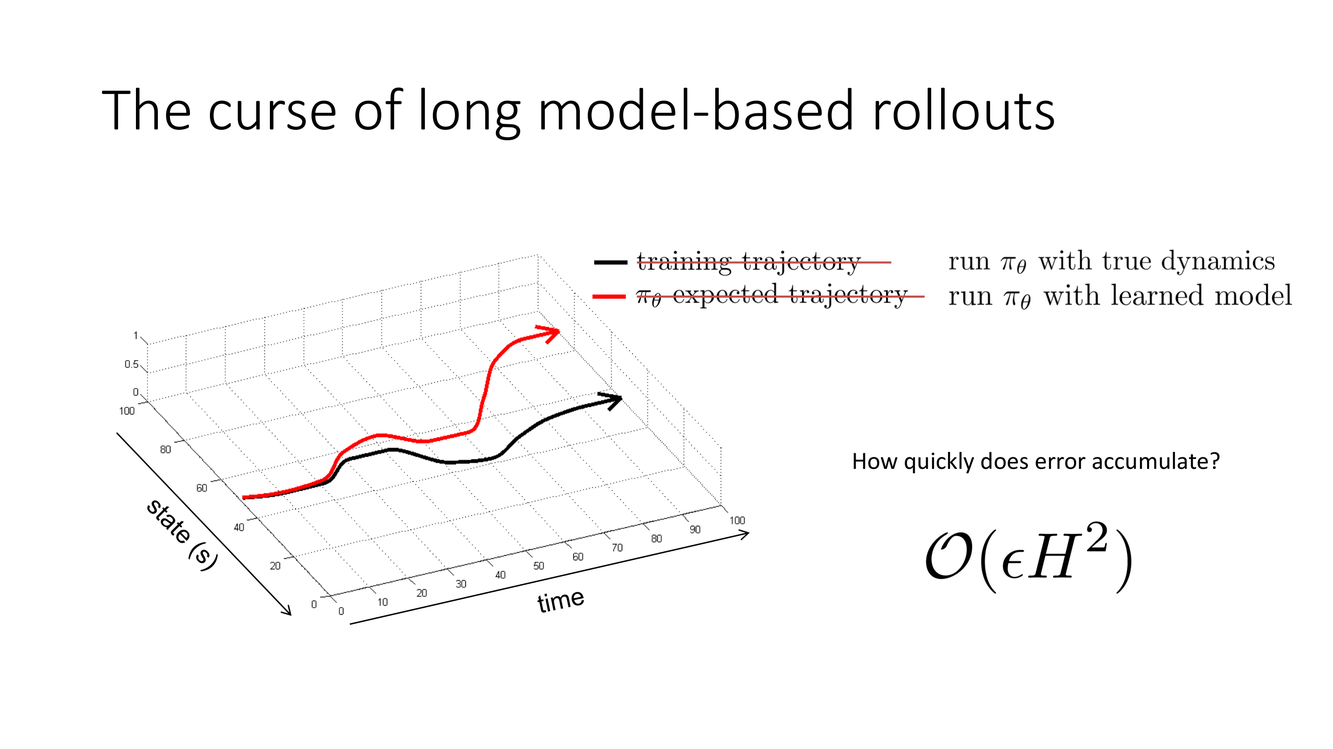
长 Rollout 的诅咒与短 Rollout 的救赎
概念详解
Slide 18 抛出了一个直击要害的问题:"Model-based RL via policy gradient——这种方法可能出什么问题?"答案在 Slide 19 展开:误差随 rollout 长度累积。每一步,学到的动力学模型 $\hat{f}_\phi$ 的预测误差 $\epsilon_t = s_t^{\text{true}} - \hat{s}_t$ 不仅影响当步——它被馈入下一步的输入,使得下一步的预测在已经偏离的起点上进行。这种误差的复合(compounding errors)意味着第 $H$ 步的预测状态可能与真实状态相差甚远——模型展开的轨迹逐渐"漂移"出真实状态分布。
Slide 19 的图示(尽管我无法看到,但可以从讨论中推断)刻画了预测误差随 rollout 步数增长的趋势——可能是线性增长(偏差累积)或指数增长(在混沌动力学中)。Slide 20 提出了对抗这一诅咒的核心策略:使用短 rollout。
Slide 20 用一张四象限图权衡了长 rollout 和短 rollout 的利弊:
长 rollout(从真实状态开始,展开到 $H$):
+ 能看到后期时间步(覆盖整个 episode 的状态)
- 巨大的累积误差($\approx \epsilon \cdot H^2$ 或更差)
- 永远看不到后期时间步的"真实"状态(完全在模拟中)
短 rollout(从真实 replay buffer 状态开始,展开 $k \ll H$ 步):
+ 低得多的累积误差(只有 $k$ 步的误差累积)
+ 看到所有时间步(因为每次都从 replay buffer 中的真实状态开始)
- 使用的是"错误"的状态分布(模型只负责短延伸,但这些短延伸的起点来自 replay buffer,而非当前策略在真实环境中的实际访问分布)
深度剖析
误差累积的数学本质可以通过分析模型展开的Lipschitz 性质来刻画。设模型误差 $\epsilon$ 为单步预测的期望误差上界,动力学 $\hat{f}_\phi$ 是 $L$-Lipschitz 的($\|\hat{f}_\phi(s) - \hat{f}_\phi(s')\| \leq L\|s - s'\|$)。在确定性动力学中,$k$ 步后的状态误差界限为:
$$\|\hat{s}_k - s_k^{\text{true}}\| \leq \epsilon \cdot \frac{L^k - 1}{L - 1} \quad (\text{当 } L \neq 1)$$或 $\epsilon \cdot k$(当 $L = 1$)。$L > 1$(混沌/发散动力学)时误差呈指数增长(最坏情况);$L < 1$(收缩动力学)时误差有界(好情况);$L = 1$(边际稳定)时误差线性增长。在实际的神经网络动力学中,$L$ 难以先验估计,但经验观察通常发现误差增长介于线性和超线性之间。
短 rollout 的核心洞察是截断误差传播链:每 $k$ 步后就用真实状态"重置"——即将模型展开的起点拉回真实状态分布。Slide 21 图示了这一过程:每次从真实环境数据 $\mathcal{D}$ 中采样一个初始状态,展开 $k$ 步模型预测,然后结束——不对模型展开中产生的状态做进一步展开。这相当于用真实状态作为"锚点"来防止模型漂移。
但短 rollout 也有其代价:模型展开的起点来自 replay buffer 的分布,而非当前策略 $\pi_\theta$ 的真实访问分布。这意味着短 rollout 产生的数据是有偏的(来自旧分布),但低误差的(因为只走了 $k$ 步)。这是一个偏置-方差的经典权衡——只不过这里的"方差"是模型误差累积的方差,"偏置"是状态分布不匹配的偏置。
实例与类比
长 rollout 像接力传话游戏——第一个人对第二个人耳语一句话,第二个人把自己听到的版本传给第三个人,如此传递 30 轮。到第 30 个人时,那句话已经从"明天下午三点在图书馆见面"变成了"昨天有人在花园唱歌"。每一步的微小误差(听错一个词、添油加醋)被复合放大。短 rollout 相当于每传 3 轮就回到原始发话者那里拿回原始句子重新开始——这样每段只累积 3 轮的误差,但代价是只探索了原始发话者的"邻近表达",而不是整个传话链的长时间演化。在 model-based RL 中,原始发话者就是 replay buffer 中的真实经验——可靠的锚点,但不足以覆盖策略在整个 episode 中可能访问的所有状态分布。
关键要点
- 模型误差随 rollout 步数复合增长:$\|\hat{s}_k - s_k^{\text{true}}\| \approx \epsilon \cdot \frac{L^k - 1}{L - 1}$
- 短 rollout($k$ 步后重置为真实状态)截断误差传播链——以分布偏置换取低误差
- 长 rollout 看到更多但误差更大;短 rollout 更准确但依赖 replay buffer 的旧分布
- 核心权衡:模型误差累积 vs 状态分布不匹配——$k$ 是控制这个权衡的关键超参数
→ 短 rollout 是框架性的方案,但它需要与具体的算法骨架结合才能落地。Slide 22-25 展示了从 Sutton 的 Dyna 到现代 MBA/MVE/MBPO 的完整算法演进。
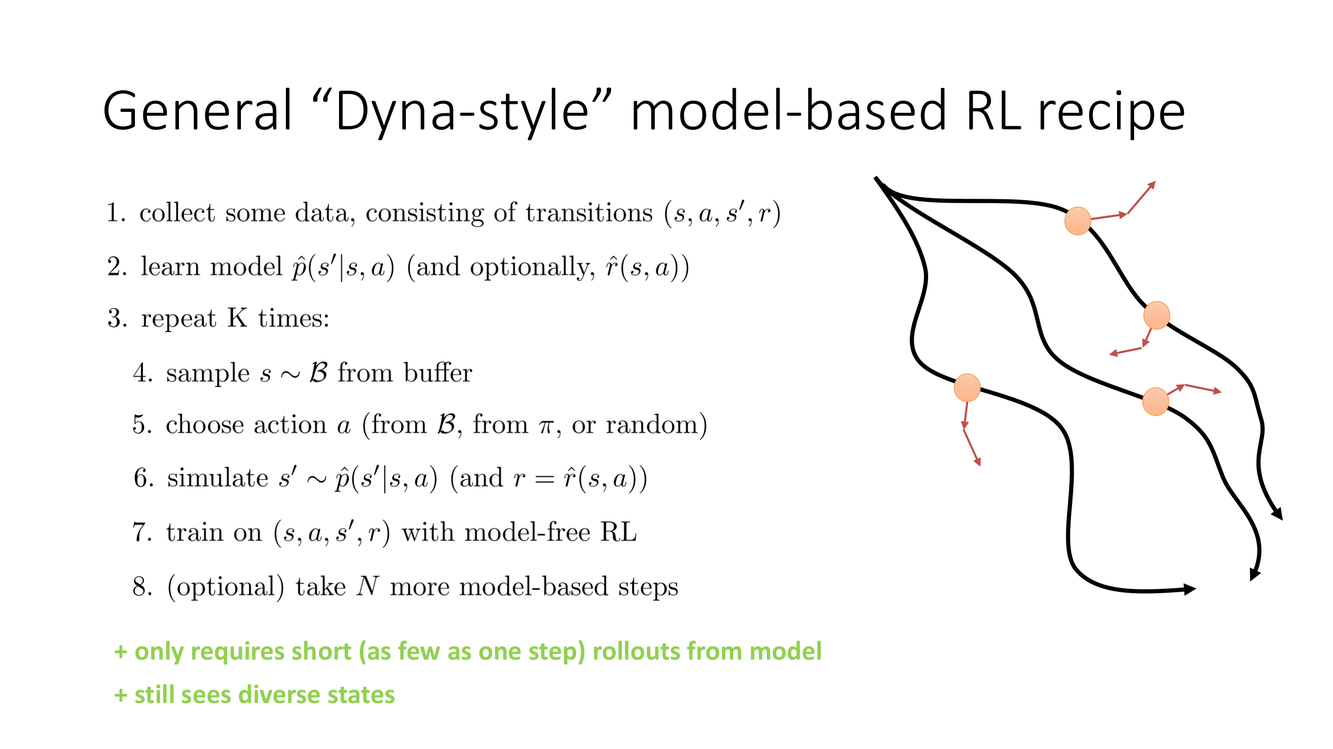
Dyna 式模型加速与 MBA/MVE/MBPO 谱系
概念详解
Slide 22 致敬了 model-based RL 的经典起源:Richard S. Sutton 的 Dyna 架构("Integrated architectures for learning, planning, and reacting based on approximating dynamic programming")。Dyna 的核心思想是将学到的模型无缝嵌入 model-free 算法的数据流:在真实环境中收集的 transition $(s, a, r, s')$ 既用于直接更新 Q 函数(model-free 路径),也用于训练环境模型;环境模型随后生成额外的模拟 transitions——这些"想象中的经验"与真实经验混合在一起,共同用于 Q 函数更新。这是一个优雅的统一——model-free 和 model-based 不是二选一,而是一个连续谱上的互补成分。
Slide 23 将 Dyna 的思想提炼为通用的"Dyna 式 model-based RL 配方":
- 从真实环境中收集数据,存入 replay buffer $\mathcal{D}_{\text{real}}$
- 使用 $\mathcal{D}_{\text{real}}$ 训练动力学模型 $\hat{p}_\phi$
- 从 $\mathcal{D}_{\text{real}}$ 中随机采样真实状态 $s$,在模型 $\hat{p}_\phi$ 中展开 $k$ 步($k$ 可以小到 1)
- 将模型生成的 transitions $(s, a, \hat{r}, \hat{s}')$ 存入一个模型缓冲区 $\mathcal{D}_{\text{model}}$
- 从 $\mathcal{D}_{\text{real}} \cup \mathcal{D}_{\text{model}}$ 中采样进行 model-free 更新(策略梯度或 Q-learning)
Slide 24 展示了这一配方在离线 RL(off-policy RL)架构中的具体实现。真实 transitions 从环境流入 replay buffer;模型从 replay buffer 中学习并生成模型 transitions;两个来源的数据混合后用于 Q 函数或策略的更新。关键是:值函数和策略的更新算法完全不变——模型只负责生成额外的"增强"数据。
Slide 25 呈现了沿这一谱系的三个标志性算法,按模型使用的深度递增排列:
MBA — Model-Based Acceleration(Gu et al. 2016):使用学到的模型从真实状态出发展开多步,生成额外的"想象"数据来加速 Q-learning。这是 Dyna 的直接神经化实现——模型作为数据增强器。
MVE — Model-Based Value Expansion(Feinberg et al. 2018):不生成额外的训练数据,而是用模型展开来改进值估计的准确性。对每个真实 transition 的 target value,不只用单步 TD 目标 $r + \gamma V(s')$,而是展开模型 $k$ 步:
$$\hat{V}_{\text{MVE}}(s) = \sum_{t=0}^{k-1} \gamma^t \hat{r}_t + \gamma^k V(\hat{s}_k)$$将单步 TD 扩展为 $k$ 步模型辅助的 $k$-步回报——在不增加模型误差过多的前提下降低值估计的偏置。
MBPO — Model-Based Policy Optimization(Janner et al. 2019):系统性地回答了"模型展开多长"这一问题。MBPO 的核心理论贡献是提出了模型使用的分支长度与误差累积之间的定量权衡:在每个模型分支中,模型展开的步数 $k$ 应随模型精度的提高而增加,随模型对策略分布偏移的敏感度提高而减少。Slide 25 展示了为什么 MBPO 同时具有"好理由"(+)和"坏理由"(-)——好理由是它理论上严谨、实践中有效;坏理由是分支长度 $k$ 的选择仍依赖于对模型质量的经验判断。
深度剖析
Dyna 的优雅性源于它将一个看似二分的问题(model-free vs model-based)还原为一个数据源混合的连续参数化。在极限情况下,$\mathcal{D}_{\text{model}}$ 占比为 0 → 纯粹 model-free;$\mathcal{D}_{\text{model}}$ 占比接近 1 → 近乎纯粹 model-based(在学到的模型中做 model-free RL)。Dyna 式方法的强项在于:
- 只需要极短的模型 rollout($k$ 可以小到 1),因为真实数据和模型数据是混合的——每一步模型生成的 transition 都可以在下一步与真实 transition 交替使用。
- 仍然看到多样化的状态(来自 replay buffer 的历史真实状态),避免了长 rollout 导致的模型分布崩溃。
MVE 的价值展开公式的偏置-方差权衡可以这样分析:$k=1$ 时 $\hat{V}_{\text{MVE}}$ 退化为普通的单步 TD(低模型误差、高值估计偏置);$k \to \infty$ 时 $\hat{V}_{\text{MVE}}$ 趋近于模型全展开的蒙特卡洛估计(高模型误差、低值估计偏置)。最优的 $k$ 在两者之间的某个中间点——取决于模型在每个状态区域的局部精度。
MBPO 的理论框架将这一直觉形式化:设模型误差界限为 $\epsilon_m$,策略分布偏移度量(如 Wasserstein 距离或 TV 距离)为 $\epsilon_\pi$,分支长度 $k$ 的误差传播为 $\mathcal{O}(\epsilon_m \cdot k^2)$(在 Lipschitz 动力学中)。MBPO 的核心不等式给出了在给定模型质量和策略偏移下安全可用的 $k$ 的上界:$k \leq \frac{\log(1/\epsilon_\pi)}{\log(1/\epsilon_m)}$ 或其等价形式。
实例与类比
Dyna 的"真实数据 + 想象数据混合"可以用学外语的"真实对话 + 自言自语"来类比。真实对话(环境交互)提供高质量但昂贵的语言输入——你可以感受到真正的交流压力、不可预测的回应和自然的纠错。自言自语(模型想象)便宜且无限量——你可以在任何时间想象一段对话并练习回应。Dyna 的精髓在于:不要只用真实对话来学习,也不要只靠自言自语——将两者混合:真实对话定义了"什么是对的",自说自话提供了廉价的大量练习量。MBA 相当于每次真实对话后额外做 10 分钟的自说自话练习(额外的模型 transitions);MVE 相当于每次真实对话后,不只评价自己说的那句话好不好(单步 TD),而是想象"如果当时我换一种说法,接下来 3 个回合会怎么样"(模型辅助的 $k$-步回报)——一种更结构化的自我评估。
关键要点
- Dyna = 真实数据 + 模型数据混合 → model-free 更新算法不变
- MBA(Gu 2016)= Dyna 的神经实现:模型生成额外 transitions
- MVE(Feinberg 2018)= 用模型展开改进 TD 目标的质量($k$-步值扩展)
- MBPO(Janner 2019)= 系统性地分析分支长度 $k$ 与模型误差的权衡
- 短 rollout($k$ 小)+ 真实数据锚定 = 整个 Dyna 式谱系的共同基因
→ 第2章建立了从"用模型规划"到"用模型辅助策略学习"的完整过渡。第3章将翻开 model-based RL 中更现代的一页:模型可以不作用在原始观测空间——它可以作用在一个学到的潜空间中。
第3章:模型的表示(Representing the Model)
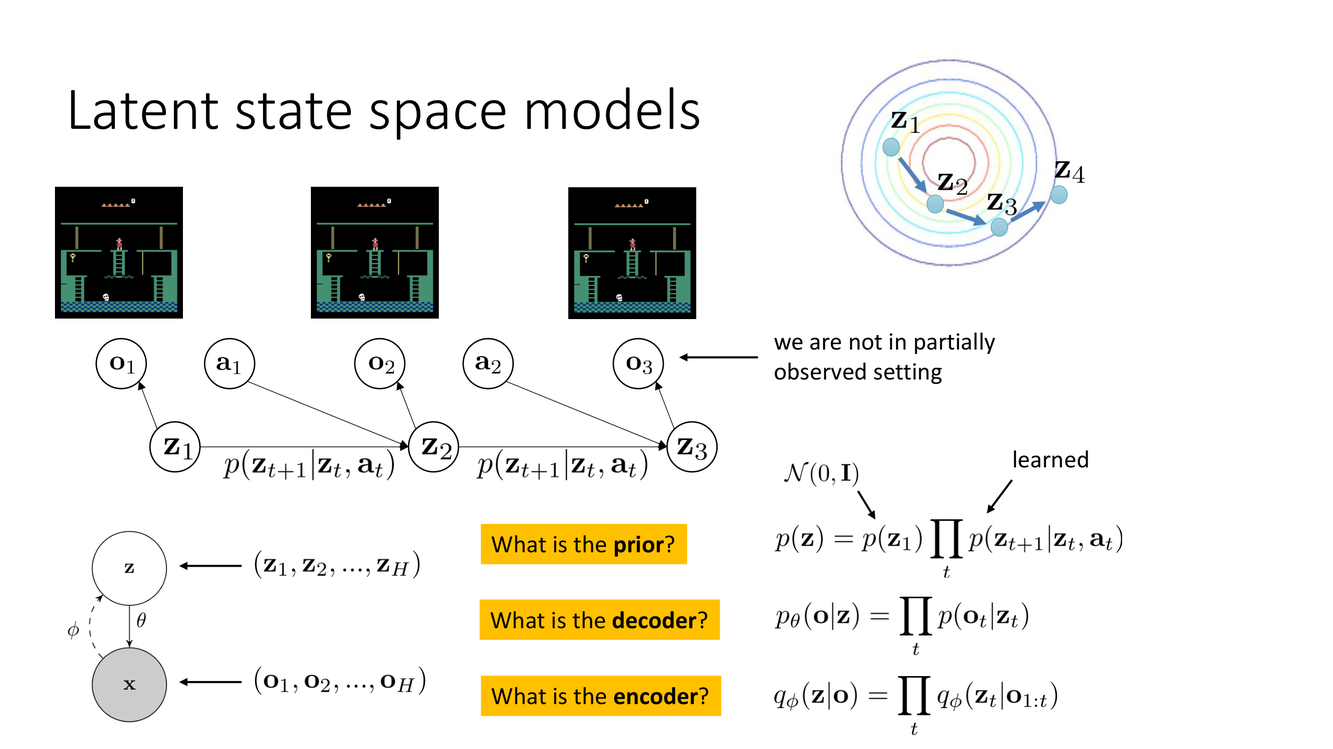
潜空间状态模型:为什么、是什么、怎么训练
概念详解
Slide 26 以一个幽默的"幕间休息"作为第2章与第3章的过渡,然后 Slide 27-28 提出了第3章的核心问题:模型应该作用在什么表示空间上?
迄今为止的讨论假设模型直接作用在原始观测空间上——如 $s_{t+1} = \hat{f}_\phi(s_t, a_t)$,其中 $s_t$ 是像素、关节角等原始传感器读数。但 Slide 29 提出了一个更深刻的替代:潜空间状态模型(Latent State Space Models)。在这一框架中,环境的状态不是直接观测的——我们观测到的是状态的噪声投影 $o_t$(observation),而真正的动力学作用在一个低维的潜状态 $z_t$ 上:
$$p(o_t | z_t) \quad \text{— 观测模型(decoder)}$$ $$p(z_{t+1} | z_t, a_t) \quad \text{— 潜动力学模型}$$ $$p(r_t | z_t, a_t) \quad \text{— 奖励模型}$$Slide 29 通过三个关键问题揭示了这一框架的设计空间:"先验 $p(z_1)$ 是什么?""解码器 $p(o_t|z_t)$ 是什么?""编码器 $q(z_t|o_t)$(或更一般的 $q(z_t|o_{\leq t})$)是什么?"——这三个问题的答案定义了不同的潜空间模型变体。
Slide 30 进一步明确了编码器的结构性选择:编码器本质上是一个序列模型——它将观测序列映射到潜状态序列。这个序列模型的架构可以是 LSTM、Transformer 或其他任何序列编码器。编码器的输出是潜状态的后验分布 $q(z_t|o_{1:t}, a_{1:t-1})$(滤波后验)或 $q(z_t|o_{1:T}, a_{1:T-1})$(平滑后验)。
Slide 31 将潜空间模型与标准(完全观测)模型做了对比。标准模型:
$$\text{maximize} \quad \frac{1}{N}\sum_i \sum_t \log p_\phi(s_{t+1}^i | s_t^i, a_t^i) \quad \text{— 观测到状态,直接极大似然}$$潜空间模型:
$$\text{maximize} \quad \mathbb{E}_{q(z_t|o_{\leq t})} \left[ \log p(o_t|z_t) + \log p(z_{t+1}|z_t, a_t) + \log p(r_t|z_t, a_t) \right] - D_{\text{KL}}(q \| p_{\text{prior}})$$后一项是 KL 正则化项——它鼓励编码器输出的后验分布不要偏离先验太远,从而使潜空间更规整、更可预测。这是变分推断(variational inference)在序列模型中的标准应用。
深度剖析
为什么需要潜空间?根本原因是对高维观测(如图像)建模时,观测空间中的动力学是冗余的、高维的、且充满了与决策无关的细节。一个机器人推桌上方块的图像($256 \times 256 \times 3 = 196,608$ 维)只有少数几个物理自由度(方块的位置、朝向、速度——也许 12 维)。在 196,608 维的空间中建模 $\hat{f}_\phi: \mathbb{R}^{196608} \times \mathbb{R}^{d_a} \to \mathbb{R}^{196608}$ 不仅是极低效的,而且由于维度的膨胀,模型更容易在无关的像素纹理上过拟合。
潜空间模型通过在低维潜空间中建模动力学($z_t \in \mathbb{R}^{d_z}$,$d_z \ll \dim(o_t)$)来绕过维度灾难——模型只需要捕捉与决策相关的信息。但这也引入了一个新的难题:表示学习(representation learning)必须与动力学学习同时进行——潜状态 $z_t$ 的"好坏"取决于它是否既能被编码器可靠地提取,又能支持准确的动力学预测和奖励预测。
滤波后验 vs 平滑后验是潜空间模型设计中的关键岔路。单步编码器 $q(z_t|o_t)$(滤波近似)最简单——只看当前帧就猜测潜状态——但可能因部分可观测性而导致信息丢失(一个单帧图像无法区分静态和运动的物体)。全平滑后验 $q(z_t|o_{1:T})$ 使用整个序列的观测来推断每个时刻的潜状态——最准确但也最复杂(需要前向-后向推断)。实践中,许多方法使用滤波后验($q(z_t|o_{\leq t})$,通过 RNN 隐状态 $h_t$ 递推地编码历史)作为折中。
实例与类比
潜空间模型可以用作曲家读总谱 vs 听录音来类比。原始观测空间(像素)像是一段交响乐的录音——每秒 44,100 个采样点,充满了信息,但真正的音乐"状态"(旋律、和声、节奏、力度)只占其中的一小部分。在录音波形上直接预测"下一时刻的波形"(原始观测空间中的动力学)是笨拙且不稳定的。潜空间模型相当于先将录音转录为一个乐谱表示(潜状态 $z_t$)——音符、节拍、强弱记号——乐谱是音乐的一个低维、结构化的"潜表示"——然后在乐谱空间中预测下一小节的音符(潜动力学),最后再合成回音频(解码器 $p(o_t|z_t)$)。编码器 $q(z_t|o_t)$ 是"听写员"——它"听"到声音并推测乐谱——它可能要靠几小节的上下文才能准确识别一个模糊的和弦(这就是为什么全平滑后验比单步编码器更准确)。
关键要点
- 潜空间模型的三个组件:编码器(观测→潜状态)、潜动力学($z_t \to z_{t+1}$)、解码器(潜状态→观测/奖励)
- 训练目标 = 重构损失 + 动力学预测损失 + 奖励预测损失 - KL 正则化
- 完全观测模型 vs 潜空间模型的核心分歧:作用在原始空间还是学到的低维表示上
- 编码器的选择(单步/滤波/平滑)决定了信息捕获能力与计算复杂度的基本权衡
→ 潜空间框架提供了三个强大的"旋钮"——编码器、动力学、解码器。Slide 32-35 将聚焦于最关键的旋钮:编码器的选择和训练范式。

编码器的谱系与潜空间 Rollout 训练范式
概念详解
Slide 32 将编码器的选择刻画为一个精度-复杂度谱系:
全平滑后验(Full Smoothing Posterior) $q(z_t|o_{1:T}, a_{1:T-1})$:使用完整序列(包括未来观测)来推断每个时刻的潜状态。这利用了所有的可用信息——包括"回头看"已发生的事情来修正对过去的理解——在部分可观测环境中尤其关键。+ 最准确 | - 最复杂(需要双向推断,不能在线执行)。
单步编码器(Single-Step Encoder) $q(z_t|o_t)$:仅使用当前帧来推断潜状态。结构最简单,可以在线执行。+ 最简单 | - 最不准确(单帧信息量可能不足以推断完整状态)。
Slide 33 专门讨论了确定性编码器:$z_t = e_\psi(o_t)$(一个确定性的映射,而非概率分布)。"为什么这种编码器可能不好?"——确定性编码器将所有的观测噪声直接注入潜状态,使潜状态成为一个"污染的"表示。如果 $o_t$ 中有偶然噪声(如传感器噪声、光照扰动),确定性编码器会将这些噪声嵌入潜状态——而动力学模型随后需要在有噪声的潜状态上做预测——增加了模型的不必要负担。随机编码器通过 $q(z_t|o_t) = \mathcal{N}(\mu_\psi(o_t), \sigma_\psi^2(o_t))$ 的形式为每个潜状态给出一个分布,允许模型表达"我不太确定这个帧的潜状态"的不确定性——这与第15讲关于偶然 vs 认知不确定性的讨论形成完美的前后呼应。
Slide 34 展示了实践中常用的架构:潜空间动力学(通常是 RNN 或 Transformer)、图像重构(解码器)、奖励预测——三者联合训练。许多实用方法使用随机编码器或更复杂的平滑后验。Slide 35 给出了训练循环的视觉化:从 replay buffer 采样轨迹 → 运行编码器获得 $z_t$ → 在潜空间中展开动力学几步 → 计算重构损失与奖励预测损失 → 反传更新。
深度剖析
确定性与随机编码器的分歧触及了一个更深层的问题:表示学习中的信息瓶颈(Information Bottleneck)。一个好的潜表示 $z_t$ 应该保留观测中对预测和控制有用的信息,同时丢弃无关的像素细节和传感器噪声。随机编码器天然地为这种信息选择提供了一个机制:$\sigma_\psi^2(o_t)$ 大的维度(高不确定性)可以理解为"这一维度可能被噪声主导"——这些维度在后续的动力学预测中自然地被"低估"。KL 正则化项 $D_{\text{KL}}(q(z_t|o_t) \| p(z_t))$ 进一步施压——它鼓励 $z_t$ 的后验不要偏离先验(通常是 $\mathcal{N}(0, I)$)太远,从而防止编码器将"全部信息"(包括噪声)塞入潜状态。
全平滑后验的实际挑战是计算性的:在训练时,我们可以使用双向 RNN 或 Transformer 来近似平滑后验(因为训练时整个轨迹已知);但在部署时(在线执行),智能体只能访问过去和现在的观测——它不能"看到未来"。这导致了训练-部署的后验不匹配。解决方案通常是训练一个滤波后验(仅使用过去和现在),或使用 teacher forcing 在训练时用真实观测作为输入,部署时用模型预测。
潜空间 rollout 的一个精妙之处是潜空间中的想象不再需要解码为原始像素——奖励可以直接在潜空间中预测,策略(或 Q 函数)也可以直接在潜空间上操作。这意味着潜空间的"好坏"是由其在下游任务上的表现定义的——不是由像素重构的保真度(如 PSNR)来评价——这是一个重要的设计原则:面向控制的表示学习。
实例与类比
确定性编码器 vs 随机编码器的区别可以用目击证人做笔录来理解。确定性编码器要求证人给出一个"确切的"描述:"肇事车辆是深蓝色轿车,车牌号京A12345"。如果证人的观察本身有误差(天色昏暗、车辆快速经过),错误的描述就被固定为"事实"——后续的所有推理在错误的事实上进行。随机编码器允许证人说:"肇事车辆可能是深蓝或黑色轿车(70% 置信),车牌号可能是京A12345 或京A12346(60% 置信)"——这种不确定性被保留在表示中,后续的推理可以据此做出更稳健的判断(比如不排除两种颜色的可能性)。KL 正则化项则好比是告诉证人:"除非你非常确定,否则尽量保持描述简洁"——防止证人把"可能是轿车"扩展为一段关于车轮、车灯、后视镜的冗长描述(这些细节可能全是靠想象填补的)。
关键要点
- 编码器谱系:全平滑(最准/最慢)→ 滤波(折中)→ 单步(最快/最不准)
- 确定性编码器将观测噪声注入潜状态 → 污染动力学;随机编码器保留不确定性
- 在实际部署中通常使用滤波后验(可在线执行)配合 teacher forcing 训练
- 潜空间的质量由下游控制任务定义,而非像素重构保真度
→ 编码器选择与训练范式的讨论为最终的架构做了铺垫。Slide 36-38 将展示如何将潜空间模型与 actor-critic 结合——以及这一融合在实际应用中的表现。
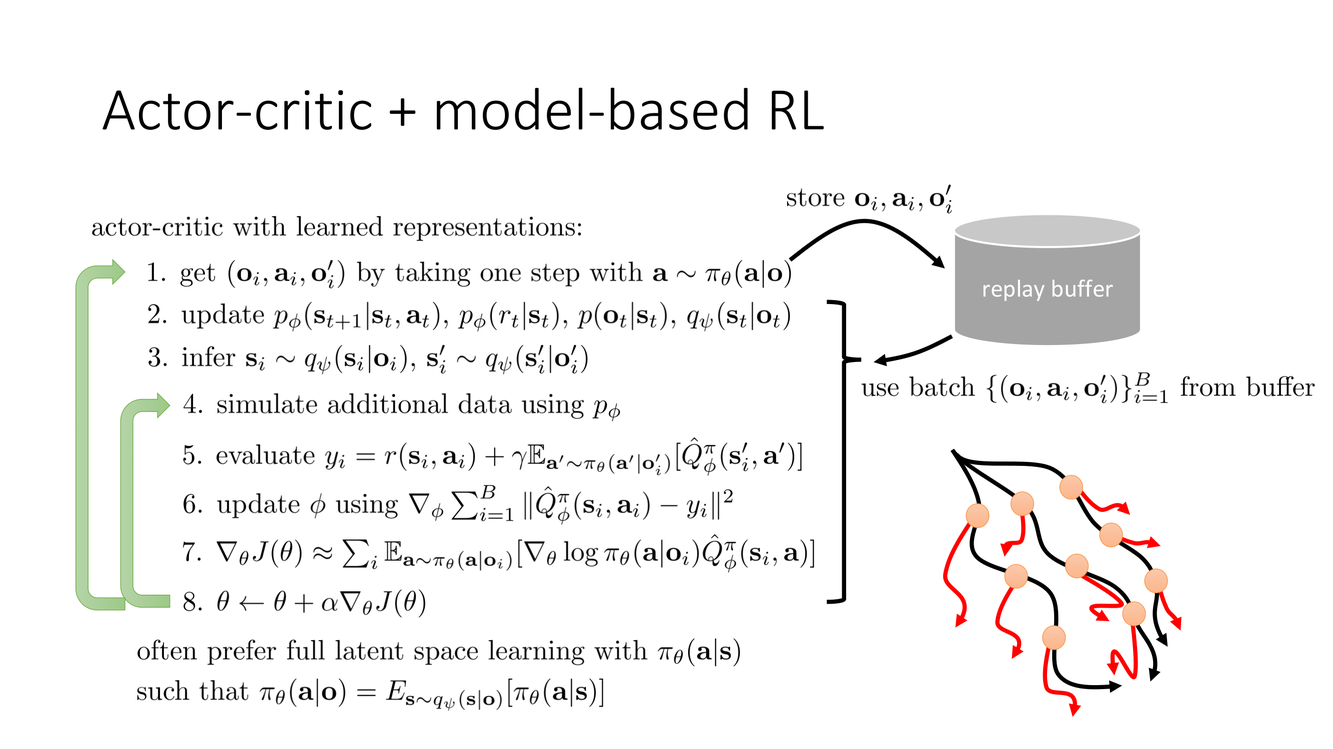
Actor-Critic 与 Model-Based RL 的深度融合
概念详解
Slide 36 提出了一个将 actor-critic 架构天然地推广到 model-based 设置的设计:Actor-Critic with Learned Representations。在这一框架中,replay buffer 中的观测首先通过编码器映射到潜状态 $z_t$;actor $\pi_\theta(a_t|z_t)$ 和 critic $Q_\phi(z_t, a_t)$ 都操作在潜空间上——不需要看到像素。模型在这个架构中扮演了双重角色:一方面提供潜状态的动力学预测,另一方面生成用于 actor-critic 训练的想象数据。
Slide 36 提出了一个有趣的追问:"为什么我们可能想要一个全滤波/平滑后验?"——更好的后验意味着更有信息量的潜状态,进而 actor 和 critic 在一个更干净、更完整的表示上做决策。但全平滑后验的成本是高昂的(不能在线执行、训练更复杂)。"为什么可能偏好全滤波/平滑后验?"——答案在于信息保留:在部分可观测场景中,当前帧可能缺失了关键信息(如物体的速度、被遮挡的物体),而这些信息在历史帧中可以推断——更完整的后验 ="更完整的状态"= 更好的决策。
Slide 37 展示了这一融合架构的完整信息流:真实 transitions 流入 replay buffer → 被采样用于训练编码器、动力学、actor、critic → 模型生成想象 transitions 加入 replay buffer → 闭环循环。这是一个端到端的表示-模型-策略联合学习架构。
Slide 38 以直观的对比作为第16讲的视觉化收尾:真实 rollouts(真实环境中的轨迹)vs 模型"想象"的 rollouts(潜空间模型生成的轨迹)。"Representation learning and model-based RL"的核心信息在这一视觉对比中凝聚:学到的潜表示使得模型可以在低维语义空间中想象未来——而不是逐像素地渲染整个未来世界。
深度剖析
Actor-critic + model-based RL 的融合代表了一种更深层的设计哲学——有时被称为"想象力增强的强化学习"(imagination-augmented RL)。其核心操作模式可分解为以下三个嵌套循环:
外循环(真实交互):策略 $\pi_\theta$ 在真实环境中执行,收集数据存入 $\mathcal{D}_{\text{real}}$。频率由环境交互的代价决定。
中循环(模型训练):编码器、潜动力学、解码器(观测和奖励)在 $\mathcal{D}_{\text{real}}$ 上联合训练——最小化重构误差 + 动力学预测误差 + 奖励预测误差 + KL 正则化。
内循环(想象与策略更新):使用当前模型在潜空间中展开多条想象轨迹;actor 和 critic 在<$真实潜状态 + 想象潜状态$>上更新。这是 Dyna 式更新在潜空间版本中的实现。
这种三层嵌套结构带来的一个微妙优势是想象可以为策略发现提供多样性。由于潜空间中展开轨迹的计算成本远低于真实环境,策略可以在大量"假设"场景中进行训练——包括那些在真实环境中可能罕见但重要的临界场景——从而提升鲁棒性。
架构演进的时间线勾勒出这一方向的快速进展:从World Models(Ha & Schmidhuber 2018)在潜空间中训练控制器 → PlaNet(Hafner et al. 2019)在潜空间中进行纯规划 → Dreamer(Hafner et al. 2020)学习潜空间中的 actor-critic → DreamerV2/V3 引入离散潜变量和世界模型缩放。本讲的内容为理解 Dreamer 系列提供了必须的概念框架。
实例与类比
Actor-critic + model-based RL 的结构可以类比为棋手的思维架构。编码器相当于棋手看棋盘时将棋子的位置布局转化为一个内部的"局面理解"($z_t$)——不仅记录每个子在哪儿,更包括"中心控制力""王的安全""兵形"等抽象特征。潜动力学相当于棋手在心里走棋("如果我走马到 e5,对方可能会用车吃……")——他不需要在脑中逐像素渲染棋盘的样子,而是在抽象的局面表示中推演。Actor 是在给定局面理解下建议走法的部分("我认为应该走象到 b4"),Critic 是评价局面好坏的部分("这个局面我略微占优")。整个认知过程在内部表示空间中循环——外部世界只提供真实的棋局观测(replay buffer),内部分析和想象都在潜空间中展开——这与 actor-critic + model-based RL 的嵌套循环如出一辙。
关键要点
- Actor-Critic + 潜空间模型 = 三个嵌套循环(真实交互 / 模型训练 / 想象 + 策略更新)
- 编码器质量直接影响 actor 和 critic 的决策质量——表示学习是瓶颈
- 全平滑后验提供更完整的状态但不可在线执行;实践中使用滤波后验的折中方案
- 学到的潜表示使得模型可以"在语义空间中想象"——这是 model-based RL 可扩展性的关键
- 第16讲的完整叙事弧:规划 → 策略学习 → 表示学习——model-based RL 的三大支柱统一在潜空间框架之下